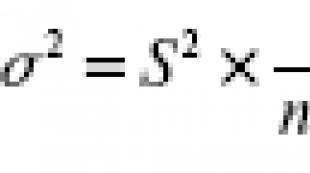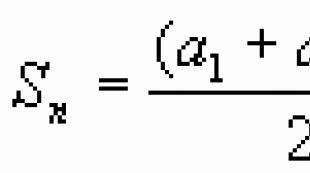Téma seminára: vzorkovanie v sociologickom výskume Kľúčové pojmy. Reprezentatívna vzorka Vzorka a všeobecná populácia
Štatistický výskum je veľmi namáhavý a nákladný, preto vznikla myšlienka nahradiť kontinuálne pozorovanie selektívnym.
Hlavným účelom diskontinuálneho pozorovania je získať charakteristiky skúmanej štatistickej populácie pre skúmanú jej časť.
Selektívne pozorovanie- Ide o metódu štatistického výskumu, pri ktorej sa zovšeobecnené ukazovatele obyvateľstva stanovujú iba pre samostatnú časť na základe ustanovení o náhodnom výbere.
Pri metóde vzorkovania sa študuje iba určitá časť skúmanej populácie, zatiaľ čo štatistická populácia, ktorá sa má skúmať, sa nazýva všeobecná populácia.
Populačnú vzorku alebo jednoducho vzorku možno nazvať časťou jednotiek vybraných z bežnej populácie, ktoré budú podrobené štatistickému výskumu.
Hodnota metódy výberu vzorky: s minimálnym počtom skúmaných jednotiek sa štatistická štúdia vykoná v kratších časových obdobiach a s najmenšími nákladmi na finančné prostriedky a prácu.
V bežnej populácii sa podiel jednotiek, ktoré majú študovaný znak, nazýva všeobecný podiel (označený R), a priemerná hodnota študovanej premennej charakteristiky je všeobecný priemer (označený NS).
V populácii vzorky sa podiel sledovaného znaku nazýva podiel na vzorke alebo časť (označená w), priemerná hodnota vo vzorke je priemer vzorky.
Ak sú počas obdobia prieskumu dodržané všetky pravidlá jeho vedeckej organizácie, potom metóda odberu vzoriek poskytne pomerne presné výsledky, a preto sa odporúča použiť túto metódu na kontrolu údajov o nepretržitom pozorovaní.
Táto metóda sa stala rozšírenou v štátnej a mimorezortnej štatistike, pretože pri štúdiu minimálneho počtu študovaných jednotiek vám umožňuje starostlivo a presne vykonať štúdiu.
Študovaná štatistická populácia pozostáva z jednotiek s rôznymi charakteristikami. Zloženie populácie vzorky sa môže líšiť od zloženia všeobecnej populácie; tento rozpor medzi charakteristikami vzorky a všeobecnou populáciou je chybou výberu.
Chyby vlastné pozorovaniu vzorky charakterizujú veľkosť rozdielu medzi údajmi z pozorovania vzorky a celou populáciou. Chyby vznikajúce pri vzorkovaní sa nazývajú chyby reprezentatívnosti a delia sa na náhodné a systematické.
Ak populácia vzorky nereprodukuje presne celú populáciu kvôli nespojitej povahe pozorovania, potom sa to nazýva náhodné chyby a ich veľkosti sa určujú s dostatočnou presnosťou na základe zákona veľkých čísel a teórie pravdepodobnosti.
Systematické chyby vznikajú v dôsledku porušenia zásady náhodnosti pri výbere jednotiek populácie na pozorovanie.
2. Typy a schémy výberu
Veľkosť chyby vzorkovania a metódy jej určenia závisia od typu a schémy výberu.
Existujú štyri typy výberu pre skupinu pozorovacích jednotiek:
1) náhodný;
2) mechanické;
3) typické;
4) sériový (vnorený).
Náhodné vzorkovanie- najbežnejší spôsob výberu v náhodnej vzorke, nazýva sa aj metóda žrebovania, pri ktorej je pre každú jednotku štatistickej populácie pripravený lístok so sériovým číslom.
Ďalej sa náhodne vyberie požadovaný počet jednotiek štatistickej populácie. Za týchto podmienok má každý z nich rovnakú pravdepodobnosť zaradenia do vzorky, napríklad žrebovania výhier, keď sa z celkového počtu vydaných tiketov náhodne vyberie určitá časť čísel, na ktoré výhry spadajú. Zároveň sa všetkým číslam poskytuje rovnaká príležitosť dostať sa do vzorky.
Mechanický výber- je to metóda, keď je celá populácia rozdelená do skupín homogénneho objemu podľa náhodného kritéria, potom je z každej skupiny odobratá iba jedna jednotka. Všetky jednotky študovanej štatistickej populácie sú predbežne usporiadané v určitom poradí, ale v závislosti od veľkosť vzorky, požadovaný počet jednotiek sa mechanicky vyberie v určitom intervale ...
Typický výber - Ide o metódu, pri ktorej je študovaná štatistická populácia rozdelená podľa významného, typického znaku na kvalitatívne homogénne, podobné skupiny, potom sa z každej z tejto skupiny náhodne vyberie určitý počet jednotiek, úmerný špecifickej hmotnosti skupiny v celú populáciu.
Typický výber poskytuje presnejšie výsledky, pretože obsahuje zástupcov všetkých typických skupín vo vzorke.
Sériový (vnorený) výber. Celé skupiny (série, hniezda), náhodne alebo mechanicky vybrané, sú predmetom výberu. Pre každú takú skupinu a sériu sa vykonáva kontinuálne pozorovanie a výsledky sa prenášajú do celej populácie.
Presnosť vzorkovania závisí aj od schémy výberu. Odber vzoriek sa môže vykonávať podľa schémy opakovaného a neopakujúceho sa odberu vzoriek.
Opakovaný výber. Každá vybraná jednotka alebo séria je vrátená celej populácii a môže byť vrátená do vzorky. Ide o takzvanú schému vrátenej lopty.
Opakovaný výber. Každá skúmaná jednotka sa vyberie a nevráti do súhrnu, takže sa znova nepreskúma. Táto schéma sa nazýva nevrátená lopta.
Neopakujúce sa vzorkovanie poskytuje presnejšie výsledky, pretože pri rovnakej veľkosti vzorky pozorovanie pokrýva väčší počet jednotiek študovanej populácie.
Kombinovaný výber môže prejsť jedným alebo viacerými krokmi. Odber vzoriek sa nazýva jednostupňový, ak sa skúmajú vybrané jednotky populácie.
Vzorka sa nazýva viacstupňová, ak výber populácie prechádza fázami, postupnými fázami a každá etapa, fáza výberu, má svoju vlastnú jednotku výberu.
Viacfázový odber vzoriek - vo všetkých fázach vzorkovania je zachovaná rovnaká vzorkovacia jednotka, ale prebieha niekoľko fáz, fáz výberových zisťovaní, ktoré sa líšia šírkou programu zisťovania a veľkosťou vzorky.
Charakteristiky parametrov všeobecnej populácie a populácie vzorky sú označené nasledujúcimi symbolmi:
N.- objem všeobecnej populácie;
n- veľkosť vzorky;
X- všeobecný priemer;
NS- priemer vzorky;
R.- všeobecný podiel;
w - selektívny podiel;
2 - všeobecný rozptyl (rozptyl prvku v bežnej populácii);
2 - rozptyl vzorky tej istej vlastnosti;
- štandardná odchýlka v bežnej populácii;
? - štandardná odchýlka vo vzorke.
3. Chyby pri vzorkovaní
Každá jednotka pri pozorovaní vzorky by mala mať rovnakú príležitosť ako ostatné, ktoré majú byť vybrané - to je základ samonáhodnej vzorky.
