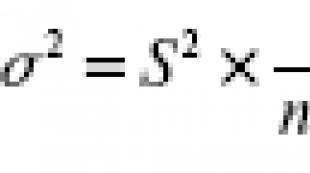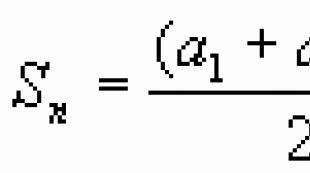Tema seminara: uzorkovanje u sociološkim istraživanjima Ključni pojmovi. Reprezentativni uzorak Uzorak i opća populacija
Statističko istraživanje je vrlo mukotrpno i skupo, pa se pojavila ideja da se kontinuirano promatranje zamijeni selektivnim.
Glavna svrha diskontinuiranog posmatranja je dobijanje karakteristika proučavane statističke populacije za njen anketirani dio.
Selektivno opažanje- Ovo je metoda statističkog istraživanja, u kojoj se generalizirani pokazatelji stanovništva utvrđuju samo za zasebni dio na osnovu odredbi slučajnog odabira.
Metodom uzorkovanja proučava se samo određeni dio proučavane populacije, dok se statistička populacija koja se proučava naziva općom populacijom.
Uzorak populacije ili jednostavno uzorak može se nazvati dio jedinica odabran iz opće populacije koji će biti podvrgnut statističkom istraživanju.
Vrijednost metode uzorkovanja: s minimalnim brojem jedinica koje se proučavaju, statistička studija će se provoditi u kraćim vremenskim periodima i uz najmanje troškove sredstava i rada.
U općoj populaciji, udio jedinica koje imaju proučavanu osobinu naziva se opća proporcija (označena sa R), a prosječna vrijednost karakteristike proučavane varijable je opći prosjek (označen sa NS).
U populaciji uzorka, udio ispitivane osobine naziva se udio uzorka, ili dio (označen sa w), prosječna vrijednost u uzorku je srednja vrijednost uzorka.
Ako se tijekom razdoblja istraživanja poštuju sva pravila njegove znanstvene organizacije, tada će metoda uzorkovanja dati prilično točne rezultate, pa je stoga preporučljivo koristiti ovu metodu za provjeru podataka stalnog promatranja.
Ova je metoda postala široko rasprostranjena u državnoj i neresornoj statistici, jer vam u proučavanju minimalnog broja jedinica koje se proučavaju omogućuje pažljivo i točno provođenje studije.
Proučavana statistička populacija sastoji se od jedinica različitih karakteristika. Sastav uzorkovane populacije može se razlikovati od sastava opće populacije; ova razlika između karakteristika uzorka i opće populacije je greška uzorkovanja.
Greške svojstvene posmatranju uzorka karakterišu veličinu odstupanja između podataka posmatranja uzorka i cijele populacije. Greške nastale tokom uzorkovanja nazivaju se greške reprezentativnosti i dijele se na slučajne i sistematske.
Ako populacija uzorka ne reproducira točno cijelu populaciju zbog prekidne prirode promatranja, to se naziva slučajnim greškama, a njihove veličine se s dovoljnom točnošću određuju na temelju zakona velikih brojeva i teorije vjerojatnosti.
Sistemske greške nastaju kao posljedica kršenja principa slučajnosti u odabiru populacionih jedinica za posmatranje.
2. Vrste i sheme odabira
Veličina greške uzorkovanja i metode za njeno određivanje zavise od vrste i sheme odabira.
Postoje četiri vrste odabira za skup jedinica posmatranja:
1) nasumično;
2) mehanički;
3) tipično;
4) serijski (ugniježđen).
Slučajno uzorkovanje- najčešća metoda odabira u slučajnom uzorku, naziva se i metoda ždrijeba, u kojoj se za svaku jedinicu statističke populacije priprema karta sa serijskim brojem.
Nadalje, nasumično se bira potreban broj jedinica statističke populacije. Pod ovim uvjetima, svaki od njih ima jednaku vjerojatnost da bude uključen u uzorak, na primjer, izvlačenje dobitaka, kada se određeni dio brojeva na koje pada dobitak nasumično bira iz ukupnog broja izdanih tiketa. Istovremeno, svi brojevi imaju jednaku priliku da uđu u uzorak.
Mehanički odabir- ovo je metoda kada se cijela populacija podijeli u grupe homogene po volumenu prema slučajnom kriteriju, tada se iz svake grupe uzima samo jedna jedinica. Sve jedinice proučavane statističke populacije prethodno su raspoređene u određenom redoslijedu, ali ovisno o veličina uzorka, potreban broj jedinica se mehanički bira u određenom intervalu ...
Tipičan izbor - Ovo je metoda u kojoj se proučavana statistička populacija dijeli prema značajnoj, tipičnoj značajci na kvalitativno homogene, slične grupe, zatim se slučajno odabire određeni broj jedinica iz svake ove grupe, proporcionalno specifičnoj težini grupe u celokupno stanovništvo.
Tipičan odabir daje preciznije rezultate, jer uključuje predstavnike svih tipičnih grupa u uzorku.
Serijski (ugniježđeni) odabir. Cijele grupe (serije, gnijezda), nasumično ili mehanički odabrane, podliježu odabiru. Za svaku takvu grupu i seriju provodi se kontinuirano promatranje, a rezultati se prenose na cijelu populaciju.
Tačnost uzorkovanja takođe zavisi od šeme odabira. Uzorkovanje se može provesti prema shemi ponovljenog i neponavljajućeg uzorkovanja.
Ponovljeni odabir. Svaka odabrana jedinica ili serija se vraća cijeloj populaciji i može se vratiti uzorku.To je tzv.
Odabir koji se ne može ponoviti. Svaka anketirana jedinica se povlači i ne vraća u agregat, pa se ne preispituje. Ova shema se naziva nepovratna lopta.
Ponovljeno uzorkovanje daje točnije rezultate, jer za istu veličinu uzorka promatranje obuhvaća više jedinica ispitivane populacije.
Kombinovani izbor može proći jedan ili više koraka. Uzorak se naziva jednostepenim ako se ispitaju jedinice populacije koje su odabrane jednom.
Uzorak se naziva višestepenim ako odabir populacije prolazi kroz faze, uzastopne faze, a svaka faza, faza odabira ima svoju jedinicu odabira.
Višefazno uzorkovanje - u svim fazama uzorkovanja zadržava se ista jedinica uzorkovanja, ali se provodi nekoliko faza, faza istraživanja uzorka, koje se razlikuju po širini programa istraživanja i veličini uzorka.
Karakteristike parametara opće populacije i uzorkovane populacije označene su sljedećim simbolima:
N- obim opšte populacije;
n- veličina uzorka;
X- opšti prosjek;
NS- srednja vrijednost uzorka;
R- opšti udio;
w - selektivni udio;
2 - opšta varijansa (varijacija obeležja u opštoj populaciji);
2 - varijansa uzorka iste karakteristike;
? - standardna devijacija u opštoj populaciji;
? - standardna devijacija u uzorku.
3. Greške uzorkovanja
Svaka jedinica u posmatranju uzorka trebala bi imati jednake mogućnosti s drugima da budu odabrane - to je osnova samo -slučajnog uzorka.
