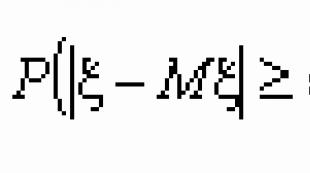Praktična uporaba zakona velikih števil. Zakon velikih števil. Mejni izreki. Lastnosti porazdelitvene funkcije
Praksa preučevanja naključnih pojavov kaže, da čeprav se rezultati posameznih opazovanj, tudi tistih, izvedenih pod enakimi pogoji, lahko zelo razlikujejo, so hkrati povprečni rezultati za dovolj veliko število opazovanj stabilni in šibko odvisni od rezultati posameznih opazovanj.
Teoretična podlaga za to izjemno lastnost naključnih pojavov je zakon velikih števil. Ime "zakon velikih števil" združuje skupino izrekov, ki ugotavljajo stabilnost povprečnih rezultatov velikega števila naključnih pojavov in pojasnjujejo razlog za to stabilnost.
Najenostavnejša oblika zakona velikih števil in zgodovinsko prvi izrek tega razdelka je Bernoullijev izrek, ki pravi, da če je verjetnost dogodka enaka v vseh poskusih, potem ko se število poskusov poveča, se pogostost dogodka nagiba k verjetnosti dogodka in preneha biti naključna.
Poissonov izrek pravi, da se pogostost dogodka v nizu neodvisnih poskusov nagiba k aritmetični sredini njegovih verjetnosti in preneha biti naključna.
Mejni izreki teorije verjetnosti, izreki Moivre-Laplace pojasni naravo stabilnosti pogostosti pojavljanja dogodka. Ta narava je v tem, da je mejna porazdelitev števila pojavov dogodka z neomejenim povečanjem števila poskusov (če je verjetnost dogodka enaka v vseh poskusih) normalna porazdelitev.
Centralni mejni izrek pojasnjuje razširjenost normalno pravo distribucije. Izrek pravi, da se porazdelitveni zakon te naključne spremenljivke praktično izkaže za normalno po zakonu.
Spodaj podan izrek z naslovom " Zakon velikih števil« navaja, da se pod določenimi, dokaj splošnimi pogoji, s povečanjem števila naključnih spremenljivk njihova aritmetična sredina nagiba k aritmetični sredini matematičnih pričakovanj in preneha biti naključna.
Lyapunovov izrek pojasnjuje razširjenost normalno pravo distribucijo in razloži mehanizem njenega nastanka. Izrek nam omogoča, da trdimo, da kadar koli naključna spremenljivka nastane kot rezultat dodajanja velikega števila neodvisnih naključnih spremenljivk, katerih variance so majhne v primerjavi z varianco vsote, se porazdelitveni zakon te naključne spremenljivke obrne praktično normalno po zakonu. In ker naključne spremenljivke vedno generira neskončno število vzrokov in največkrat nobeden od njih nima razpršenosti, primerljive z razpršenostjo same naključne spremenljivke, za večino naključnih spremenljivk, ki jih srečamo v praksi, velja normalni porazdelitveni zakon.
Kvalitativne in kvantitativne izjave zakona velikih števil temeljijo na Čebiševljeva neenakost. Določa zgornjo mejo verjetnosti, da je odstopanje vrednosti naključne spremenljivke od njenega matematičnega pričakovanja večje od določene določene številke. Zanimivo je, da Chebyshevljeva neenakost daje oceno verjetnosti dogodka za naključno spremenljivko, katere porazdelitev ni znana, sta znani le njeno matematično pričakovanje in varianca.
Čebiševljeva neenakost.Če ima naključna spremenljivka x varianco, potem za vsak e > 0 velja naslednja neenakost: ![]() , Kje M x in D x - matematično pričakovanje in varianca slučajne spremenljivke x.
, Kje M x in D x - matematično pričakovanje in varianca slučajne spremenljivke x.
Bernoullijev izrek. Naj bo m n število uspehov v n Bernoullijevih poskusih in p verjetnost uspeha v posameznem poskusu. Potem velja za vsak e > 0 ![]() .
.
Centralni mejni izrek.Če so naključne spremenljivke x 1 , x 2 , …, x n , … po parih neodvisne, enako porazdeljene in imajo končno varianco, potem za n ® enakomerno po x (- ,)
Kaj je skrivnost uspešnih prodajalcev? Če opazujete najboljše prodajalce v katerem koli podjetju, boste opazili, da imajo eno skupno stvar. Vsak od njih se sreča z več ljudmi in opravi več predstavitev kot manj uspešni prodajalci. Ti ljudje razumejo, da je prodaja igra številk in več ko ljudem povedo o svojih izdelkih ali storitvah, več poslov bodo sklenili – to je vse. Zavedajo se, da če bodo komunicirali ne le s tistimi redkimi, ki jim bodo zagotovo rekli da, ampak tudi s tistimi, katerih zanimanje za njihovo ponudbo ni tako veliko, bo zakon povprečja deloval njim v prid.