Samonáhodné vzorkovanie - Toto je výber jednotiek z celej všeobecnej populácie losovaním alebo iným podobným spôsobom.
Princíp náhodnosti spočíva v tom, že zaradenie alebo vylúčenie predmetu zo vzorky nemôže byť ovplyvnené iným faktorom než prípadom.
Ukážkový podiel Je pomer počtu jednotiek vo vzorke k počtu jednotiek vo všeobecnej populácii:
Správny náhodný výber v jeho čistej forme je počiatočný medzi všetkými ostatnými druhmi výberu; obsahuje a implementuje základné princípy selektívneho štatistického pozorovania.
Dva hlavné typy zovšeobecňujúcich indikátorov, ktoré sa používajú v metóde vzorkovania, sú priemerná hodnota kvantitatívneho znaku a relatívna hodnota alternatívneho znaku.
Frakcia vzorky (w) alebo konkrétne je určená pomerom počtu jednotiek so študovaným znakom m, k celkovému počtu jednotiek vzorky (n):
Na charakterizáciu spoľahlivosti indikátorov odberu vzoriek sa rozlišujú priemerné a okrajové chyby vzorkovania.
Chyba vzorkovania, tiež nazývaná chyba reprezentatívnosti, je rozdielom medzi zodpovedajúcou vzorkou a všeobecnými charakteristikami:
?x = | x - x |;
?w = | x - p |.
Chyba vzorkovania je inherentná iba pozorovaniam vzorky
Priemer vzorky a podiel vzorky- sú to náhodné premenné, ktoré nadobúdajú rôzne hodnoty v závislosti od jednotiek študovanej štatistickej populácie, ktoré sú zahrnuté do vzorky. Vzorkovacie chyby sú teda tiež náhodné hodnoty a môžu tiež nadobúdať rôzne hodnoty. Preto sa stanoví priemer možných chýb - priemerná chyba vzorkovania.
Priemerná chyba vzorkovania je určená veľkosťou vzorky: čím je číslo vyššie, pričom všetky ostatné veci sú rovnaké, tým je hodnota priemernej chyby vzorkovania nižšia. Pokrývajúc narastajúci počet jednotiek všeobecnej populácie výberovým prieskumom, stále presnejšie charakterizujeme celú všeobecnú populáciu.
Priemerná chyba vzorkovania závisí od stupňa variácií študovaného znaku, naopak stupeň variácie je charakterizovaný odchýlkou? 2 alebo w (l - w)- pre alternatívnu funkciu. Čím menšia je odchýlka funkcie a rozptylu, tým menšia je priemerná chyba vzorkovania a naopak.
Pri náhodnom opakovanom vzorkovaní sa priemerné chyby teoreticky vypočítajú podľa nasledujúcich vzorcov:
1) pre priemerný kvantitatívny znak:
kde? 2 - priemerná hodnota rozptylu kvantitatívneho znaku.
2) za podiel (alternatívna funkcia):
Ako je teda variácia znaku v bežnej populácii? 2 nie je presne známy, v praxi používajú hodnotu rozptylu S 2 vypočítanú pre populáciu vzorky na základe zákona veľkých čísel, podľa ktorého populácia vzorky s dostatočne veľkou veľkosťou vzorky reprodukuje charakteristiky všeobecného populácia celkom presne.
Vzorce pre strednú chybu vzorkovania pre náhodné prevzorkovanie sú nasledujúce. Pre priemernú hodnotu kvantitatívneho znaku: všeobecný rozptyl je vyjadrený prostredníctvom voliteľného predmetu takto:
kde S 2 je hodnota rozptylu.
Mechanický odber vzoriek- toto je výber jednotiek do vzorky zo všeobecnej populácie, ktorá je rozdelená do rovnakých skupín podľa neutrálneho kritéria; sa robí tak, že z každej takejto skupiny je vybraná iba jedna jednotka.
Pri mechanickom výbere sú jednotky študovanej štatistickej populácie predbežne usporiadané v určitom poradí, potom sa v určitom intervale mechanicky vyberie určený počet jednotiek. Navyše, veľkosť intervalu vo všeobecnej populácii sa rovná recipročnej hodnote podielu vzorky.
Pri dostatočne veľkej populácii sa mechanický výber z hľadiska presnosti výsledkov blíži samonáhodnosti, a preto sa na stanovenie priemernej chyby mechanického výberu používajú vzorce na samonáhodné neopakovateľné vzorkovanie.
Na výber jednotiek z heterogénnej populácie sa používa takzvaný typický výber vzoriek, používa sa vtedy, keď je možné všetky jednotky všeobecnej populácie rozdeliť do niekoľkých kvalitatívne homogénnych, podobných skupín podľa charakteristík, od ktorých študované ukazovatele závisia.
Potom z každej typickej skupiny sa vykoná individuálny výber jednotiek do populácie vzoriek samonáhodnou alebo mechanickou vzorkou.
Pri štúdiu komplexných štatistických populácií sa zvyčajne používa typický výber vzoriek.
Typické vzorkovanie poskytuje presnejšie výsledky. Typizácia všeobecnej populácie zaisťuje reprezentatívnosť takejto vzorky, zastúpenie každej typologickej skupiny v nej, čo umožňuje vylúčiť vplyv medziskupinového rozptylu na priemernú chybu výberu. Pri určovaní priemernej chyby typickej vzorky sa preto ako ukazovateľ variácií používa priemer vnútroskupinových odchýlok.
Sériový odber vzoriek zahŕňa náhodný výber zo všeobecnej populácie rovnako veľkých skupín, aby sa všetky jednotky podrobili pozorovaniu v týchto skupinách.
Pretože všetky jednotky bez výnimky sú skúmané v rámci skupín (sérií), priemerná chyba vzorkovania (pri výbere rovnako veľkých sérií) závisí iba od rozptylu medzi skupinami (medzisériovými).
4. Spôsoby distribúcie výsledkov vzorky do bežnej populácie
Charakterizácia všeobecnej populácie na základe výsledkov vzoriek je konečným cieľom pozorovania vzorky.
Metóda vzorkovania sa používa na získanie charakteristík všeobecnej populácie pre určité ukazovatele vzorky. V závislosti od cieľov štúdie sa to vykonáva priamym prepočtom vzorkových indexov pre všeobecnú populáciu alebo metódou výpočtu korekčných faktorov.
Metóda priameho prepočtu je, že s ňou ukazovatele podielu vzorky w alebo priemer NS sa vzťahujú na všeobecnú populáciu, pričom sa berie do úvahy chyba vzorkovania.
Metóda korekčných faktorov sa používa vtedy, ak je účelom metódy výberu vzorky objasniť výsledky úplného účtovníctva. Táto metóda sa používa na spresnenie údajov o ročnom sčítaní hospodárskych zvierat medzi obyvateľstvom.
Štatistická populácia- súbor jednotiek s hmotnosťou, typickosťou, kvalitatívnou homogenitou a prítomnosťou variácií.
Štatistická populácia pozostáva z materiálne existujúcich objektov (pracovníci, podniky, krajiny, regióny), je objektom.
Agregačná jednotka- každá konkrétna jednotka štatistickej populácie.
Jedna a tá istá štatistická populácia môže byť v jednom atribúte homogénna a v inom heterogénna.
Kvalitatívna uniformita- podobnosť všetkých jednotiek súhrnu z nejakého dôvodu a nepodobnosť všetkých ostatných.
V štatistickej populácii majú rozdiely medzi jednou jednotkou populácie a druhou často kvantitatívny charakter. Kvantitatívne zmeny hodnôt charakteristík rôznych jednotiek populácie sa nazývajú variácie.