Samo-slučajno uzorkovanje - Ovo je odabir jedinica iz cijele opće populacije ždrijebom ili na neki drugi sličan način.
Princip slučajnosti je da na uključivanje ili isključivanje objekta iz uzorka ne može utjecati bilo koji drugi faktor osim slučaja.
Uzorak Je li odnos broja jedinica u uzorku prema broju jedinica u općoj populaciji:
Pravilni slučajni odabir u svom čistom obliku početni je među svim ostalim vrstama odabira; sadrži i primjenjuje osnovne principe selektivnog statističkog promatranja.
Dva glavna tipa generalizirajućih pokazatelja koji se koriste u metodi uzorkovanja su prosječna vrijednost kvantitativne karakteristike i relativna vrijednost alternativne karakteristike.
Udio uzorka (w), ili određeni, određen je omjerom broja jedinica sa proučavanom osobinom m, na ukupan broj jedinica uzorka (n):
Kako bi se okarakterizirala pouzdanost pokazatelja uzorkovanja, razlikuju se srednja i granične greške uzorkovanja.
Greška uzorkovanja, koja se naziva i greška reprezentativnosti, razlika je između odgovarajućeg uzorka i općih karakteristika:
?x = | x - x |;
?w = | x - p |.
Greška uzorkovanja svojstvena je samo opservacijama
Prosječna vrijednost uzorka i udio uzorka- to su slučajne varijable koje imaju različite vrijednosti ovisno o jedinicama istraživane statističke populacije koje su uključene u uzorak. Shodno tome, greške uzorkovanja su također slučajne vrijednosti i mogu poprimiti različite vrijednosti. Stoga se utvrđuje prosjek mogućih grešaka - prosječna greška uzorkovanja.
Prosječna greška uzorkovanja određena je veličinom uzorka: što je veći broj, pod jednakim uvjetima, manja je prosječna greška uzorkovanja. Pokrivajući sve veći broj jedinica opće populacije uzorkom, sve preciznije karakteriziramo čitavu opću populaciju.
Prosječna greška uzorkovanja ovisi o stupnju varijacije proučavane osobine, zauzvrat, stupanj varijacije karakterizira varijansa? 2 ili w (l - w)- za alternativnu funkciju. Što je manja varijacija svojstva i varijansa, manja je srednja greška uzorkovanja i obrnuto.
Za slučajno ponovno uzorkovanje, srednje greške se teoretski izračunavaju pomoću sljedećih formula:
1) za prosječno kvantitativno svojstvo:
gdje? 2 - prosječna vrijednost varijance kvantitativnog svojstva.
2) za dionicu (alternativna funkcija):
Dakle, kakva je varijansa neke osobine u općoj populaciji? 2 nije točno poznato, u praksi se koristi vrijednost varijanse S 2 izračunata za populaciju uzorka na osnovu zakona velikih brojeva, prema kojoj populacija uzorka s dovoljno velikom veličinom uzorka reproducira karakteristike općeg stanovništvo prilično tačno.
Formule za srednju grešku uzorkovanja za slučajno ponovno uzorkovanje su sljedeće. Za prosječnu vrijednost kvantitativne osobine: opća varijacija izražava se kroz izbor na sljedeći način:
gdje je S 2 vrijednost varijanse.
Mehaničko uzorkovanje- ovo je odabir jedinica u uzorku iz opće populacije, koja je podijeljena u jednake grupe prema neutralnom kriteriju; se radi na takav način da se iz svake takve grupe bira samo jedna jedinica.
U mehaničkom odabiru, jedinice statističke populacije koja se proučava prethodno su raspoređene u određenom redoslijedu, nakon čega se određeni broj jedinica bira mehanički u određenom intervalu. Štaviše, veličina intervala u opštoj populaciji jednaka je recipročnoj vrijednosti uzoraka.
S dovoljno velikom populacijom, mehanički odabir u smislu točnosti rezultata blizak je slučajnom nasljeđu, pa se za određivanje prosječne pogreške mehaničkog uzorkovanja koriste formule za samo-slučajno neponavljajuće uzorkovanje.
Za odabir jedinica iz heterogene populacije koristi se takozvani tipični uzorak, koristi se kada se sve jedinice opće populacije mogu podijeliti u nekoliko kvalitativno homogenih, sličnih grupa prema karakteristikama od kojih ovise ispitivani pokazatelji.
Zatim se iz svake tipične grupe vrši pojedinačni odabir jedinica u populaciji uzorka samo-slučajnim ili mehaničkim uzorkovanjem.
Tipično uzorkovanje obično se koristi pri proučavanju složenih statističkih populacija.
Tipično uzorkovanje daje preciznije rezultate. Tipizacija opće populacije osigurava reprezentativnost takvog uzorka, zastupljenost svake tipološke grupe u njemu, što omogućava isključivanje utjecaja međugrupne varijance na srednju grešku uzorkovanja. Stoga se pri određivanju prosječne greške tipičnog uzorka prosjek unutargrupnih varijansi koristi kao pokazatelj varijacije.
Serijsko uzorkovanje uključuje nasumični odabir iz opće populacije grupa jednake veličine kako bi se sve jedinice podvrgle promatranju u takvim grupama.
Budući da se sve jedinice bez izuzetka ispituju unutar grupa (serija), prosječna greška uzorkovanja (pri odabiru serija jednake veličine) ovisi samo o međugrupnoj (međuseriji) varijansi.
4. Načini distribucije rezultata uzorka općoj populaciji
Karakterizacija opće populacije na temelju rezultata uzorka krajnji je cilj promatranja uzorka.
Metoda uzorkovanja koristi se za dobijanje karakteristika opće populacije za određene pokazatelje uzorka. Ovisno o ciljevima istraživanja, to se provodi direktnim preračunavanjem indeksa uzorka za opću populaciju ili metodom izračunavanja korekcijskih faktora.
Metoda direktnog preračunavanja je da se s njom pokažu pokazatelji udjela uzorka w ili prosek NS primjenjuju se na opću populaciju, uzimajući u obzir grešku uzorkovanja.
Metoda korekcijskih faktora koristi se kada je svrha metode uzorkovanja pojašnjenje rezultata potpunog računovodstva. Ova metoda se koristi za preciziranje podataka godišnjeg popisa stoke među stanovništvom.
Statistička populacija- skup jedinica s masom, tipičnošću, kvalitativnom homogenošću i prisutnošću varijacija.
Statistička populacija se sastoji od materijalno postojećih objekata (radnika, preduzeća, zemalja, regija), je objekt.
Agregatna jedinica- svaku posebnu jedinicu statističke populacije.
Jedna te ista statistička populacija može biti homogena po jednom svojstvu, a heterogena po drugom.
Kvalitativna uniformnost- sličnost svih jedinica agregata iz nekog razloga i različitost za sve ostale.
U statističkoj populaciji razlike između jedne jedinice stanovništva i druge često su kvantitativne prirode. Kvantitativne promjene vrijednosti karakteristika različitih jedinica populacije nazivaju se varijacije.
Varijacija obilježja- kvantitativna promjena svojstva (za kvantitativno svojstvo) tokom prijelaza iz jedne jedinice populacije u drugu.
Sign Je svojstvo, karakteristično svojstvo ili drugo obilježje jedinica, objekata i pojava koje se može promatrati ili mjeriti. Znakovi su podijeljeni na kvantitativne i kvalitativne. Raznolikost i varijabilnost vrijednosti svojstva u pojedinim jedinicama populacije naziva se varijacija.