Vaš dohodek bo odvisen od števila prodaj, hkrati pa bo premosorazmeren s številom vaših predstavitev. Ko boste razumeli in izvajali zakon povprečij, se bo tesnoba, povezana z ustanovitvijo novega podjetja ali delom na novem področju, začela zmanjševati. Posledično se bosta začela krepiti občutek nadzora in zaupanje v vašo sposobnost služenja denarja. Če samo naredite predstavitve in med tem izpopolnite svoje veščine, bodo posli prišli.
Namesto da razmišljate o številu poslov, raje razmišljajte o številu predstavitev. Nima smisla, da se zjutraj zbudite ali zvečer pridete domov in se sprašujete, kdo bo kupil vaš izdelek. Namesto tega je najbolje, da načrtujete, koliko klicev morate opraviti vsak dan. In potem, ne glede na vse - opravite vse te klice! Ta pristop vam bo olajšal delo – saj gre za preprost in specifičen cilj. Če veste, da imate točno določen in dosegljiv cilj, boste lažje opravili načrtovano število klicev. Če med tem postopkom nekajkrat slišite "da", toliko bolje!
In če "ne", potem se boste zvečer počutili, da ste pošteno naredili vse, kar ste lahko, in vas ne bodo mučile misli o tem, koliko denarja ste zaslužili ali koliko spremljevalcev ste pridobili v enem dnevu.
Recimo, da v vašem podjetju ali podjetju povprečen prodajalec sklene en posel na štiri predstavitve. Zdaj pa si predstavljajte, da vlečete karte iz kompleta. Vsaka karta treh barv – pik, karo in palica – je predstavitev, v kateri strokovno predstavite izdelek, storitev ali priložnost. Delaš, kolikor zmoreš, pa vseeno ne skleneš posla. In vsaka srčna karta je dogovor, ki vam omogoča, da dobite denar ali pridobite novega spremljevalca.
Ali ne bi v takšni situaciji želeli potegniti čim več kart iz kompleta? Recimo, da vam ponudijo, da izvlečete toliko kart, kot želite, pri čemer vam plačajo ali vam ponudijo novega spremljevalca vsakič, ko izvlečete srčno karto. Navdušeno boste začeli risati karte in komaj opazili, kakšne barve je karta, ki ste jo pravkar izvlekli.
Veste, da je v kompletu dvainpetdesetih kart trinajst srčkov. In v dveh kompletih je šestindvajset srčnih kart in tako naprej. Boste razočarani, ko izvlečete pik, karo ali kif? Seveda ne! Mislili boste le, da vas vsaka taka “miss” približa čemu? Na srčno karto!
Ampak veš kaj? Tako ponudbo ste že dobili. Ste v edinstvenem položaju, da zaslužite toliko, kot želite, in narišete toliko src, kot jih želite narisati v svojem življenju. In če preprosto vestno »vlečete karte«, izpopolnjujete svoje sposobnosti in potrpite malo pika, karo in palice, boste postali odličen prodajalec in dosegli uspehe.
Ena od stvari, zaradi katerih je prodaja tako zabavna, je, da se vsakič, ko premešate komplet, karte premešajo drugače. Včasih se vsi srčki znajdejo na začetku krova in po srečnem nizu (ko se nam zdi, da nikoli ne bomo izgubili!) nas čaka dolga vrsta kart različnih barv. Drugič, da prideš do prvega srca, boš moral iti skozi neskončno število pik, kifov in karo. In včasih se karte različnih barv pojavljajo strogo po vrstnem redu. Toda v vsakem primeru je v vsakem kompletu dvainpetdesetih kart, v nekem vrstnem redu, vedno trinajst srčkov. Samo izvlecite karte, dokler jih ne najdete.