Variácia funkcie- kvantitatívna zmena znaku (pre kvantitatívny znak) počas prechodu z jednej jednotky populácie na druhú.
Podpísať Je to vlastnosť, charakteristický znak alebo iný znak jednotiek, predmetov a javov, ktoré je možné pozorovať alebo merať. Znaky sa delia na kvantitatívne a kvalitatívne. Nazýva sa rozmanitosť a variabilita hodnoty znaku v jednotlivých jednotkách populácie variácia.
Atributívne (kvalitatívne) charakteristiky sa nehodia k číselnému vyjadreniu (zloženie populácie podľa pohlavia). Kvantitatívne charakteristiky sú vyjadrené číselne (zloženie populácie podľa veku).
Register- je to kvantitatívne zhrňujúca kvalitatívna charakteristika akejkoľvek vlastnosti jednotiek alebo súboru ako celku v konkrétnych podmienkach času a miesta.
Výsledková listina Je to súbor ukazovateľov, ktoré komplexne odrážajú študovaný jav.
Plat sa napríklad študuje:- Funkcia - mzdy
- Štatistická populácia - všetci zamestnanci
- Populačná jednotka - každý zamestnanec
- Kvalitatívna homogenita - akumulované mzdy
- Variácia znaku - séria čísel
Celková populácia a ukážka z nej
Základom je súbor údajov získaných ako výsledok merania jednej alebo viacerých vlastností. Skutočne pozorovaný súbor objektov, štatisticky reprezentovaný počtom pozorovaní náhodnej premennej, je vzorkovanie a hypoteticky existujúce (predpokladané) - bežná populácia... Celková populácia môže byť konečná (počet pozorovaní N = konšt) alebo nekonečné ( N = ∞) a vzorka z bežnej populácie je vždy výsledkom obmedzeného počtu pozorovaní. Nazýva sa počet pozorovaní tvoriacich vzorku veľkosť vzorky... Ak je veľkosť vzorky dostatočne veľká ( n → ∞) sa zváži vzorka veľký inak sa tomu hovorí ukážka obmedzený objem... Uvažuje sa o vzorke malý ak pri meraní jednorozmernej náhodnej premennej veľkosť vzorky nepresiahne 30 ( n<= 30 ) a pri meraní niekoľkých ( k) funkcie vo viacrozmernom priestore, pomer n Komu k menej ako 10 (n / k< 10) ... Vzorové formuláre rozsah variácií ak sú jeho členmi radová štatistika tj. vzorové hodnoty náhodnej premennej NS zoradené vzostupne (zoradené), pričom sa nazývajú hodnoty funkcie možnosti.
Príklad... Takmer rovnaký náhodne vybraný súbor objektov - komerčné banky jedného administratívneho obvodu Moskvy, možno považovať za vzorku zo všeobecnej populácie všetkých komerčných bánk v tomto okrese a za vzorku zo všeobecnej populácie všetkých komerčných bánk v Moskve , ako aj vzorka z komerčných bánk krajiny atď.
Základné metódy vzorkovania
Na tom závisí spoľahlivosť štatistických záverov a zmysluplná interpretácia výsledkov reprezentatívnosť odber vzoriek, t.j. úplnosť a primeranosť reprezentácie vlastností všeobecnej populácie, vo vzťahu ku ktorej možno túto vzorku považovať za reprezentatívnu. Štúdium štatistických vlastností populácie môže byť organizované dvoma spôsobmi: pomocou kontinuálne a diskontinuálne. Nepretržité pozorovanie predpokladá prieskum všetkých Jednotkyštudoval agregát, a diskontinuálne (selektívne) pozorovanie- iba jeho časti.
Existuje päť hlavných spôsobov organizácie pozorovania vzoriek:
1. jednoduchý náhodný výber, v ktorom sú objekty náhodne extrahované zo všeobecnej populácie objektov (napríklad pomocou tabuľky alebo generátora náhodných čísel), pričom každá z možných vzoriek má rovnakú pravdepodobnosť. Takéto vzorky sa nazývajú riadny náhodný;
2. ľahký výber pomocou pravidelného postupu sa vykonáva pomocou mechanického komponentu (napríklad dátum, deň v týždni, číslo bytu, písmeno abecedy atď.) a vzorky získané týmto spôsobom sa nazývajú mechanický;
3. rozvrstvený výber spočíva v tom, že všeobecná populácia zväzku je rozdelená na podskupiny alebo vrstvy (vrstvy) zväzku tak, že. Straty sú z hľadiska štatistických charakteristík homogénne objekty (napríklad obyvateľstvo je rozdelené do vrstiev podľa vekových skupín alebo sociálnej triedy; podniky - podľa odvetví). V tomto prípade sa vzorky nazývajú rozvrstvený(inak, rozvrstvený, typický, zónovaný);
4. metódy sériový výber sa používa na vytvorenie sériový alebo vnorené vzorky... Sú vhodné, ak je potrebné naraz preskúmať „blok“ alebo sériu predmetov (napríklad zásielku tovaru, výrobky určitej série alebo obyvateľstvo v územno-správnom členení krajiny). Výber šarží sa môže uskutočňovať čisto náhodným alebo mechanickým spôsobom. Súčasne sa vykonáva kompletný prieskum určitej dávky tovaru alebo celého územného celku (obytná budova alebo štvrť);
5. kombinované(postupný) výber môže kombinovať niekoľko spôsobov výberu naraz (napríklad stratifikovaný a náhodný alebo náhodný a mechanický); takáto vzorka sa nazýva kombinované.
Typy výberu
Od myseľ rozlišovať medzi individuálnym, skupinovým a kombinovaným výberom. O individuálny výber jednotlivé jednotky všeobecnej populácie sú vybrané do vzorky, s skupinový výber- kvalitatívne homogénne skupiny (série) jednotiek, a kombinovaný výber predpokladá kombináciu prvého a druhého typu.
Od metóda výber rozlišovať opakované aj neopakované ukážka.
Neopakovateľné Volá sa výber, v ktorom sa jednotka, ktorá sa dostala do vzorky, nevráti do pôvodnej populácie a nezúčastní sa na ďalšom výbere; pričom počet jednotiek v bežnej populácii N. sa znižuje vo výberovom procese. O opakoval výber chytený vo vzorke sa jednotka po registrácii vráti všeobecnej populácii, a tak si zachováva rovnakú príležitosť, spolu s inými jednotkami, byť použitá v ďalšom výberovom konaní; pričom počet jednotiek v bežnej populácii N. zostáva nezmenený (metóda sa v sociálno-ekonomickom výskume používa zriedka). Avšak s veľkým N (N → ∞) vzorce pre neopakovateľné výbery sa blížia k tým pre opakoval výber a častejšie sa používajú tieto ( N = konšt).
Hlavné charakteristiky parametrov všeobecnej a vzorovej populácie
Štatistické závery štúdie sú založené na distribúcii náhodnej premennej, pričom pozorované hodnoty (x 1, x 2, ..., x n) sa nazývajú realizácie náhodnej premennej NS(n je veľkosť vzorky). Rozdelenie náhodnej premennej vo všeobecnej populácii je teoretické, ideálne a jej vzorový analóg je empirický distribúcia. Niektoré teoretické rozloženia sú uvedené analyticky, t.j. ich možnosti určte hodnotu distribučnej funkcie v každom bode v priestore možných hodnôt náhodnej premennej. V prípade vzorky je distribučná funkcia ťažké určiť, a preto je niekedy nemožná možnosti sa odhadujú z empirických údajov a potom sa nahradia analytickým výrazom opisujúcim teoretické rozdelenie. V tomto prípade je predpoklad (alebo hypotéza) o type distribúcie môže byť štatisticky správne aj chybné. Ale v každom prípade empirická distribúcia zrekonštruovaná zo vzorky len zhruba charakterizuje tú skutočnú. Najdôležitejšími distribučnými parametrami sú očakávaná hodnota a rozptyl.