Atributivne (kvalitativne) karakteristike ne podliježu numeričkom izrazu (sastav stanovništva prema spolu). Kvantitativne karakteristike su numeričke (sastav stanovništva prema starosti).
Index- to je kvantitativno sažeta kvalitativna karakteristika bilo kojeg svojstva jedinica ili skupa u cjelini u specifičnim uvjetima vremena i mjesta.
Scorecard Skup je pokazatelja koji sveobuhvatno odražavaju fenomen koji se proučava.
Na primjer, plaća se proučava:- Odlika - plaće
- Statistička populacija - svi zaposleni
- Populaciona jedinica - svaki zaposleni
- Kvalitativna homogenost - obračunate plate
- Varijacija znaka - niz brojeva
Opšta populacija i uzorak iz nje
Osnova je skup podataka dobivenih kao rezultat mjerenja jedne ili više značajki. Stvarno promatrani skup objekata, statistički predstavljen brojnim opažanjima slučajne varijable, je uzorkovanje, i hipotetički postojeći (nagađani) - opšta populacija... Opšta populacija može biti konačna (broj opservacija N = konst) ili beskonačno ( N = ∞), a uzorak iz opće populacije uvijek je rezultat ograničenog broja promatranja. Broj opažanja koja čine uzorak naziva se veličina uzorka... Ako je veličina uzorka dovoljno velika ( n → ∞) uzorak se razmatra veliki inače se naziva uzorak ograničen volumen... Uzorak se razmatra mali ako pri mjerenju jednodimenzionalne slučajne varijable veličina uzorka ne prelazi 30 ( n<= 30 ), a pri mjerenju nekoliko ( k) karakteristike u višedimenzionalnom prostoru, odnos n To k manje od 10 (n / k< 10) ... Obrasci uzorka raspon varijacija ako su njegovi članovi redna statistika, tj. uzorke vrijednosti slučajne varijable NS sortirano uzlazno (rangirano), dok se vrijednosti obilježja pozivaju opcije.
Primjer... Gotovo isti nasumično odabran skup objekata - poslovne banke jednog upravnog okruga u Moskvi, može se smatrati uzorkom iz opće populacije svih poslovnih banaka u ovom okrugu, te kao uzorak iz opće populacije svih poslovnih banaka u Moskvi , kao i uzorak iz poslovnih banaka u zemlji itd.
Osnovne metode uzorkovanja
Pouzdanost statističkih zaključaka i smislena interpretacija rezultata ovise o tome reprezentativnost uzorkovanje, tj. potpunost i adekvatnost predstavljanja svojstava opće populacije, u odnosu na koje se ovaj uzorak može smatrati reprezentativnim. Proučavanje statističkih svojstava populacije može se organizirati na dva načina: pomoću kontinuirano i diskontinuirano. Kontinuirano posmatranje predviđa istraživanje svih jedinice studirao agregat, a diskontinuirano (selektivno) promatranje- samo njegovi dijelovi.
Postoji pet glavnih načina organiziranja posmatranja uzorka:
1. jednostavan slučajan odabir, u kojima se objekti nasumično izdvajaju iz opće populacije objekata (na primjer, pomoću tablice ili generatora slučajnih brojeva), pri čemu svaki od mogućih uzoraka ima jednaku vjerojatnost. Takvi uzorci se nazivaju pravilan slučajni;
2. jednostavan odabir pomoću uobičajene procedure provodi se pomoću mehaničke komponente (na primjer, datum, dan u sedmici, broj stana, slovo abecede itd.), a uzorci dobiveni na ovaj način nazivaju se mehanički;
3. slojevito odabir se sastoji u činjenici da se opća populacija volumena dijeli na podskupove ili slojeve (slojeve) volumena tako da. Stratumi su homogeni objekti u smislu statističkih karakteristika (na primjer, stanovništvo je podijeljeno u slojeve prema starosnim grupama ili društvenoj klasi; preduzeća - prema industriji). U tom slučaju pozivaju se uzorci slojevito(inače, slojevito, tipično, zonirano);
4.metode serijski odabir se koristi za formiranje serijski ili ugniježđeni uzorci... Pogodne su ako je potrebno odjednom pregledati "blok" ili niz objekata (na primjer, pošiljku robe, proizvode određene serije ili stanovništvo u teritorijalno-administrativnoj podjeli zemlje). Odabir serija može se izvršiti na potpuno slučajan ili mehanički način. U tom se slučaju provodi kompletno ispitivanje određene serije robe ili cijele teritorijalne jedinice (stambene zgrade ili kvarta);
5. kombinovano(postupno) odabir može kombinirati nekoliko metoda odabira odjednom (na primjer, slojevito i nasumično ili nasumično i mehanički); takav uzorak se naziva kombinovano.
Vrste odabira
By um razlikovati individualni, grupni i kombinirani odabir. At individualni odabir pojedinačne jedinice opće populacije odabrane su u uzorku, sa grupni izbor- kvalitativno homogene grupe (serije) jedinica, i kombinovani izbor pretpostavlja kombinaciju prvog i drugog tipa.
By metoda izbor razlikovati ponovljeno i neponovljeno uzorak.
Neponovljivo poziva se selekcija u kojoj se jedinica koja je ušla u uzorak ne vraća u prvobitnu populaciju i ne učestvuje u daljem odabiru; dok je broj jedinica u opštoj populaciji N se smanjuje u procesu odabira. At ponovljeno izbor uhvaćen u uzorku se jedinica nakon registracije vraća općoj populaciji i na taj način zadržava jednake mogućnosti, zajedno s drugim jedinicama, za upotrebu u daljem postupku odabira; dok je broj jedinica u opštoj populaciji N ostaje nepromijenjena (metoda se rijetko koristi u socio-ekonomskim istraživanjima). Međutim, s velikim N (N → ∞) formule za neponovljiv odabiri se približavaju onima za ponovljeno odabir i gotovo češće se koriste potonji ( N = konst).
Glavne karakteristike parametara opće i uzorkovane populacije
Statistički zaključci istraživanja temelje se na distribuciji slučajne varijable, dok su promatrane vrijednosti (x 1, x 2, ..., x n) nazivaju se realizacijama slučajne varijable NS(n je veličina uzorka). Distribucija slučajne varijable u općoj populaciji je teoretska, idealna i njen uzorak analog je empirijski distribucija. Neke teorijske distribucije date su analitički, tj. njihove opcije odrediti vrijednost funkcije distribucije u svakoj točki prostora mogućih vrijednosti slučajne varijable. Za uzorak je funkciju distribucije teško odrediti, a ponekad je i nemoguće opcije procijenjene iz empirijskih podataka, a zatim se zamjenjuju u analitički izraz koji opisuje teorijsku raspodjelu. U ovom slučaju, pretpostavka (ili hipoteza) o vrsti distribucije može biti i statistički ispravno i pogrešno. No, u svakom slučaju, empirijska distribucija rekonstruirana iz uzorka samo približno karakterizira pravu. Najvažniji parametri distribucije su očekivana vrijednost i varijansa.