Od: Leylya,
Besede o velikih številkah se nanašajo na število testov - upošteva se veliko število vrednosti naključne spremenljivke ali kumulativni učinek velikega števila naključnih spremenljivk. Bistvo tega zakona je naslednje: čeprav je nemogoče napovedati, kakšno vrednost bo posamezna naključna spremenljivka zavzela v posameznem poskusu, pa skupni rezultat delovanja velikega števila neodvisnih naključnih spremenljivk izgubi svojo naključno naravo in lahko napovedati skoraj zanesljivo (tj. z veliko verjetnostjo). Na primer, nemogoče je predvideti, v katero smer bo pristal en kovanec. Če pa vržete 2 toni kovancev, lahko z veliko gotovostjo rečemo, da je teža kovancev, ki so padli z grbom navzgor, enaka 1 toni.
Zakon velikih števil se nanaša predvsem na tako imenovano Chebyshevljevo neenakost, ki z enim testom oceni verjetnost, da naključna spremenljivka sprejme vrednost, ki odstopa od povprečne vrednosti za največ dano vrednost.
Čebiševljeva neenakost. Pustiti X– poljubna naključna spremenljivka, a=M(X) , A D(X) – njeno varianco. Potem
Primer. Nazivna (t.j. zahtevana) vrednost premera tulca, vklopljenega na stroj, je enaka 5 mm, in disperzije ni več 0.01 (to je toleranca natančnosti stroja). Ocenite verjetnost, da bo med izdelavo ene puše odstopanje njenega premera od nazivnega manjše od 0,5 mm .
rešitev. Naj se r.v. X– premer izdelane puše. Glede na pogoj je njegovo matematično pričakovanje enako nazivnemu premeru (če ni sistematične okvare v nastavitvah stroja): a=M(X)=5 in disperzija D(X)≤0,01. Uporaba Čebiševljeve neenakosti pri ε = 0,5, dobimo:
Tako je verjetnost takšnega odstopanja precej velika, zato lahko sklepamo, da pri enkratni izdelavi dela skoraj gotovo odstopanje premera od nazivnega ne bo preseglo 0,5 mm .
V svojem pomenu standardna deviacija σ označuje povprečje odstopanje naključne spremenljivke od njenega središča (tj. od njenega matematičnega pričakovanja). Ker to povprečje odstopanja, potem so pri testiranju možna velika (poudarek na o) odstopanja. Kako velika odstopanja so praktično možna? Pri preučevanju normalno porazdeljenih naključnih spremenljivk smo izpeljali pravilo "treh sigm": normalno porazdeljena naključna spremenljivka X v enem samem testu od svojega povprečja praktično ne odstopa več kot 3σ, Kje σ= σ(X)– standardna deviacija r.v. X. To pravilo smo izpeljali iz dejstva, da smo dobili neenakost
 .
.
Ocenimo zdaj verjetnost za arbitrarna naključna spremenljivka X sprejeti vrednost, ki se od povprečja razlikuje za največ trikratni standardni odklon. Uporaba Čebiševljeve neenakosti pri ε = 3σ in glede na to D(Х)= σ 2 , dobimo:
 .
.
torej na splošno lahko ocenimo verjetnost, da naključna spremenljivka odstopa od svoje sredine za največ tri standardne deviacije s številom 0.89 , medtem ko je za normalno porazdelitev to mogoče zagotoviti z verjetnostjo 0.997 .
Čebiševljevo neenakost lahko posplošimo na sistem neodvisnih enako porazdeljenih naključnih spremenljivk.
Posplošena neenakost Čebiševa. Če so neodvisne naključne spremenljivke X 1 , X 2 , … , X n M(X jaz )= a in odstopanja D(X jaz )= D, To
pri n=1 ta neenakost se spremeni v zgoraj formulirano neenakost Čebiševa.
Čebiševljeva neenakost, ki ima neodvisen pomen za reševanje ustreznih problemov, se uporablja za dokazovanje tako imenovanega Čebiševljevega izreka. Najprej bomo govorili o bistvu tega izreka, nato pa podali njegovo formalno formulacijo.