Distribúcie sú zo svojej podstaty kontinuálne a diskrétne... Najznámejšia spojitá distribúcia je normálne... Selektívnymi analógmi parametrov sú stredná hodnota a empirický rozptyl. Spomedzi diskrétnych v sociálno-ekonomickom výskume sa najčastejšie používajú alternatíva (dichotomická) distribúcia. Parameter matematického očakávania tohto rozdelenia vyjadruje relatívnu hodnotu (alebo zdieľam) jednotky populácie, ktoré majú študovaný znak (je to označené písmenom); podiel populácie, ktorá nemá túto vlastnosť, je označený písmenom q (q = 1 - p)... Rozptyl alternatívnej distribúcie má tiež empirický analóg.
Charakteristiky distribučných parametrov sa vypočítavajú rôznymi spôsobmi v závislosti od typu distribúcie a od spôsobu výberu jednotiek populácie. V tabuľke sú uvedené hlavné teoretické a empirické rozdelenia. 1.
Frakcia vzorky k n je pomer počtu jednotiek vo vzorke k počtu jednotiek vo všeobecnej populácii:
k n = n / N.
Vzorková frakcia š Je pomer jednotiek k študovanému znaku X na veľkosť vzorky n:
w = n n / n.
Príklad. V šarži tovaru obsahujúceho 1000 jednotiek so vzorkou 5% frakcia vzorky k n v absolútnej hodnote je 50 jednotiek. (n = N * 0,05); ak sú v tejto vzorke nájdené 2 chybné výrobky, potom selektívna miera odpadu w bude 0,04 (w = 2/50 = 0,04 alebo 4%).
Pretože populácia vzorky sa líši od bežnej populácie, potom chyby vzorkovania.
Tabuľka 1. Základné parametre všeobecnej a výberovej populácie
Chyby pri vzorkovaní
Pri akýchkoľvek (pevných a selektívnych) chybách sa môžu vyskytnúť chyby dvoch typov: registrácia a reprezentatívnosť. Chyby registrácia môže mať náhodný a systematický charakter. Náhodne chyby sa skladajú z mnohých rôznych nekontrolovateľných príčin, sú neúmyselné a zvyčajne sa navzájom vyvažujú (napríklad zmeny hodnôt na prístroji počas teplotných výkyvov v miestnosti).
Systematické chyby sú tendenčné, pretože porušujú pravidlá pre výber predmetov vo vzorke (napríklad odchýlky v meraniach pri zmene nastavenia meracieho zariadenia).
Príklad. Na posúdenie sociálneho postavenia obyvateľstva v meste sa plánuje vyšetrenie 25% rodín. Ak je súčasne výber každého štvrtého bytu založený na jeho počte, potom existuje nebezpečenstvo výberu všetkých bytov iba jedného typu (napríklad jednoizbových), čo poskytne systematickú chybu a skreslí výsledky; výhodnejší je výber čísla bytu losovaním, pretože chyba bude náhodná.
Reprezentatívne chyby sú vlastné iba selektívnemu pozorovaniu, nedá sa im vyhnúť a vznikajú v dôsledku skutočnosti, že vzorka nereprodukuje úplne bežnú populáciu. Hodnoty ukazovateľov získané zo vzorky sa líšia od ukazovateľov rovnakých hodnôt vo všeobecnej populácii (alebo sa získavajú kontinuálnym pozorovaním).
Chyba pozorovania vzorky je rozdiel medzi hodnotou parametra vo všeobecnej populácii a jeho vzorovou hodnotou. Pre priemernú hodnotu kvantitatívnej charakteristiky sa rovná :, a pre podiel (alternatívna charakteristika) -.
Chyby pri vzorkovaní sú charakteristické iba pre pozorovania vzoriek. Čím sú tieto chyby väčšie, tým viac sa empirické rozdelenie líši od teoretického. Parametre empirickej distribúcie sú náhodné hodnoty, takže chyby vo vzorkovaní sú tiež náhodné hodnoty, môžu mať rôzne hodnoty pre rôzne vzorky, a preto je obvyklé vypočítať priemerná chyba.
Priemerná chyba vzorkovania existuje hodnota, ktorá vyjadruje štandardnú odchýlku priemeru vzorky od matematického očakávania. Táto hodnota podľa zásady náhodného výberu závisí predovšetkým od veľkosti vzorky a od stupňa variácií znaku: čím väčšia a menšia je variácia prvku (a teda aj hodnota), tým menšia je hodnota priemerná chyba vzorkovania. Pomer medzi rozptylmi všeobecnej populácie a vzorovej populácie je vyjadrený vzorcom:
tí. pre dostatočne veľké to môžeme predpokladať. Priemerná chyba vzorkovania ukazuje možné odchýlky parametra populácie vzorky od parametra všeobecnej populácie. Tabuľka 2 ukazuje výrazy na výpočet priemernej chyby vzorkovania pre rôzne metódy organizovania pozorovania.
Tabuľka 2. Priemerná chyba (m) priemeru vzorky a pomeru pre rôzne typy vzorky
Kde je priemer odchýlok vzorky v rámci skupiny pre spojitý prvok;
Priemer rozdielov v rámci skupiny v rámci skupiny;
- počet vybraných sérií, - celkový počet sérií;
 ,
,
kde je priemer z -tej série;
- celkový priemer za celú vzorku pre spojitý prvok;
 ,
,
kde je podiel funkcie v sérii th;
- celkový podiel funkcie na celej vzorke.
Hodnotu priemernej chyby je však možné posúdiť iba s určitou pravdepodobnosťou P (P ≤ 1). Lyapunov A.M. dokázali, že distribúcia priemerných hodnôt vzorky, a teda ich odchýlky od všeobecného priemeru, pre dostatočne veľký počet sa približne riadi normálnym distribučným zákonom za predpokladu, že všeobecná populácia má konečný priemer a obmedzený rozptyl.
Matematicky je toto tvrdenie o priemere vyjadrené ako:

a pre zlomok bude mať výraz (1) tvar:
kde  -
existuje hraničná chyba vzorkovania, čo je násobok priemernej chyby vzorkovania ,
a faktor multiplicity je Studentov test („faktor spoľahlivosti“) navrhnutý USA. Gosset (alias „študent“); hodnoty pre rôzne veľkosti vzoriek sú uložené v špeciálnej tabuľke.
-
existuje hraničná chyba vzorkovania, čo je násobok priemernej chyby vzorkovania ,
a faktor multiplicity je Studentov test („faktor spoľahlivosti“) navrhnutý USA. Gosset (alias „študent“); hodnoty pre rôzne veľkosti vzoriek sú uložené v špeciálnej tabuľke.

Preto výraz (3) možno čítať nasledovne: s pravdepodobnosťou P = 0,683 (68,3%) možno tvrdiť, že rozdiel medzi vzorkou a všeobecným priemerom nepresiahne jednu hodnotu strednej chyby m (t = 1), s pravdepodobnosťou P = 0,954 (95,4%)- že neprekročí hodnotu dvoch stredných chýb m (t = 2), s pravdepodobnosťou P = 0,997 (99,7%)- neprekročí tri hodnoty m (t = 3). Určuje teda pravdepodobnosť, že tento rozdiel prekročí trojnásobok priemernej chyby chybová úroveň a už nie je 0,3% .
Tabuľka 3 sú uvedené vzorce na výpočet hraničnej chyby výberu vzorky.