Po svojoj prirodi distribucije jesu kontinuirano i diskretno... Najpoznatija kontinuirana distribucija je normalno... Selektivni analozi parametara i za njega su: srednja vrijednost i empirijska varijansa. Među diskretnim u društveno-ekonomskim istraživanjima, najčešće se koriste alternativno (dihotomično) distribucija. Parametar matematičkog očekivanja ove distribucije izražava relativnu vrijednost (ili dijeliti) jedinice populacije koje imaju proučavanu osobinu (označeno je slovom); udio stanovništva koji nema ovu karakteristiku označen je slovom q (q = 1 - p)... Varijanta alternativne distribucije također ima empirijski analog.
Karakteristike parametara distribucije izračunavaju se na različite načine, ovisno o vrsti distribucije i načinu odabira jedinica populacije. Glavni za teorijske i empirijske distribucije dani su u tablici. 1.
Uzorak k n je omjer broja jedinica uzorka i broja jedinica opće populacije:
k n = n / N.
Uzorak frakcije w Je odnos jedinica sa proučavanom osobinom x na veličinu uzorka n:
w = n n / n.
Primjer. U seriji robe koja sadrži 1000 jedinica, sa uzorkom od 5% uzorak uzorka k n u apsolutnoj vrijednosti je 50 jedinica. (n = N * 0,05); ako su u ovom uzorku pronađena 2 neispravna proizvoda, tada selektivna stopa otpada w bit će 0,04 (w = 2/50 = 0,04 ili 4%).
S obzirom da se uzorkovana populacija razlikuje od opće populacije, onda greške uzorkovanja.
Tablica 1. Osnovni parametri opće i uzorčne populacije
Greške uzorkovanja
Za sve (čvrste i selektivne) greške mogu se pojaviti dvije vrste: registracija i reprezentativnost. Greške registracija može imati nasumično i sistematično karakter. Slučajno greške se sastoje od mnogo različitih nekontrolisanih uzroka, nenamjerne su i obično se međusobno balansiraju (na primjer, promjene očitanja instrumenta tokom fluktuacija temperature u prostoriji).
Sistematično greške su tendenciozne, jer krše pravila za odabir objekata u uzorku (na primjer, odstupanja u mjerenjima pri promjeni postavki mjernog uređaja).
Primjer. Za procjenu društvenog statusa stanovništva u gradu planirano je ispitivanje 25% porodica. Ako se istovremeno izbor svakog četvrtog stana temelji na njegovom broju, postoji opasnost od odabira svih stanova samo jedne vrste (na primjer, jednosobnih stanova), što će donijeti sustavnu grešku i iskriviti rezultati; odabir broja stana prema žrijebu je poželjniji jer će greška biti slučajna.
Reprezentativne greške inherentni su samo selektivnom promatranju, ne mogu se izbjeći i nastaju kao posljedica činjenice da uzorak ne reproducira u potpunosti opću populaciju. Vrijednosti pokazatelja dobivenih iz uzorka razlikuju se od pokazatelja istih vrijednosti u općoj populaciji (ili dobivenih stalnim promatranjem).
Greška posmatranja uzorka je razlika između vrijednosti parametra u općoj populaciji i njegove vrijednosti uzorka. Za prosječnu vrijednost kvantitativne karakteristike jednaka je :, a za dionicu (alternativna karakteristika) -.
Greške uzorkovanja karakteristične su samo za posmatranja uzorka. Što su ove greške veće, empirijska distribucija se razlikuje od teorijske. Parametri empirijske distribucije su slučajne vrijednosti, stoga su greške uzorkovanja također slučajne vrijednosti, mogu uzeti različite vrijednosti za različite uzorke, pa je uobičajeno izračunati prosečna greška.
Prosječna greška uzorkovanja postoji vrijednost koja izražava standardnu devijaciju srednje vrijednosti uzorka od matematičkog očekivanja. Ova vrijednost, podložna principu slučajnog odabira, prvenstveno ovisi o veličini uzorka i o stupnju varijacije obilježja: što je veća i manja varijacija obilježja (a time i vrijednost), to je manja vrijednost prosječna greška uzorkovanja. Omjer varijansi opće populacije i uzorka izražen je formulom:
one. za dovoljno velike, možemo pretpostaviti da. Prosječna greška uzorkovanja pokazuje moguća odstupanja parametra uzorkovane populacije od parametra opće populacije. Tablica 2 prikazuje izraze za izračunavanje prosječne greške uzorkovanja za različite metode organizacije promatranja.
Tabela 2. Srednja greška (m) prosječne vrijednosti i proporcije uzorka za različite vrste uzorka
Gdje je prosjek varijansi uzorka unutar grupe za kontinuiranu karakteristiku;
Prosjek odstupanja udjela unutar grupe;
- broj odabranih serija, - ukupan broj serija;
 ,
,
gdje je prosjek -te serije;
- ukupni prosjek za cijeli uzorak za kontinuiranu karakteristiku;
 ,
,
gdje je udio obilježja u seriji;
- ukupni udio obilježja u cijelom uzorku.
Međutim, vrijednost prosječne greške može se procijeniti samo s određenom vjerovatnoćom P (P ≤ 1). Lyapunov A.M. dokazao je da raspodjela uzorka znači, a time i njihova odstupanja od općeg prosjeka, za dovoljno veliki broj približno poštuje normalni zakon distribucije, pod uvjetom da opća populacija ima konačan prosjek i ograničenu varijansu.
Matematički, ova tvrdnja za srednju vrijednost izražena je kao:

a za razlomak izraz (1) će imati oblik:
gdje  -
tu je marginalna greška uzorkovanja, koji je višestruki od srednje greške uzorkovanja ,
a faktor višestrukosti je Studentov test ("faktor povjerenja") koji su predložile SAD. Gosset (alias "Student"); vrijednosti za različite veličine uzoraka pohranjene su u posebnoj tablici.
-
tu je marginalna greška uzorkovanja, koji je višestruki od srednje greške uzorkovanja ,
a faktor višestrukosti je Studentov test ("faktor povjerenja") koji su predložile SAD. Gosset (alias "Student"); vrijednosti za različite veličine uzoraka pohranjene su u posebnoj tablici.

Stoga se izraz (3) može pročitati na sljedeći način: s vjerovatnoćom P = 0,683 (68,3%) može se tvrditi da razlika između uzorka i opće srednje vrijednosti neće premašiti jednu vrijednost srednje greške m (t = 1), sa vjerovatnoćom P = 0,954 (95,4%)- da neće premašiti vrijednost dvije srednje greške m (t = 2), sa verovatnoćom P = 0,997 (99,7%)- neće premašiti tri vrijednosti m (t = 3). Dakle, određuje se vjerovatnoća da će ta razlika premašiti tri puta veću grešku nivo greške i više ga nema 0,3% .
Tablica 3 prikazuje formule za izračunavanje granične greške uzorkovanja.
Tabela 3. Granična greška (D) uzorka za srednju vrijednost i proporciju (p) za različite vrste posmatranja uzorka
Distribucija rezultata uzorka na opću populaciju
Krajnji cilj selektivnog promatranja je okarakterizirati opću populaciju. Za male veličine uzorka, empirijske procjene parametara (i) mogu značajno odstupati od njihovih pravih vrijednosti (i). Stoga postaje potrebno utvrditi granice unutar kojih leže prave vrijednosti (i) za vrijednosti uzoraka parametara (i).