Pustiti X 1
, X 2
, … , X n– veliko število neodvisnih naključnih spremenljivk z matematičnimi pričakovanji M(X 1
)=a 1
, … , M(X n )=a n. Čeprav lahko vsak od njih kot rezultat poskusa prevzame vrednost, ki je daleč od svojega povprečja (tj. matematičnega pričakovanja), pa naključna spremenljivka  , enako njihovi aritmetični sredini, bo najverjetneje prevzelo vrednost blizu fiksnega števila
, enako njihovi aritmetični sredini, bo najverjetneje prevzelo vrednost blizu fiksnega števila  (to je povprečje vseh matematičnih pričakovanj). To pomeni naslednje. Naj bodo kot rezultat testa neodvisne naključne spremenljivke X 1
, X 2
, … , X n(veliko jih je!) ustrezno prevzeli vrednosti X 1
, X 2
, … , X n oz. Potem, če se lahko izkaže, da so te vrednosti same daleč od povprečnih vrednosti ustreznih naključnih spremenljivk, njihova povprečna vrednost
(to je povprečje vseh matematičnih pričakovanj). To pomeni naslednje. Naj bodo kot rezultat testa neodvisne naključne spremenljivke X 1
, X 2
, … , X n(veliko jih je!) ustrezno prevzeli vrednosti X 1
, X 2
, … , X n oz. Potem, če se lahko izkaže, da so te vrednosti same daleč od povprečnih vrednosti ustreznih naključnih spremenljivk, njihova povprečna vrednost  bo najverjetneje blizu številke
bo najverjetneje blizu številke  . Tako aritmetična sredina velikega števila naključnih spremenljivk že izgubi svoj naključni značaj in jo je mogoče napovedati z veliko natančnostjo. To je mogoče pojasniti z dejstvom, da naključna odstopanja vrednosti X jaz od a jaz so lahko različnih znakov, zato so ta odstopanja najverjetneje kompenzirana.
. Tako aritmetična sredina velikega števila naključnih spremenljivk že izgubi svoj naključni značaj in jo je mogoče napovedati z veliko natančnostjo. To je mogoče pojasniti z dejstvom, da naključna odstopanja vrednosti X jaz od a jaz so lahko različnih znakov, zato so ta odstopanja najverjetneje kompenzirana.
Terema Chebyshev (zakon velikih števil v Chebyshev obliki). Pustiti X 1 , X 2 , … , X n … – zaporedje po parih neodvisnih naključnih spremenljivk, katerih variance so omejene na isto število. Potem, ne glede na to, kako majhno število ε vzamemo, je verjetnost neenakosti
bo čim bližje ena, če bo število n vzemite dovolj velike naključne spremenljivke. Formalno to pomeni, da pod pogoji izreka
To vrsto konvergence imenujemo konvergenca po verjetnosti in jo označujemo:
Tako Čebiševljev izrek pravi, da če obstaja dovolj veliko število neodvisnih naključnih spremenljivk, bo njihova aritmetična sredina v enem samem testu skoraj zanesljivo prevzela vrednost, ki je blizu sredini njihovih matematičnih pričakovanj.
Najpogosteje se Čebiševljev izrek uporablja v situacijah, kjer so naključne spremenljivke X 1 , X 2 , … , X n … imajo enako porazdelitev (tj. enak porazdelitveni zakon ali enako gostoto verjetnosti). Pravzaprav gre preprosto za veliko število primerkov iste naključne spremenljivke.
Posledica(posplošena neenakost Čebiševa). Če so neodvisne naključne spremenljivke X 1 , X 2 , … , X n … imajo enako porazdelitev z matematičnimi pričakovanji M(X jaz )= a in odstopanja D(X jaz )= D, To
 , tj.
, tj.  .
.
Dokaz sledi iz posplošene Čebiševljeve neenakosti s prehodom na limito pri n→∞ .
Naj še enkrat opozorimo, da zgoraj izpisane enakosti ne zagotavljajo vrednosti količine  si prizadeva za A pri n→∞. Ta količina še vedno ostaja naključna spremenljivka in njene posamezne vrednosti so lahko precej oddaljene A. Toda verjetnost takega (daleč od tega A) vrednosti z naraščanjem n teži k 0.
si prizadeva za A pri n→∞. Ta količina še vedno ostaja naključna spremenljivka in njene posamezne vrednosti so lahko precej oddaljene A. Toda verjetnost takega (daleč od tega A) vrednosti z naraščanjem n teži k 0.
Komentiraj. Sklep posledice očitno velja tudi v bolj splošnem primeru, ko so neodvisne naključne spremenljivke X 1 , X 2 , … , X n … imajo različne porazdelitve, vendar enaka matematična pričakovanja (enaka A) in skupaj omejena odstopanja. To nam omogoča, da predvidimo natančnost meritve določene količine, tudi če so bile te meritve opravljene z različnimi instrumenti.