Tabuľka 3. Hraničná chyba (D) vzorky pre priemer a podiel (p) pre rôzne typy pozorovania vzorky
Distribúcia výsledkov vzorky do bežnej populácie
Konečným cieľom selektívneho pozorovania je charakterizovať všeobecnú populáciu. Pri malých veľkostiach vzorky sa empirické odhady parametrov (a) môžu výrazne líšiť od ich skutočných hodnôt (a). Preto je nevyhnutné stanoviť hranice, v rámci ktorých skutočné hodnoty (a) ležia pre vzorové hodnoty parametrov (a).
Interval spoľahlivosti akéhokoľvek parametra θ všeobecnej populácie sa nazýva náhodný rozsah hodnôt tohto parametra, ktorý s pravdepodobnosťou blízkou 1 ( spoľahlivosť) obsahuje skutočnú hodnotu tohto parametra.
Okrajová chyba vzorkovanie Δ umožňuje určiť limitné hodnoty charakteristík všeobecnej populácie a ich intervaly spoľahlivosti ktoré sú si rovné:
Spodná čiara interval spoľahlivosti získané odčítaním okrajová chyba zo vzorkového priemeru (podiel) a horného pridaním.
Interval spoľahlivosti pre priemer používa hraničnú chybu výberu a pre danú úroveň spoľahlivosti je určený vzorcom:
To znamená, že s danou pravdepodobnosťou R., ktorá sa nazýva úroveň spoľahlivosti a je jednoznačne určená hodnotou t, možno tvrdiť, že skutočná hodnota priemeru leží v rozmedzí od ![]() , a skutočná hodnota zlomku je v rozsahu od
, a skutočná hodnota zlomku je v rozsahu od
Pri výpočte intervalu spoľahlivosti pre tri štandardné úrovne spoľahlivosti P = 95%, P = 99% a P = 99,9% hodnota je zvolená pomocou. Aplikácie v závislosti od počtu stupňov voľnosti. Ak je veľkosť vzorky dostatočne veľká, potom hodnoty zodpovedajúce týmto pravdepodobnostiam t sú rovnaké: 1,96, 2,58 a 3,29 ... Hraničná chyba vzorkovania teda umožňuje určiť limitné hodnoty charakteristík všeobecnej populácie a ich intervaly spoľahlivosti:
Distribúcia výsledkov selektívneho pozorovania všeobecnej populácii v sociálno-ekonomickom výskume má svoje vlastné charakteristiky, pretože si vyžaduje úplnosť reprezentatívnosti všetkých jeho typov a skupín. Základom možnosti takejto distribúcie je výpočet relatívna chyba:

kde Δ % - relatívna hraničná chyba výberu vzorky; ,.
Existujú dve hlavné metódy rozšírenia pozorovania vzorky na všeobecnú populáciu: priama konverzia a metóda koeficientov.
Podstatou priama konverzia spočíva v vynásobení priemernej hodnoty vzorky !! \ overline (x) veľkosťou všeobecnej populácie.
Príklad... Nechajte priemerný počet batoľat v meste odhadnúť pomocou vzorovej metódy a byť osobou. Ak je v meste 1000 mladých rodín, potom sa počet požadovaných miest v mestských škôlkach získa vynásobením tohto priemeru veľkosťou bežnej populácie N = 1000, t.j. bude predstavovať 1 200 miest.
Kurzová metóda odporúča sa použiť v prípade, keď sa vykonáva selektívne pozorovanie, aby sa objasnili údaje o kontinuálnom pozorovaní.
V tomto prípade sa používa vzorec:
kde všetky premenné sú veľkosť populácie:
Požadovaná veľkosť vzorky
Tabuľka 4. Požadovaná veľkosť vzorky (n) pre rôzne typy organizácie pozorovania vzorky
Pri plánovaní pozorovania vzorky s vopred stanovenou hodnotou prípustnej chyby vzorkovania je potrebné správne odhadnúť požadovanú veľkosť vzorky... Tento objem je možné určiť na základe prípustnej chyby pri pozorovaní vzorky na základe danej pravdepodobnosti, ktorá zaručuje prípustnú hodnotu chybovej úrovne (s prihliadnutím na spôsob organizácie pozorovania). Vzorce na stanovenie požadovanej veľkosti vzorky n je ľahké získať priamo zo vzorcov pre hraničnú chybu vzorkovania. Takže z výrazu pre hraničnú chybu:
veľkosť vzorky sa priamo určí n:
Tento vzorec ukazuje, že s klesajúcou hraničnou chybou vzorkovania Δ požadovaná veľkosť vzorky sa výrazne zvyšuje, čo je úmerné odchýlke a štvorcu študentského testu.
Pre špecifický spôsob organizácie pozorovania sa požadovaná veľkosť vzorky vypočíta podľa vzorcov uvedených v tabuľke. 9.4.
Praktické príklady výpočtu
Príklad 1. Výpočet priemeru a intervalu spoľahlivosti pre spojitú kvantitatívnu charakteristiku.
Na posúdenie rýchlosti vyrovnania s veriteľmi banka vykonala náhodný výber 10 platobných dokumentov. Ukázalo sa, že ich hodnoty sú rovnaké (v dňoch): 10; 3; 15; 15; 22; 7; osem; 1; 19; dvadsať.
Potrebné s pravdepodobnosťou P = 0,954 určiť hraničnú chybu Δ priemer vzorky a limity spoľahlivosti pre priemerný čas výpočtov.
Riešenie. Priemerná hodnota sa vypočíta pomocou vzorca z tabuľky. 9.1 pre vzorku
![]()
Rozptyl sa vypočíta podľa vzorca z tabuľky. 9.1.
![]()
Priemerná štvorcová chyba za deň.
Priemerná chyba sa vypočíta podľa vzorca:
![]()
tí. priemer je x ± m = 12,0 ± 2,3 dní.
Spoľahlivosť priemeru bola
![]()
Obmedzujúca chyba sa vypočíta podľa vzorca z tabuľky. 9.3 pre opätovný odber vzoriek, pretože veľkosť populácie nie je známa, a pre P = 0,954úroveň sebavedomia.
Priemerná hodnota sa teda rovná `x ± D =` x ± 2 m = 12,0 ± 4,6, t.j. jeho skutočná hodnota sa pohybuje od 7,4 do 16,6 dní.
Použitie študentskej tabuľky. Aplikácia nám umožňuje dospieť k záveru, že pre n = 10 - 1 = 9 stupňov voľnosti je získaná hodnota spoľahlivá s hladinou významnosti 0,001 GBP, t.j. získaná priemerná hodnota sa výrazne líši od 0.
Príklad 2. Odhad pravdepodobnosti (všeobecný podiel) str.
Pri mechanickej metóde vzorkovania na skúmanie sociálneho postavenia 1000 rodín sa ukázalo, že podiel rodín s nízkymi príjmami bol w = 0,3 (30%)(vzorka bola 2% , t.j. n / N = 0,02). Potrebné s istotou p = 0,997 určiť indikátor R. rodiny s nízkymi príjmami v celom regióne.
Riešenie. Podľa prezentovaných hodnôt funkcie Ф (t) nájsť pre danú úroveň spoľahlivosti P = 0,997 význam t = 3(pozri vzorec 3). Chyba marginálneho podielu w určené vzorcom z tabuľky. 9.3 pre neopakujúce sa odbery vzoriek (mechanické odbery vzoriek sa vždy neopakujú):
Hraničná relatívna chyba vzorkovania v % bude:
Pravdepodobnosť (všeobecný podiel) rodín s nízkymi príjmami v regióne bude p = w ± Δ w, a limity spoľahlivosti p sa vypočítajú na základe dvojnásobnej nerovnosti:
w - Δ w ≤ p ≤ w - Δ w, t.j. skutočná hodnota p leží v:
0,3 — 0,014 < p <0,3 + 0,014, а именно от 28,6% до 31,4%.