Interval povjerenja bilo kojeg parametra θ opće populacije naziva se slučajni raspon vrijednosti ovog parametra, koji je s vjerojatnošću blizu 1 ( pouzdanost) sadrži pravu vrijednost ovog parametra.
Marginalna greška uzorkovanje Δ omogućuje vam da odredite granične vrijednosti karakteristika opće populacije i njihovih intervali povjerenja koje su jednake:
Zaključak interval povjerenja dobijeno oduzimanjem marginalna greška iz uzorka srednja vrijednost (udio), a gornja dodavanjem.
Interval povjerenja u prosjeku koristi graničnu grešku uzorkovanja i za dati nivo pouzdanosti određuje se formulom:
To znači da sa zadanom vjerovatnoćom R, koji se naziva nivo pouzdanosti i jedinstveno je određen vrijednošću t, može se tvrditi da se prava vrijednost srednje vrijednosti nalazi u rasponu od ![]() , a prava vrijednost frakcije je u rasponu od
, a prava vrijednost frakcije je u rasponu od
Prilikom izračunavanja intervala pouzdanosti za tri standardna nivoa pouzdanosti P = 95%, P = 99% i P = 99,9% vrijednost je odabrana pomoću. Prijave ovisno o broju stupnjeva slobode. Ako je veličina uzorka dovoljno velika, tada vrijednosti odgovaraju tim vjerovatnoćama t su jednaki: 1,96, 2,58 i 3,29 ... Dakle, marginalna greška uzorkovanja omogućuje određivanje graničnih vrijednosti karakteristika opće populacije i njihovih intervala pouzdanosti:
Raspodjela rezultata selektivnog promatranja na opću populaciju u socio-ekonomskim istraživanjima ima svoje karakteristike, jer zahtijeva potpunost reprezentativnosti svih njegovih tipova i grupa. Osnova za mogućnost takve distribucije je proračun relativna greška:

gdje Δ % - relativna marginalna greška uzorkovanja; ,.
Postoje dvije glavne metode proširenja uzorkovanja na opću populaciju: direktna konverzija i metoda koeficijenata.
Suština direktna konverzija sastoji se u množenju prosjeka uzorka !! \ overline (x) s veličinom opće populacije.
Primjer... Neka se prosječan broj male djece u gradu procijeni metodom uzorka i neka bude osoba. Ako u gradu ima 1000 mladih porodica, broj potrebnih mjesta u rasadnicima dobiva se množenjem ovog prosjeka s veličinom opće populacije N = 1000, tj. iznosit će 1200 mjesta.
Metoda kvota preporučljivo je koristiti u slučaju kada se vrši selektivno promatranje radi pojašnjavanja podataka kontinuiranog promatranja.
U ovom slučaju koristi se formula:
gdje su sve varijable veličina populacije:
Potrebna veličina uzorka
Tabela 4. Potrebna veličina uzorka (n) za različite vrste organizacije posmatranja uzorka
Prilikom planiranja uzorkovanja s unaprijed određenom vrijednošću dopuštene greške uzorkovanja, potrebno je ispravno procijeniti traženu vrijednost veličina uzorka... Ovaj volumen se može odrediti na osnovu dozvoljene greške u opservaciji na osnovu date vjerovatnoće koja garantuje dozvoljenu vrijednost nivoa greške (uzimajući u obzir način organizacije posmatranja). Formule za određivanje potrebne veličine uzorka n lako se mogu dobiti direktno iz formula za marginalnu grešku uzorkovanja. Dakle, iz izraza marginalne greške:
veličina uzorka se direktno određuje n:
Ova formula pokazuje da sa smanjenjem granične greške uzorkovanja Δ potrebna veličina uzorka značajno se povećava, što je proporcionalno varijansi i kvadratu Studentovog testa.
Za specifičan način organiziranja promatranja potrebna veličina uzorka izračunava se prema formulama danim u tablici. 9.4.
Praktični primjeri proračuna
Primjer 1. Izračun srednje vrijednosti i intervala pouzdanosti za kontinuiranu kvantitativnu karakteristiku.
Kako bi procijenila brzinu namire s vjerovnicima, banka je izvršila nasumični uzorak od 10 platnih dokumenata. Pokazalo se da su njihove vrijednosti jednake (u danima): 10; 3; 15; 15; 22; 7; osam; 1; 19; dvadeset.
Neophodno sa verovatnoćom P = 0,954 odrediti graničnu grešku Δ granice uzoraka i granice pouzdanosti srednjeg vremena proračuna.
Rešenje. Prosječna vrijednost izračunava se formulom iz tablice. 9.1 za uzorak
![]()
Varijansa se izračunava formulom iz tabele. 9.1.
![]()
Srednja kvadratna greška dana.
Srednja greška se izračunava formulom:
![]()
one. prosjek je x ± m = 12,0 ± 2,3 dana.
Pouzdanost srednje vrijednosti bila je
![]()
Granična greška izračunava se formulom iz tablice. 9.3 za ponovno uzorkovanje, budući da je veličina populacije nepoznata, i za P = 0,954 nivo samopouzdanja.
Tako je prosječna vrijednost jednaka `x ± D =` x ± 2m = 12,0 ± 4,6, tj. njegova prava vrijednost kreće se od 7,4 do 16,6 dana.
Korištenje učeničke tablice. Aplikacija nam omogućava da zaključimo da je za n = 10 - 1 = 9 stepeni slobode, dobivena vrijednost pouzdana sa nivoom značajnosti od 0,001 £, tj. dobivena srednja vrijednost značajno se razlikuje od 0.
Primjer 2. Procjena vjerovatnoće (opći udio) str.
Metodom mehaničkog uzorkovanja istraživanja društvenog statusa 1000 porodica otkriveno je da je udio porodica sa niskim prihodima bio w = 0,3 (30%)(uzorak je bio 2% , tj. n / N = 0,02). Potrebno sa određenim nivoom samopouzdanja p = 0,997 odredite indikator R porodice sa niskim prihodima u celom regionu.
Rešenje. Prema prikazanim vrijednostima funkcije F (t) pronaći za dati nivo povjerenja P = 0,997 značenje t = 3(vidi formulu 3). Greška graničnog udjela w određeno formulom iz tabele. 9.3 za uzorke koji se ne ponavljaju (mehaničko uzorkovanje se uvijek ne ponavlja):
Marginalna relativna greška uzorkovanja u % bice:
Vjerovatnoća (opći udio) porodica sa niskim prihodima u regionu će biti p = w ± Δ w, a granice pouzdanosti p izračunavaju se na osnovu dvostruke nejednakosti:
w - Δ w ≤ p ≤ w - Δ w, tj. prava vrijednost p leži u:
0,3 — 0,014 < p <0,3 + 0,014, а именно от 28,6% до 31,4%.
Dakle, sa vjerovatnoćom od 0,997, može se tvrditi da se udio porodica sa niskim primanjima među svim porodicama u regionu kreće od 28,6% do 31,4%.
Primjer 3. Izračunavanje srednje vrijednosti i intervala pouzdanosti za diskretno svojstvo specificirano intervalskim nizom.
Tablica 5. postavljena je distribucija naloga za izradu naloga prema vremenu izvršenja od strane preduzeća.