Oglejmo si podrobneje uporabo te posledice pri merjenju količin. Uporabimo kakšno napravo n meritve iste količine, katere prava vrednost je enaka A in ne vemo. Rezultati tovrstnih meritev X 1
, X 2
, … , X n se lahko bistveno razlikujejo med seboj (in od prave vrednosti A) zaradi različnih naključnih dejavnikov (sprememb tlaka, temperature, naključnih vibracij itd.). Razmislite o r.v. X– odčitavanje instrumenta za posamezno meritev količine, kot tudi niz r.v. X 1
, X 2
, … , X n– odčitek instrumenta pri prvi, drugi, ..., zadnji meritvi. Tako vsaka od količin X 1
, X 2
, … , X n
obstaja samo eden izmed primerov s.v. X, zato imajo vsi enako porazdelitev kot r.v. X. Ker rezultati meritev niso odvisni drug od drugega, potem je r.v. X 1
, X 2
, … , X n lahko štejemo za neodvisno. Če naprava ne povzroči sistematične napake (na primer ničla na skali ni "izklopljena", vzmet ni raztegnjena itd.), potem lahko domnevamo, da je matematično pričakovanje M(X) = a, in zato M(X 1
) = ... = M(X n ) = a. Tako so pogoji zgornje posledice izpolnjeni in zato kot približna vrednost količine A lahko vzamemo "realizacijo" naključne spremenljivke  v našem poskusu (sestavljen iz izvajanja serije n meritve), tj.
v našem poskusu (sestavljen iz izvajanja serije n meritve), tj.
 .
.
Pri velikem številu meritev je dobra natančnost izračuna po tej formuli praktično gotova. To je utemeljitev praktičnega načela, da se pri velikem številu meritev njihova aritmetična sredina praktično ne razlikuje veliko od prave vrednosti izmerjene vrednosti.
Metoda "vzorčenja", ki se pogosto uporablja v matematični statistiki, temelji na zakonu velikih števil, ki omogoča pridobitev objektivnih značilnosti s sprejemljivo natančnostjo iz relativno majhnega vzorca vrednosti naključne spremenljivke. Toda o tem bomo razpravljali v naslednjem razdelku.
Primer. Določena količina se meri na merilni napravi, ki ne povzroča sistematičnih popačenj A enkrat (prejeta vrednost X 1
), nato pa še 99-krat (dobljene vrednosti X 2
, … , X 100
). Za pravo merilno vrednost A najprej se vzame rezultat prve meritve  , nato pa aritmetično sredino vseh meritev
, nato pa aritmetično sredino vseh meritev  . Merilna natančnost naprave je takšna, da standardna deviacija meritve σ ni večja od 1 (zato je varianca D=σ
2
tudi ne presega 1). Za vsako merilno metodo ocenite verjetnost, da merilna napaka ne bo večja od 2.
. Merilna natančnost naprave je takšna, da standardna deviacija meritve σ ni večja od 1 (zato je varianca D=σ
2
tudi ne presega 1). Za vsako merilno metodo ocenite verjetnost, da merilna napaka ne bo večja od 2.
rešitev. Naj se r.v. X– odčitek instrumenta za eno meritev. Potem po pogoju M(X)=a. Za odgovor na zastavljena vprašanja uporabimo posplošeno neenakost Čebiševa

pri ε =2
najprej za n=1
in potem za n=100
. V prvem primeru dobimo  , v drugem pa. Tako drugi primer praktično zagotavlja določeno merilno natančnost, medtem ko prvi v tem smislu pušča velike dvome.
, v drugem pa. Tako drugi primer praktično zagotavlja določeno merilno natančnost, medtem ko prvi v tem smislu pušča velike dvome.
Uporabimo zgornje izjave za naključne spremenljivke, ki nastanejo v Bernoullijevi shemi. Spomnimo se bistva te sheme. Naj se proizvaja n neodvisni poskusi, od katerih vsak vsebuje nek dogodek A se lahko pojavi z enako verjetnostjo R, A q=1–р(v smislu, to je verjetnost nasprotnega dogodka - dogodka, ki se ne zgodi A) . Porabimo nekaj številk n takšni testi. Poglejmo si naključne spremenljivke: X 1 – število ponovitev dogodka A V 1 -ta preizkušnja, ..., X n– število ponovitev dogodka A V n-ti test. Vsi vpisani s.v. lahko sprejme vrednosti 0 oz 1 (dogodek A se lahko pojavijo v testu ali ne), in vrednost 1 glede na pogoj je sprejet v vsakem poskusu z verjetnostjo str(verjetnost nastanka dogodka A v vsakem poskusu) in vrednost 0 z verjetnostjo q= 1 – str. Zato imajo te količine enake zakone porazdelitve:
|
X 1 | ||
|
X n | ||
Zato so tudi povprečne vrednosti teh količin in njihove variance enake: M(X 1 )=0 ∙ q+1 ∙ p= p, …, M(X n )= str ; D(X 1 )=(0 2 ∙ q+1 2 ∙ str)− str 2 = str∙(1− str)= str ∙ q, …, D(X n )= str ∙ q. Če nadomestimo te vrednosti v posplošeno neenakost Čebiševa, dobimo
 .