S pravdepodobnosťou 0,997 je teda možné tvrdiť, že podiel rodín s nízkymi príjmami medzi všetkými rodinami v regióne sa pohybuje od 28,6% do 31,4%.
Príklad 3. Výpočet priemeru a intervalu spoľahlivosti pre diskrétny znak špecifikovaný radom intervalov.
Tabuľka 5. bolo stanovené rozdelenie príkazov na výrobu príkazov načasovaním ich vykonania podnikom.
Tabuľka 5. Rozdelenie pozorovaní podľa času výskytuRiešenie. Priemerný čas vykonania objednávky sa vypočíta podľa vzorca:
Priemerné obdobie bude:
= (3 * 20 + 9 * 80 + 24 * 60 + 48 * 20 + 72 * 20) / 200 = 23,1 mesiacov.
Rovnakú odpoveď dostaneme, ak použijeme údaje o p i z predposledného stĺpca tabuľky. 9.5 podľa vzorca:
Všimnite si toho, že stred intervalu pre poslednú gradáciu sa zistí jeho umelým doplnením o šírku intervalu predchádzajúcej gradácie rovnajúcu sa 60 - 36 = 24 mesiacov.
Rozptyl sa vypočíta podľa vzorca
![]()
kde x i- stred intervalového radu.
Preto !! \ sigma = \ frac (20 ^ 2 + 14 ^ 2 + 1 + 25 ^ 2 + 49 ^ 2) (4), a chyba stredného štvorca.
Priemerná chyba sa vypočíta pomocou vzorca pre mesiac, t.j. priemer je !! \ overline (x) ± m = 23,1 ± 13,4.
Obmedzujúca chyba sa vypočíta podľa vzorca z tabuľky. 9.3 pre opätovný odber vzoriek, pretože veľkosť populácie nie je známa, pre úroveň spoľahlivosti 0,954:
Priemer je teda:
tí. jeho skutočná hodnota sa pohybuje od 0 do 50 mesiacov.
Príklad 4. Na stanovenie rýchlosti vyrovnania s veriteľmi N = 500 podnikov spoločnosti v komerčnej banke je potrebné vykonať výberovú štúdiu metódou náhodného neopakovaného výberu. Stanovte požadovanú veľkosť vzorky n tak, aby s pravdepodobnosťou P = 0,954 chyba priemeru vzorky nepresiahla 3 dni, ak odhady pokusov ukázali, že štandardná odchýlka s bola 10 dní.
Riešenie... Na stanovenie počtu potrebných štúdií n použijeme vzorec na opakovaný výber z tabuľky. 9,4:

V ňom je hodnota t určená pre pre úroveň spoľahlivosti P = 0,954. Rovná sa 2. Stredný priemer odmocniny s = 10, veľkosť všeobecnej populácie je N = 500 a hraničná chyba priemeru je Δ x = 3. Nahradením týchto hodnôt do vzorca dostaneme:
![]()
tí. Stačí urobiť vzorku 41 podnikov, aby bolo možné odhadnúť požadovaný parameter - rýchlosť vyrovnania s veriteľmi.
Ukážka - toto je:
1) súhrn tých prvkov výskumného objektu, ktoré budú priamo študované;
2) metódy a postupy pre výber prvkov výskumného objektu.
Všeobecná populácia - kompletný súbor predmetov súvisiacich so skúmaným problémom. V sociologickom výskume ako G.S. najčastejšie ide o agregáty jednotlivcov - populáciu (mestá, krajiny atď.), sociálnu skupinu (mládež, nezamestnaní, podnikatelia atď.), publikum masmédií (QMS) atď. Avšak v mnohých prípadoch , GS ... môže pozostávať z väčších prvkov (predmetov) - rodiny (domácnosti), akademické skupiny, podniky, náboženské komunity, jednotlivé osady alebo štáty atď.
Vzorová populácia - časť predmetov z bežnej populácie vybraná na štúdium s cieľom urobiť záver o celej bežnej populácii.
Aby sa záver získaný skúmaním vzorky rozšíril na celú všeobecnú populáciu, vzorka musí mať vlastnosť reprezentatívnosti.
Reprezentatívnosť Je schopnosť vzorky reprezentovať cieľovú populáciu. Čím presnejšie zloženie vzorky predstavuje populáciu k skúmaným problémom, tým je jej reprezentatívnosť vyššia.
PRÍKLAD: Reprezentatívnosť je možné ilustrovať na nasledujúcom príklade. Predpokladajme, že populácia sú všetci študenti školy (600 ľudí z 20 tried, 30 ľudí v každej triede). Predmetom štúdie je prístup k fajčeniu. Vzorka 60 študentov stredných škôl predstavuje oveľa horšiu populáciu ako vzorka rovnakých 60 študentov, do ktorej budú zaradení 3 študenti z každej triedy. Hlavným dôvodom je nerovnomerné vekové rozdelenie v triedach. V dôsledku toho je v prvom prípade reprezentatívnosť vzorky nízka a v druhom prípade je reprezentatívnosť vysoká (všetky ostatné veci sú rovnaké).
Druhy vzoriek
1. Náhodný odber vzoriek.
1.1 Jednoduchý náhodný výber.
1.2 Metóda systematického (alebo mechanického) vzorkovania.
1.3 Sériové (vnorené alebo zoskupené) odber vzoriek.
1.4 Stratifikovaná vzorka.
2. Náhodná vzorka (nepravdepodobná).
2.2. Spontánny odber vzoriek.
2.3. Viacstupňové a jednostupňové vzorkovanie.
1. Náhodný odber vzoriek.
Zvláštnosťou náhodného vzorkovania je, že všetky jednotky všeobecnej populácie majú rovnakú pravdepodobnosť zaradenia do vzorky. Pri náhodnom vzorkovaní princíp náhodnosti... Vzorkovacím rámcom môžu byť zoznamy zamestnancov podniku, telefónne zoznamy, registračné zoznamy majiteľov automobilov, zoznamy voličov vo volebných miestnostiach, domáce knihy, ako aj rôzne zoznamy zostavené samotným sociológom v závislosti od cieľov štúdie (zoznam ulice, na ktorých sa potom vyberú respondenti).
Náhodný výber vzoriek sa zvyčajne používa v prieskumoch verejnej mienky pred voľbami, referendami a inými verejnými akciami.
Plus Táto metóda úplne dodržiava zásadu náhodnosti a v dôsledku toho sa vyhýba systematickým chybám.
Nevýhody tejto metódy:
- Potreba zoznamu prvkov bežnej populácie.
- Zložitosť prieskumu.
- Porovnateľne veľká veľkosť vzorky.
V štatistike existujú dve hlavné metódy výskumu - kontinuálne a selektívne. Pri vykonávaní štúdie na vzorke je povinné splniť nasledujúce požiadavky: reprezentatívnosť populácie vzorky a dostatočný počet pozorovacích jednotiek. Pri výbere pozorovacích jednotiek je to možné Ofsetové chyby, to znamená také udalosti, ktorých výskyt nemožno presne predpovedať. Tieto chyby sú objektívne a prirodzené. Pri určovaní stupňa presnosti štúdie vzorkovania sa odhaduje množstvo chýb, ktoré sa môžu vyskytnúť počas procesu odberu vzoriek - Náhodná chyba reprezentatívnosti (M) — Je to skutočný rozdiel medzi priemernými alebo relatívnymi hodnotami získanými vo výberovom prieskume a podobnými hodnotami, ktoré by sa získali pri prieskume na všeobecnej populácii.
Posúdenie spoľahlivosti výsledkov výskumu zahŕňa určenie:
1. chyby reprezentatívnosti
2. limity spoľahlivosti priemerných (alebo relatívnych) hodnôt v bežnej populácii
3. dôvera v rozdiel medzi strednými (alebo relatívnymi) hodnotami (podľa kritéria t)
Výpočet chyby reprezentatívnosti(mm) aritmetický priemer (M):
Kde σ je štandardná odchýlka; n je veľkosť vzorky (> 30).