Tablica 5. Raspodjela opažanja prema vremenu pojavljivanjaRešenje. Prosječno vrijeme izvršenja naloga izračunava se po formuli:
Prosječan period bit će:
= (3 * 20 + 9 * 80 + 24 * 60 + 48 * 20 + 72 * 20) / 200 = 23,1 mjeseci.
Isti odgovor dobivamo ako koristimo podatke na p i iz pretposljednje kolone tabele. 9.5 koristeći formulu:
Imajte na umu da se sredina intervala za posljednju gradaciju nalazi umjetnim dopunjavanjem širine intervala prethodne gradacije jednake 60 - 36 = 24 mjeseca.
Varijansa se izračunava prema formuli
![]()
gdje x i- sredina reda intervala.
Stoga !! \ sigma = \ frac (20 ^ 2 + 14 ^ 2 + 1 + 25 ^ 2 + 49 ^ 2) (4), a korijen srednje greške.
Prosječna greška se izračunava pomoću mjesečne formule, tj. srednja vrijednost je !! \ overline (x) ± m = 23,1 ± 13,4.
Granična greška izračunava se formulom iz tablice. 9.3 za ponovno uzorkovanje, budući da je veličina populacije nepoznata, za nivo pouzdanosti 0,954:
Dakle, prosjek je:
one. njegova prava vrijednost kreće se od 0 do 50 mjeseci.
Primjer 4. Da bi se utvrdila brzina poravnanja s povjeriocima N = 500 preduzeća korporacije u poslovnoj banci, potrebno je provesti uzorkovanje metodom slučajnog neponovljenog odabira. Odredite potrebnu veličinu uzorka n tako da, s vjerovatnoćom P = 0,954, greška srednje vrijednosti uzorka ne prelazi 3 dana, ako su procjene ispitivanja pokazale da je standardna devijacija s bila 10 dana.
Rešenje... Za određivanje broja potrebnih studija n, upotrijebit ćemo formulu za ponovljeni odabir iz tablice. 9.4:

U njemu se vrijednost t određuje iz za nivo pouzdanosti P = 0,954. Jednako je 2. Korijen srednje kvadrature s = 10, veličina opće populacije je N = 500, a granična greška srednje vrijednosti je Δ x = 3. Zamjenom ovih vrijednosti u formulu dobivamo:
![]()
one. dovoljno je napraviti uzorak od 41 preduzeća kako bi se procijenio traženi parametar - brzina poravnanja s povjeriocima.
Uzorak - ovo je:
1) ukupnost onih elemenata istraživačkog objekta koji će se direktno proučavati;
2) metode i postupci za odabir elemenata istraživačkog objekta.
Opšta populacija - kompletan skup objekata koji se odnose na problem koji se proučava. U sociološkim istraživanjima kao G.S. najčešće postoje agregati pojedinaca - stanovništvo (gradovi, zemlje itd.), društvena grupa (mladi, nezaposleni, poslovni ljudi itd.), publika masovnih medija (QMS) itd. Međutim, u mnogim slučajevima , GS ... mogu se sastojati od većih elemenata (objekata) - porodica (domaćinstava), akademskih grupa, preduzeća, vjerskih zajednica, pojedinačnih naselja ili država itd.
Uzorak populacije - dio objekata iz opće populacije odabranih za proučavanje radi donošenja zaključka o čitavoj općoj populaciji.
Da bi se zaključak dobiven ispitivanjem uzorka proširio na cijelu opću populaciju, uzorak mora imati svojstvo reprezentativnosti.
Reprezentativnost Je li sposobnost uzorka da predstavlja ciljnu populaciju. Što preciznije sastav uzorka predstavlja populaciju po pitanjima koja se proučavaju, to je veća njegova reprezentativnost.
PRIMJER: Reprezentativnost se može ilustrirati sljedećim primjerom. Pretpostavimo da su svi učenici učenici jedne škole (600 ljudi iz 20 odjeljenja, 30 ljudi u svakom odjeljenju). Predmet istraživanja su stavovi prema pušenju. Uzorak od 60 srednjoškolaca predstavlja mnogo lošiju populaciju od uzorka istih 60 učenika, koji će uključivati 3 učenika iz svakog razreda. Glavni razlog za to je nejednaka dobna raspodjela u odjeljenjima. Slijedom toga, u prvom slučaju reprezentativnost uzorka je niska, au drugom slučaju reprezentativnost je visoka (sve ostale stvari su jednake).
Tipovi uzoraka
1.Slučajno uzorkovanje.
1.1 Jednostavan slučajan odabir.
1.2 Metoda sistematskog (ili mehaničkog) uzorkovanja.
1.3 Serijsko (ugniježđeno ili grupirano) uzorkovanje.
1.4 Stratifikovani uzorak.
2. Neslučajan uzorak (nevjerovatno).
2.2. Spontano uzorkovanje.
2.3. Višestepeno i jednostepeno uzorkovanje.
1.Slučajno uzorkovanje.
Posebnost slučajnog uzorkovanja je u tome što sve jedinice opće populacije imaju jednaku vjerojatnost da budu uključene u uzorak. Nasumičnim uzorkovanjem, princip slučajnosti... Okvir za uzorkovanje može biti spisak zaposlenih u preduzeću, telefonski imenici, registracioni spiskovi vlasnika automobila, spiskovi birača na biračkim mjestima, kućne knjige, kao i različiti spiskovi koje je sastavio sam sociolog, ovisno o ciljevima studije (lista ulice na kojima se zatim biraju ispitanici).
Slučajno uzorkovanje obično se koristi u istraživanjima javnog mnijenja prije izbora, referenduma i drugih javnih događaja.
Plus Ova metoda je potpuno poštivanje principa slučajnosti i, kao posljedica, izbjegavanje sistemskih grešaka.
Nedostaci ove metode:
- Potreba za popisom elemenata opće populacije.
- Složenost istraživanja.
- Relativno velika veličina uzorka.
U statistici postoje dvije glavne metode istraživanja - kontinuirana i selektivna. Prilikom provođenja studije uzorka, potrebno je pridržavati se sljedećih zahtjeva: reprezentativnosti uzorka i dovoljnog broja jedinica posmatranja. Prilikom odabira mjernih jedinica moguće je Greške pomaka, odnosno takve događaje čija se pojava ne može precizno predvidjeti. Ove greške su objektivne i prirodne. Prilikom određivanja stepena tačnosti studije uzorkovanja, procjenjuje se iznos greške koja se može pojaviti tokom procesa uzorkovanja - Slučajna greška reprezentativnosti (M) — To je stvarna razlika između prosječnih ili relativnih vrijednosti dobivenih u uzorku i sličnih vrijednosti koja bi se mogla dobiti u anketi o općoj populaciji.
Procjena pouzdanosti rezultata istraživanja uključuje utvrđivanje:
1. greške reprezentativnosti
2. granice povjerenja srednjih (ili relativnih) vrijednosti u općoj populaciji
3. povjerenje razlike između srednjih (ili relativnih) vrijednosti (prema kriterijumu t)
Proračun greške reprezentativnosti(mm) aritmetička sredina (M):
Gdje je σ standardna devijacija; n je veličina uzorka (> 30).