.
Jasno je, da je r.v. X=X 1 +…+X n je število ponovitev dogodka A v vsem n testi (kot pravijo - "število uspehov" v n testi). Pustite v vodeno n dogodek testiranja A pojavil v k izmed njih. Potem lahko prejšnjo neenakost zapišemo kot
 .
.
Toda velikost  , enako razmerju števila pojavitev dogodka A V n neodvisnih poskusov glede na skupno število poskusov, se je prej imenovala relativna pogostost dogodkov A V n testi. Zato obstaja neenakost
, enako razmerju števila pojavitev dogodka A V n neodvisnih poskusov glede na skupno število poskusov, se je prej imenovala relativna pogostost dogodkov A V n testi. Zato obstaja neenakost
 .
.
Obrnimo se zdaj do meje pri n→∞, dobimo  , tj.
, tj.  (po verjetnosti). To je vsebina zakona velikih števil v Bernoullijevi obliki. Iz tega izhaja, da z dovolj velikim številom testov n poljubno majhna odstopanja relativne frekvence
(po verjetnosti). To je vsebina zakona velikih števil v Bernoullijevi obliki. Iz tega izhaja, da z dovolj velikim številom testov n poljubno majhna odstopanja relativne frekvence  dogodkov iz njegove verjetnosti R- skoraj zanesljivi dogodki, velika odstopanja pa skoraj nemogoča. Iz tega izhaja sklep o takšni stabilnosti relativnih frekvenc (o kateri smo prej govorili kot eksperimentalno fact) utemeljuje prej vpeljano statistično definicijo verjetnosti dogodka kot števila, okoli katerega niha relativna frekvenca dogodka.
dogodkov iz njegove verjetnosti R- skoraj zanesljivi dogodki, velika odstopanja pa skoraj nemogoča. Iz tega izhaja sklep o takšni stabilnosti relativnih frekvenc (o kateri smo prej govorili kot eksperimentalno fact) utemeljuje prej vpeljano statistično definicijo verjetnosti dogodka kot števila, okoli katerega niha relativna frekvenca dogodka.
Glede na to, da izraz str∙
q=
str∙(1−
str)=
str−
str 2
ne presega intervala spremembe  (to je enostavno preveriti z iskanjem minimuma te funkcije na tem segmentu), iz zgornje neenakosti
(to je enostavno preveriti z iskanjem minimuma te funkcije na tem segmentu), iz zgornje neenakosti  enostavno dobiti to
enostavno dobiti to
 ,
,
ki se uporablja pri reševanju ustreznih problemov (eden izmed njih bo podan spodaj).
Primer. Kovanec je bil vržen 1000-krat. Ocenite verjetnost, da bo odstopanje relativne pogostosti pojavljanja grba od njegove verjetnosti manjše od 0,1.
rešitev. Uporaba neenakosti  pri str=
q=1/2
,
n=1000
,
ε=0,1, bomo prejeli.
pri str=
q=1/2
,
n=1000
,
ε=0,1, bomo prejeli.
Primer. Ocenite verjetnost, da bo pod pogoji iz prejšnjega primera število k izpadli emblemi bodo v razponu od 400 prej 600 .
rešitev. Pogoj 400<
k<600
pomeni, da 400/1000<
k/
n<600/1000
, tj. 0.4<
W n (A)<0.6
oz  . Kot smo pravkar videli iz prejšnjega primera, verjetnost takega dogodka ni nič manjša 0.975
.
. Kot smo pravkar videli iz prejšnjega primera, verjetnost takega dogodka ni nič manjša 0.975
.
Primer. Za izračun verjetnosti nekega dogodka A Izvedenih 1000 poskusov, v katerih dogodek A pojavil 300-krat. Ocenite verjetnost, da je relativna frekvenca (enaka 300/1000 = 0,3) oddaljena od prave verjetnosti R ne več kot 0,1.
rešitev. Uporaba zgornje neenakosti  za n=1000, ε=0,1, dobimo .
za n=1000, ε=0,1, dobimo .
Pojav stabilizacije frekvenc pojavljanja naključnih dogodkov, odkrit na velikem in raznolikem materialu, sprva ni imel nobene utemeljitve in je bil dojet kot povsem empirično dejstvo. Prvi teoretični rezultat na tem področju je bil slavni Bernoullijev izrek, objavljen leta 1713, ki je postavil temelje za zakone velikih števil.