Výpočet chyby reprezentatívnosti (mР) relatívnej hodnoty (Р):
Kde P je zodpovedajúca relatívna hodnota (vypočítaná napríklad v%);
Q = 100 - Ρ% je recipročná hodnota P; n - veľkosť vzorky (n> 30)
Pri klinickej a experimentálnej práci je často potrebné použiť Malá ukážka, Keď je počet pozorovaní menší alebo rovný 30. Pri malej vzorke na výpočet chýb reprezentatívnosti sú priemerné aj relatívne hodnoty , Počet pozorovaní sa znižuje o jedno, t.j.
![]() ; .
; .
Veľkosť chyby reprezentatívnosti závisí od veľkosti vzorky: čím väčší je počet pozorovaní, tým je chyba menšia. Na posúdenie spoľahlivosti vzorového ukazovateľa sa používa nasledujúci prístup: ukazovateľ (alebo priemerná hodnota) musí byť trikrát väčší ako jeho chyba, v tomto prípade sa považuje za spoľahlivý.
Poznanie veľkosti chyby nestačí na to, aby ste si boli istí výsledkami výberovej štúdie, pretože špecifická chyba výberovej štúdie môže byť výrazne väčšia (alebo menšia) ako hodnota strednej chyby reprezentatívnosti. Na určenie presnosti, s akou chce výskumník získať výsledok, štatistika používa taký koncept ako pravdepodobnosť bezchybnej predikcie, ktorá je charakteristická pre spoľahlivosť výsledkov selektívnych biomedicínskych štatistických štúdií. Pri vykonávaní biomedicínskych štatistických štúdií sa zvyčajne používa pravdepodobnosť bezchybnej predikcie 95% alebo 99%. V najkritickejších prípadoch, keď je potrebné vyvodiť teoreticky alebo prakticky obzvlášť dôležité závery, sa používa pravdepodobnosť bezchybnej predpovede 99,7%.
Istý stupeň pravdepodobnosti bezchybnej predpovede zodpovedá určitej hodnote Hraničná chyba náhodného vzorkovania (Δ - delta), ktorý je určený vzorcom:
Δ = t * m, kde t je koeficient spoľahlivosti, ktorý je pre veľkú vzorku s 95% pravdepodobnosťou bezchybnej prognózy 2,6; s pravdepodobnosťou bezchybnej predpovede 99% - 3,0; s pravdepodobnosťou bezchybnej predpovede 99,7% - 3,3 a s malou vzorkou je určená špeciálnou tabuľkou Studentových t hodnôt.
Pomocou hraničnej chyby vzorkovania (Δ) je možné určiť Hranice spoľahlivosti, v ktorom s určitou pravdepodobnosťou bezchybnej predpovede skutočná hodnota štatistickej veličiny , Charakterizujúca celú všeobecnú populáciu (priemernú alebo relatívnu).
Na stanovenie limitov spoľahlivosti sa používajú nasledujúce vzorce:
1) pre priemerné hodnoty:
Kde Mgen - limity spoľahlivosti priemeru vo všeobecnej populácii;
Príklad - priemer , Získané pri vykonávaní štúdie na vzorovej populácii; t je koeficient spoľahlivosti, ktorého hodnota je daná stupňom pravdepodobnosti bezchybnej predpovede, s ktorou chce vedec získať výsledok; mM je chyba reprezentatívnosti priemeru.
2) pre relatívne hodnoty:
Where Pgen - limity spoľahlivosti relatívnej hodnoty v bežnej populácii; Psyb - relatívna hodnota získaná pri vykonávaní štúdie na vzorke populácie; t je faktor spoľahlivosti; mP - chyba reprezentatívnosti relatívnej hodnoty.
Limity spoľahlivosti ukazujú, do akej miery môže veľkosť vzorky kolísať v závislosti od náhodných dôvodov.
S malým počtom pozorovaní (n<30), для вычисления доверительных границ значение коэффициента t находят по специальной таблице Стьюдента. Значения t расположены в таблице на пересечении с избранной вероятностью безошибочного прогноза и строки, Udáva počet dostupných stupňov voľnosti (n) , Čo je n-1.
V skutočnosti začneme nie jednou, ale tromi otázkami: Čo je to vzorkovanie? kedy je to reprezentatívne? čo je to?
Agregát Zaujíma nás nejaká skupina ľudí, organizácií, udalostí, o ktorých chceme vyvodiť závery, a deje sa, alebo predmet, - akýkoľvek prvok takejto sady 1 .Ukážka - akákoľvek podskupina súboru prípadov (objektov) pridelených na analýzu. Ak by sme chceli študovať rozhodovaciu činnosť zákonodarcov štátu, mohli by sme túto činnosť skúmať v zákonodarných orgánoch štátov Virgínia, Severná Karolína a Južná Karolína, a nie vo všetkých päťdesiatich štátoch a na základe toho šíriťúdaje získané pre populáciu, z ktorej boli tieto tri stavy vybrané. Ak by sme chceli preskúmať pensylvánsky systém preferencií voličov, mohli by sme to urobiť rozhovorom s 50 pracovníkmi v Yu. S. Steele “v Pittsburghu a šíriť výsledky hlasovania medzi všetkými voličmi v štáte. Rovnako tak, ak chceme merať inteligenciu vysokoškolákov, mohli by sme otestovať všetkých obranných hráčov Ohia pre danú futbalovú sezónu a potom zovšeobecniť výsledky na populáciu, ktorej sú súčasťou. V každom prípade postupujeme nasledovne: v rámci populácie vytvoríme skôr podskupinu podrobne študujeme túto podskupinu alebo vzorku a rozširujeme naše výsledky na celú populáciu. Toto sú hlavné fázy vzorkovania.
Zdá sa však celkom zrejmé, že každá z týchto vzoriek má značnú nevýhodu. Hoci napríklad zákonodarné orgány štátu Virgínia, Severná Karolína a Južná Karolína sú súčasťou agregátu štátnych zákonodarných zborov, z historických, geografických a politických dôvodov pravdepodobne budú postupovať veľmi podobne a veľmi odlišne ako zákonodarné orgány tak odlišné od zákonodarných zborov. štáty ako New York, Nebraska a Aljaška. Aj keď päťdesiat oceliarov v Pittsburghu môžu byť voliči z Pensylvánie, ich socioekonomický status, vzdelanie a životné skúsenosti pravdepodobne budú mať názory, ktoré sa líšia od názorov mnohých podobných voličov. Rovnako tak, hoci sú futbalisti z Ohia vysokoškoláci, môžu sa veľmi líšiť od ostatných študentov z rôznych dôvodov. Inými slovami, aj keď je každá z týchto podskupín skutočne ukážkou, členovia každej z nich sa systematicky líšia od väčšiny zvyšku populácie, z ktorej sú vybraní. Ako samostatná skupina nie je žiadny z nich typický z hľadiska distribúcie atribútov názorov, motívov správania a charakteristík v bežnej populácii, s ktorou je spojený. Podľa toho by politológovia povedali, že žiadna z týchto vzoriek nie je reprezentatívna.