Proračun greške reprezentativnosti (mR) relativne vrijednosti (R):
Gdje je P odgovarajuća relativna vrijednost (izračunata, na primjer, u%);
Q = 100 - Ρ% je recipročna vrijednost P; n - veličina uzorka (n> 30)
U kliničkom i eksperimentalnom radu često je potrebno koristiti Mali uzorak, Kada je broj opažanja manji ili jednak 30. Uz mali uzorak za izračunavanje grešaka reprezentativnosti, i srednje i relativne vrijednosti , Broj opažanja se smanjuje za jedan, tj.
![]() ; .
; .
Veličina greške reprezentativnosti ovisi o veličini uzorka: što je veći broj opažanja, to je manja greška. Kako bi se procijenila pouzdanost uzorka pokazatelja, usvojen je sljedeći pristup: pokazatelj (ili prosječna vrijednost) mora biti 3 puta veći od njegove greške, u ovom slučaju se smatra pouzdanim.
Poznavanje veličine greške nije dovoljno da biste bili sigurni u rezultate studije uzorkovanja, budući da specifična greška studije uzorkovanja može biti znatno veća (ili manja) od vrijednosti srednje greške reprezentativnosti. Kako bi se utvrdilo s kojom točnošću istraživač želi postići rezultat, statistika koristi takav koncept kao vjerojatnost predviđanja bez grešaka, što je karakteristika pouzdanosti rezultata selektivnih biomedicinskih statističkih studija. Obično se pri provođenju biomedicinskih statističkih studija koristi vjerojatnost predviđanja bez grešaka od 95% ili 99%. U najkritičnijim slučajevima, kada je potrebno izvesti posebno važne zaključke u teorijskom ili praktičnom smislu, koristi se vjerojatnost prognoze bez grešaka od 99,7%.
Određeni stupanj vjerovatnoće prognoze bez grešaka odgovara određenoj vrijednosti Marginalna greška slučajnog uzorkovanja (Δ - delta), koji je određen formulom:
Δ = t * m, gdje je t koeficijent pouzdanosti, koji za veliki uzorak sa 95% vjerovatnoće predviđanja bez grešaka iznosi 2,6; sa vjerovatnoćom prognoze bez grešaka od 99% - 3,0; sa vjerovatnoćom prognoze bez grešaka od 99,7% - 3,3, a sa malim uzorkom određena je posebnom tabelom Studentovih t vrijednosti.
Koristeći marginalnu grešku uzorkovanja (Δ), može se utvrditi Granice povjerenja, u kojem je, uz određenu vjerojatnost prognoze bez grešaka, stvarna vrijednost statističke veličine , Karakteriše cijelu opštu populaciju (prosječnu ili relativnu).
Za određivanje granica povjerenja koriste se sljedeće formule:
1) za prosječne vrijednosti:
Gdje je Mgen - granice povjerenja prosjeka u općoj populaciji;
Uzorak - prosjek , Dobiveno prilikom provođenja studije na uzorku populacije; t je koeficijent povjerenja čija je vrijednost određena stepenom vjerovatnoće prognoze bez grešaka s kojom istraživač želi dobiti rezultat; mM je greška reprezentativnosti srednje vrijednosti.
2) za relativne vrijednosti:
Gdje je Pgen - granice pouzdanosti relativne vrijednosti u općoj populaciji; Psyb - relativna vrijednost dobivena provođenjem studije na uzorku populacije; t faktor povjerenja; mP - greška reprezentativnosti relativne vrijednosti.
Granice povjerenja pokazuju u kojoj mjeri veličina uzorka može varirati ovisno o slučajnim razlozima.
Uz mali broj zapažanja (br<30), для вычисления доверительных границ значение коэффициента t находят по специальной таблице Стьюдента. Значения t расположены в таблице на пересечении с избранной вероятностью безошибочного прогноза и строки, Navođenje broja dostupnih stepena slobode (n) , Što je n-1.
Zapravo, počet ćemo s ne jednim, već s tri pitanja: Što je uzorkovanje? kada je reprezentativan? šta je?
Agregat Je li neka grupa ljudi, organizacija, događaja koji nas zanimaju, o kojima želimo donijeti zaključke, i dešava se, ili objekt, - bilo koji element takvog skupa 1 .Uzorak - bilo koju podgrupu skupa predmeta (objekata) dodijeljenih za analizu. Ako želimo proučavati aktivnosti donošenja odluka državnih zakonodavaca, mogli bismo istražiti takve aktivnosti u zakonodavnim tijelima država Virginia, North Carolina i South Carolina, a ne u svih pedeset država i, na temelju toga, raširiti podaci dobiveni za populaciju iz koje su odabrane ove tri države. Ako želimo istražiti sistem preferencija glasača u Pennsylvaniji, mogli bismo to učiniti intervjuiranjem 50 radnika u Yu. S. Steele ”u Pittsburghu i distribuirati rezultate ankete svim biračima u državi. Slično, ako želimo mjeriti inteligenciju studenata, mogli bismo testirati sve odbrambene igrače Ohaja za datu fudbalsku sezonu, a zatim generalizirati rezultate na populaciju čiji su dio. U svakom primjeru postupamo na sljedeći način: radije uspostavljamo podgrupu unutar populacije detaljno proučavamo ovu podgrupu ili uzorak i proširujemo naše rezultate na cijelu populaciju. Ovo su glavne faze uzorkovanja.
Međutim, čini se sasvim očitim da svaki od ovih uzoraka ima značajan nedostatak. Na primjer, iako su zakonodavna tijela Virdžinije, Sjeverne Karoline i Južne Karoline dio agregata državnih zakonodavnih tijela, iz povijesnih, geografskih i političkih razloga, oni će vjerojatno djelovati na vrlo slične i vrlo različite načine od zakonodavnih tijela koja se toliko razlikuju od države poput New Yorka, Nebraske i Aljaske. Dok pedeset željezara u Pittsburghu zaista mogu biti glasači u Pennsylvaniji, njihov socioekonomski status, obrazovanje i životno iskustvo vjerovatno će imati drugačija gledišta od onih mnogih sličnih glasača. Slično, iako su fudbaleri Ohaja studenti, oni se mogu razlikovati od drugih studenata iz različitih razloga. Drugim riječima, iako je svaka od ovih podgrupa zaista uzorak, članovi svake od njih sustavno se razlikuju od većine ostatka populacije iz koje su odabrani. Kao zasebna grupa, nijedna od njih nije tipična u pogledu raspodjele atributa mišljenja, motiva ponašanja i karakteristika u općoj populaciji s kojom je povezana. U skladu s tim, politikolozi bi rekli da nijedan od ovih uzoraka nije reprezentativan.
Reprezentativni uzorak - ovo je uzorak u kojem su sve glavne karakteristike opće populacije iz koje je izdvojen ovaj uzorak predstavljene približno u istom omjeru ili s istom učestalošću s kojom se ovo obilježje pojavljuje u ovoj općoj populaciji. Dakle, ako se 50% svih državnih zakonodavnih tijela sastaje samo svake dvije godine, otprilike polovica reprezentativnog uzorka državnih zakonodavnih tijela trebala bi biti ove vrste. Ako je 30% glasača u Pensilvaniji plavih ovratnika, oko 30% predstavnika uzorci za ove birače (ne 100% kao u gornjem primjeru) trebaju biti plavi ovratnici. A ako su 2% svih studenata sportisti, otprilike isti dio reprezentativnog uzorka studenata trebali bi biti sportaši. Drugim riječima, reprezentativan uzorak je mikrokosmos, manji, ali precizan model populacije koji bi trebao predstavljati. U mjeri u kojoj je uzorak reprezentativan, može se sa sigurnošću pretpostaviti da se zaključci izvedeni iz istraživanja tog uzorka primjenjuju na izvornu populaciju. Ovo širenje rezultata nazivamo generalizacijom.