Bernoullijev izrek je po svoji vsebini mejni izrek, tj. izjava asimptotičnega pomena, ki pove, kaj se bo zgodilo z verjetnostnimi parametri ob velikem številu opazovanj. Prednik vseh sodobnih številnih izjav te vrste je prav Bernoullijev izrek.
Danes se zdi, da je matematični zakon velikih števil odraz neke splošne lastnosti mnogih realnih procesov.
Z željo dati zakonu velikih števil največji možni obseg, ki ustreza daleč od izčrpanih potencialnih možnosti uporabe tega zakona, je eden največjih matematikov našega stoletja A. N. Kolmogorov formuliral njegovo bistvo na naslednji način: zakon velikih števil je "splošno načelo, na podlagi katerega skupno delovanje velikega števila naključnih dejavnikov vodi do rezultata, skoraj neodvisnega od naključja."
Tako ima zakon velikih števil dve razlagi. Ena je matematična, povezana s posebnimi matematičnimi modeli, formulacijami, teorijami, druga pa bolj splošna, ki presega ta okvir. Druga razlaga je povezana s pojavom oblikovanja bolj ali manj usmerjenega delovanja, ki ga pogosto opazimo v praksi, v ozadju velikega števila skritih ali vidnih dejavnikov delovanja, ki navzven nimajo takšne kontinuitete. Primera, povezana z drugo razlago, sta oblikovanje cen na prostem trgu in oblikovanje javnega mnenja o določenem vprašanju.
Ko smo opazili to splošno razlago zakona velikih števil, se obrnemo na posebne matematične formulacije tega zakona.
Kot smo rekli zgoraj, je prvi in bistveno najpomembnejši za teorijo verjetnosti Bernoullijev izrek. Vsebina tega matematičnega dejstva, ki odraža enega najpomembnejših zakonov sveta, ki nas obkroža, je naslednja.
Razmislite o zaporedju nepovezanih (tj. neodvisnih) testov, katerih pogoji se dosledno ponavljajo od testa do testa. Rezultat vsakega testa je pojav ali ne-pojavitev dogodka, ki nas zanima A.
Ta postopek (Bernoullijeva shema) se očitno lahko šteje za tipičnega za številna praktična področja: "fant - deklica" v zaporedju novorojenčkov, dnevna meteorološka opazovanja ("deževalo je - ni"), nadzor pretoka proizvedenih izdelkov ( "normalno - okvarjeno") itd.
Pogostost pojavljanja dogodkov A pri p testi ( t A -
pogostost dogodkov A V p testi) ima z rastjo p težnja po stabilizaciji njegove vrednosti je empirično dejstvo.
Bernoullijev izrek. Izberimo poljubno majhno pozitivno število e. Potem
Poudarjamo, da matematičnega dejstva, ki ga je ugotovil Bernoulli v določenem matematičnem modelu (v Bernoullijevi shemi), ne smemo zamenjevati z empirično ugotovljeno pravilnostjo stabilnosti frekvence. Bernoulli se ni zadovoljil zgolj z navedbo formule (9.1), temveč je ob upoštevanju potreb prakse podal oceno neenakosti, ki je v tej formuli prisotna. Spodaj se bomo obrnili na to razlago.
Bernoullijev zakon velikih števil je bil predmet raziskav velikega števila matematikov, ki so ga skušali izboljšati. Eno od teh izboljšav je dobil angleški matematik Moivre in se trenutno imenuje Moivre-Laplaceov izrek. V Bernoullijevi shemi upoštevajte zaporedje normaliziranih količin:
Integralni izrek Moivre - Laplace. Izberimo poljubni dve števili X ( in x 2. V tem primeru x, x 7, nato pri p -» °°
Če je na desni strani formule (9.3) spremenljivka x x težijo k neskončnosti, potem bo nastala meja, odvisna samo od x 2 (indeks 2 se lahko v tem primeru odstrani), porazdelitvena funkcija, imenujemo jo standardna normalna porazdelitev, oz Gaussov zakon.
Desna stran formule (9.3) je enaka y = F(x 2) - F(x x). F(x 2)-> 1 at x 2-> °° in F(x,) -> 0 pri x, -> Zaradi izbire dovolj velikega
X] > 0 in je X]n dovolj velik v absolutni vrednosti, dobimo naslednjo neenakost:
Ob upoštevanju formule (9.2) lahko izluščimo praktično zanesljive ocene:
Če se komu zdi stopnja zaupanja y = 0,95 (tj. verjetnost napake 0,05) nezadostna, lahko "igrate na varno" in zgradite nekoliko širši interval zaupanja z uporabo zgoraj omenjenega pravila treh sigma:
Ta interval ustreza zelo visoki stopnji zaupanja y = 0,997 (glejte tabele normalne porazdelitve).