Reprezentatívna vzorka - toto je vzorka, v ktorej sú všetky hlavné črty všeobecnej populácie, z ktorej je táto vzorka extrahovaná, prezentované približne v rovnakom pomere alebo s rovnakou frekvenciou, s akou sa táto vlastnosť objavuje v tejto všeobecnej populácii. Ak sa teda 50% všetkých štátnych zákonodarných zborov stretáva iba každé dva roky, mala by byť tohto druhu približne polovica reprezentatívnej vzorky zákonodarných zborov štátu. Ak je 30% voličov z Pensylvánie modrých golierov, asi 30% zástupcov vzorky pre týchto voličov (nie 100% ako v príklade vyššie) by mali mať modré goliere. A ak sú 2% všetkých vysokoškolákov športovci, zhruba rovnaký podiel reprezentatívnej vzorky vysokoškolákov by mali byť športovci. Inými slovami, reprezentatívna vzorka je mikrokozmos, menší, ale presný model populácie, ktorú by mal predstavovať. Pokiaľ je vzorka reprezentatívna, dá sa bezpečne predpokladať, že závery zo štúdie tejto vzorky platia pre pôvodnú populáciu. Toto šírenie výsledkov je to, čo nazývame zovšeobecnením.
Možno to objasní grafická ilustrácia. Predpokladajme, že chceme študovať vzorce členstva v politických skupinách medzi dospelou populáciou USA. Obrázok 5.1 zobrazuje tri kruhy rozdelené do šiestich rovnakých sektorov. Obrázok 5.1a predstavuje celú uvažovanú populáciu. Členovia populácie sú klasifikovaní podľa politických skupín (ako sú strany a záujmové skupiny), ku ktorým patria. V tomto prípade každý dospelý patrí najmenej k jednej a nie viac ako šiestim politickým skupinám; a týchto šesť úrovní členstva je v súhrne rovnako bežných (teda rovnakých sektorov). Predpokladajme, že chceme skúmať motívy ľudí zapojiť sa do skupiny, vzorce výberu skupín a vzorce účasti, ale vzhľadom na obmedzené zdroje sme schopní prieskumu iba jedného zo šiestich členov populácie. Kto by mal byť vybraný na analýzu?
Ryža. 5.1. Odber vzoriek z bežnej populácie
Jedna z možných vzoriek danej veľkosti je znázornená tieňovanou oblasťou na obrázku 5.1b, ale neodráža jasne štruktúru populácie. Ak by sme zovšeobecnili z tejto vzorky, dospeli by sme k záveru (1), že všetci dospelí Američania patria k piatim politickým skupinám, a (2) že všetky americké skupinové správanie sa zhoduje so správaním tých, ktorí sú presne v piatich skupinách. Vieme však, že prvý záver nie je správny, a to v nás môže vyvolať pochybnosti o platnosti druhého. Preto Vzorka znázornená na obrázku 5.1b nie je reprezentatívna, pretože neodráža distribúciu danej vlastnosti populácie (často sa nazýva parameter ) v súlade s jeho skutočným rozdelením. Takáto vzorka vraj je posunul smerom kčlenovia piatich skupín resp posunul sa od všetky ostatné modely členstva v skupine. Na základe takto zaujatej vzorky máme tendenciu vyvodzovať mylné závery o populácii.
Najjasnejšie to možno demonštrovať na príklade katastrofy, ktorá postihla časopis Literary Digest v 30. rokoch minulého storočia, ktorý zorganizoval prieskum verejnej mienky ohľadom výsledkov volieb. Literary Digest bolo periodikum, v ktorom boli dotlače úvodníky z novín a iné materiály odrážajúce verejnú mienku; tento časopis bol na začiatku storočia veľmi populárny. Začiatkom roku 1920 časopis realizoval rozsiahlu celonárodnú anketu, v ktorej bolo viac ako miliónu ľudí zaslaných hlasovacími lístkami s prosbou, aby uviedli, koho kandidatúru uprednostnili pre nadchádzajúce prezidentské voľby. Výsledky prieskumu časopisu boli za tie roky také presné, že sa zdá, že septembrový prieskum má len malý význam pre novembrové voľby. A ako mohlo dôjsť k chybe v takej veľkej vzorke? V roku 1936 sa však stalo presne toto: s veľkou väčšinou hlasov (60:40) bolo víťazstvo predpovedané republikánskemu kandidátovi Alfovi Landonovi. Vo voľbách Landon prehral so zdravotne postihnutým človekom - Franklin D. Roosevelt - s prakticky rovnakým výsledkom, s akým mal vyhrať. Dôveryhodnosť „Literary Digest“ bola natoľko narušená, že časopis krátko nato prestal vychádzať. Čo sa stalo? Jednoducho, prieskum Digest použil zaujatú vzorku. Pohľadnice boli odoslané ľuďom, ktorých mená boli získané z dvoch zdrojov: telefónnych zoznamov a registračných zoznamov automobilov. A hoci sa tento spôsob výberu príliš nelíšil od ostatných spôsobov predtým, situácia bola úplne odlišná teraz, počas Veľkej hospodárskej krízy v roku 1936, keď si menej bohatí voliči, najpravdepodobnejší opora Roosevelta, nemohli dovoliť mať telefón, nieto auto. Preto bola vzorka použitá v prieskume Digest v skutočnosti zameraná na tých, ktorí s najväčšou pravdepodobnosťou budú republikáni, a stále je prekvapujúce, že Roosevelt mal taký dobrý výsledok.
Ako je možné tento problém vyriešiť? Vráťme sa k nášmu príkladu a porovnajte vzorku na obrázku 5.1b so vzorkou na obrázku 5.1c. V druhom prípade bola na analýzu vybraná aj šestina populácie, ale každý z hlavných typov populácie je vo vzorke zastúpený v pomere, v akom je zastúpená v celej populácii. Táto vzorka ukazuje, že každý šiesty dospelý Američan patrí do jednej politickej skupiny, každý šiesty až dva atď. Takýto výber vzorky odhalí aj ďalšie rozdiely medzi jeho členmi, ktoré by mohli korelovať s účasťou v inom počte skupín. Vzorka zobrazená na obrázku 5.1c je teda reprezentatívnou vzorkou pre uvažovanú populáciu.
Tento príklad je samozrejme zjednodušený najmenej z dvoch mimoriadne dôležitých hľadísk. Po prvé, väčšina populácií, ktoré zaujímajú politológov, je rozmanitejšia ako populácia uvedená v tomto príklade. Ľudia, dokumenty, vlády, organizácie, rozhodnutia atď. sa od seba líšia nie jedným, ale oveľa väčším počtom znakov. Reprezentatívna vzorka by teda mala byť taká, že každý jeden hlavného, odlišného od ostatných prezentované v pomere k jeho podielu na súhrne. Za druhé, situácia, keď skutočné rozdelenie premenných alebo charakteristík, ktoré chceme merať, nie je vopred známe, nastáva oveľa častejšie ako naopak - možno nebolo merané v predchádzajúcom sčítaní. Reprezentatívna vzorka by preto mala byť navrhnutá tak, aby mohla presne odrážať existujúce rozdelenie, aj keď nie sme schopní priamo posúdiť jej platnosť. Procedúra odberu vzoriek musí mať vnútornú logiku, ktorá nás môže presvedčiť, že keby sme mohli vzorku porovnať so sčítaním, bola by skutočne reprezentatívna.
Vedci sa zameriavajú na štatistické metódy, aby zaistili, že komplexnú organizáciu danej populácie je možné presne odrážať a určitý stupeň dôvery, že navrhované postupy sú toho schopné. Pôsobia však dvoma smermi. Vedci najskôr pomocou určitých pravidiel (internej logiky) rozhodnú otázku, aké konkrétne objekty by mali študovať, čo presne by malo byť zahrnuté v konkrétnej vzorke. Za druhé, pomocou veľmi odlišných pravidiel rozhodujú, koľko objektov vybrať. Tieto početné pravidlá nebudeme podrobne študovať, budeme zvažovať iba ich úlohu v politologickom výskume. Začnime so stratégiami pre výber predmetov, ktoré tvoria reprezentatívnu vzorku.