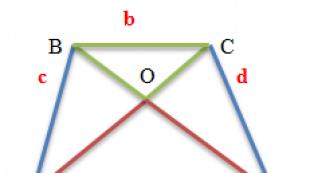
Možda će grafička ilustracija ovo pojasniti. Pretpostavimo da želimo proučiti obrasce članstva u političkim grupama među odraslim stanovništvom SAD -a. Slika 5.1 prikazuje tri kruga, podijeljena u šest jednakih sektora. Slika 5.1a prikazuje cijelu populaciju koja se razmatra. Pripadnici stanovništva klasificirani su prema političkim grupama (poput stranaka i interesnih grupa) kojima pripadaju. U ovom primjeru, svaka odrasla osoba pripada najmanje jednoj, a ne više od šest političkih grupa; i ovih šest nivoa članstva su podjednako uobičajeni u agregatu (dakle jednaki sektori). Pretpostavimo da želimo istražiti motive pridruživanja ljudi grupi, izbor grupe i obrasce učešća, međutim, zbog ograničenih resursa, u mogućnosti smo ispitati samo jednog od svakih šest članova populacije. Koga treba izabrati za analizu?
Pirinač. 5.1. Uzorkovanje iz opće populacije
Jedan od mogućih uzoraka date veličine ilustriran je zasjenjenom površinom na slici 5.1b, ali ne odražava jasno strukturu populacije. Ako bismo generalizirali iz ovog uzorka, zaključili bismo (1) da svi odrasli Amerikanci pripadaju pet političkih grupa, i (2) da se sve ponašanje američkih grupa podudara s ponašanjem onih u točno pet grupa. Međutim, znamo da prvi zaključak nije točan, pa nam to može stvoriti sumnju u valjanost drugog. Dakle, Uzorak prikazan na slici 5.1b nije reprezentativan jer ne odražava distribuciju date populacijske imovine (često se naziva) parametar ) u skladu sa njegovom stvarnom distribucijom. Za takav uzorak se kaže da je pomeren kačlanovi pet grupa ili odmaknuo od sve ostale modele članstva u grupi. Na osnovu tako pristrasnog uzorka, skloni smo donositi pogrešne zaključke o populaciji.
To se najjasnije može pokazati primjerom katastrofe koja je tridesetih godina prošlog stoljeća zadesila časopis Literary Digest koji je organizirao ispitivanje javnog mnijenja o izbornim rezultatima. Literary Digest bio je periodični časopis u kojem su se ponovo štampali uvodnici iz novina i drugi materijali koji odražavaju javno mnijenje; ovaj je časopis bio vrlo popularan početkom stoljeća. Počevši od 1920. godine, časopis je sproveo opsežnu anketu u cijeloj zemlji, u kojoj je više od milion ljudi poslano putem glasačkih listića, tražeći od njih da naznače čiju kandidaturu preferiraju za predstojeće predsjedničke izbore. Tokom godina, rezultati ankete časopisa bili su toliko tačni da se činilo da je septembarska anketa činila novembarske izbore malo relevantnim. I kako je mogla doći do greške u tako velikom uzorku? Međutim, 1936. godine dogodilo se upravo to: velikom većinom glasova (60:40) predviđena je pobjeda republikanskog kandidata Alfa Landona. Na izborima je Landon izgubio od osobe s invaliditetom - Franklin D. Roosevelt - s praktično istim rezultatom s kojim je trebao pobijediti. Kredibilitet "Literarnog sažetka" bio je toliko ozbiljno narušen da je ubrzo nakon toga časopis prestao izlaziti. Šta se desilo? Jednostavno, istraživanje Digest -a koristilo je pristrasan uzorak. Razglednice su slane ljudima čija su imena izvučena iz dva izvora: telefonskih imenika i lista registracija automobila. I premda se ovaj način odabira nije mnogo razlikovao od drugih metoda prije, situacija je bila potpuno drugačija sada, za vrijeme Velike depresije 1936. godine, kada manje bogati glasači, najvjerojatnije oslonac Roosevelta, nisu mogli priuštiti da imaju telefon, a kamoli auto. Tako je, u stvari, uzorak korišten u istraživanju Digest bio pristrasan prema onima koji će najvjerovatnije biti republikanci, pa je i dalje iznenađujuće da je Roosevelt imao tako dobar rezultat.
Kako se ovaj problem može riješiti? Vraćajući se na naš primjer, usporedite uzorak na slici 5.1b sa uzorkom na slici 5.1c. U potonjem slučaju, šestina populacije je također odabrana za analizu, ali je svaki od glavnih tipova populacije predstavljen u uzorku u omjeru u kojem je zastupljen u cijeloj populaciji. Ovaj uzorak pokazuje da svaki šesti odrasli Amerikanac pripada jednoj političkoj grupi, jedan od šest do dva, itd. Takvo uzorkovanje će otkriti i druge razlike među njegovim članovima koje bi mogle biti povezane sa učešćem u različitom broju grupa. Dakle, uzorak prikazan na slici 5.1c reprezentativan je uzorak za razmatranu populaciju.
Naravno, ovaj primjer je pojednostavljen s najmanje dva izuzetno važna gledišta. Prvo, većina populacija koje zanimaju politikologe raznovrsnija je od one prikazane u primjeru. Ljudi, dokumenti, vlade, organizacije, odluke itd. međusobno se razlikuju ne po jednom, već po mnogo većem broju znakova. Stoga bi reprezentativan uzorak trebao biti takav svaki glavnog, različitog od ostalih područja bila je predstavljeno proporcionalno njegovom udjelu u agregatu. Drugo, situacija kada se stvarna distribucija varijabli ili karakteristika koje želimo mjeriti nije unaprijed poznata, događa se mnogo češće nego suprotno - možda nije mjerena u prethodnom popisu. Stoga bi reprezentativni uzorak trebao biti dizajniran tako da može točno odražavati postojeću distribuciju čak i kada nismo u mogućnosti izravno procijeniti njegovu valjanost. Postupak uzorkovanja mora imati internu logiku koja nas može uvjeriti da bi, ako bismo mogli uporediti uzorak sa popisom, doista bio reprezentativan.
Kako bi se osiguralo da se složena organizacija određene populacije može točno odraziti i imati određeni stepen povjerenja da su predložene procedure u stanju to učiniti, istraživači se okreću statističkim metodama. Međutim, djeluju u dva smjera. Prvo, koristeći određena pravila (interna logika), istraživači odlučuju o pitanju koje bi konkretne objekte trebali proučavati, što bi točno trebalo uključiti u određeni uzorak. Drugo, koristeći vrlo različita pravila, oni odlučuju koliko će objekata odabrati. Nećemo detaljno proučavati ova brojna pravila, razmotrit ćemo samo njihovu ulogu u istraživanju političkih nauka. Počnimo sa strategijama za odabir objekata koji čine reprezentativan uzorak.