Razmislite o primeru metanja kovanca. Vrzimo kovanec n = 100-krat. Bi se lahko zgodilo, da frekvenca R se bo zelo razlikovala od verjetnosti R= 0,5 (ob predpostavki, da je kovanec simetričen), ali bo na primer enak nič? Za to je potrebno, da grb niti enkrat ne izpade. Tak dogodek je teoretično možen, vendar smo podobne verjetnosti že izračunali, za ta dogodek bo enaka  Ta vrednost
Ta vrednost
zelo majhen, njegov vrstni red je število s 30 ničlami za decimalno vejico. Dogodek s tako verjetnostjo lahko varno štejemo za praktično nemogočega. Kakšna odstopanja frekvence od verjetnosti so praktično možna pri velikem številu poskusov? Z uporabo Moivre-Laplaceovega izreka na to vprašanje odgovorimo takole: z verjetnostjo pri= 0,95 frekvenca grba R se ujema z intervalom zaupanja:
Če se napaka 0,05 ne zdi majhna, morate povečati število poskusov (metanje kovancev). Pri povečanju pširina intervala zaupanja se zmanjšuje (žal ne tako hitro, kot bi želeli, ampak obratno sorazmerno z -Jn). Na primer, kdaj p= 10.000 dobimo to R leži v intervalu zaupanja z verjetnostjo zaupanja pri= 0,95 : 0,5 ±0,01.
Tako smo kvantitativno razumeli vprašanje približevanja frekvence verjetnosti.
Zdaj pa poiščimo verjetnost dogodka glede na njegovo pogostost in ocenimo napako tega približka.
Izvedimo veliko število poskusov p(vrzite kovanec), poiščite pogostost dogodka A in želimo oceniti njegovo verjetnost R.
Iz zakona velikih števil p sledi, da:
Zdaj pa ocenimo praktično možno napako približne enakosti (9.7). Za to uporabimo neenakost (9.5) v obliki:
Najti R Avtor: R rešiti moramo neenačbo (9.8), za to jo moramo kvadrirati in rešiti ustrezno kvadratno enačbo. Kot rezultat dobimo:
Kje 
Za grobo oceno R Avtor: R lahko v formuli (9.8) R na desni zamenjajte z R ali v formulah (9.10), (9.11) predpostavimo, da

Potem dobimo:
Spustiti noter p= 400 poskusov je bila pridobljena vrednost frekvence R= 0,25, potem s stopnjo zaupanja y = 0,95 ugotovimo:
Kaj pa, če moramo verjetnost vedeti natančneje, z napako, recimo, največ 0,01? Da bi to naredili, je treba povečati število poskusov.
Če v formuli (9.12) predpostavimo verjetnost R= 0,25, vrednost napake izenačimo z dano vrednostjo 0,01 in dobimo enačbo za P:

Če rešimo to enačbo, dobimo n~ 7500.
Razmislimo zdaj o drugem vprašanju: ali je odstopanje frekvence od verjetnosti, pridobljeno v poskusih, mogoče razložiti z naključnimi vzroki, ali to odstopanje kaže, da verjetnost ni takšna, kot smo jo pričakovali? Z drugimi besedami, ali izkušnje potrjujejo sprejeto statistično hipotezo ali, nasprotno, zahtevajo, da jo zavrnete?
Naj na primer vrže kovanec p= 800-krat, dobimo pogostost pojavljanja grba R= 0,52. Sumili smo, da je kovanec asimetričen. Je ta sum upravičen? Za odgovor na to vprašanje bomo izhajali iz predpostavke, da je kovanec simetričen (p = 0,5). Poiščimo interval zaupanja (z verjetnostjo zaupanja pri= 0,95) za pogostost pojavljanja grba. Če vrednost, dobljena v poskusu R= 0,52 se prilega temu intervalu - vse je normalno, sprejeta hipoteza o simetriji kovanca ni v nasprotju z eksperimentalnimi podatki. Formula (9.12) pri R= 0,5 daje interval 0,5 ± 0,035; prejeto vrednost p = 0,52 se prilega temu intervalu, kar pomeni, da bo treba kovanec "očistiti" sumov asimetrije.
Podobne metode se uporabljajo za presojo, ali so različna odstopanja od matematičnega pričakovanja, opažena pri naključnih pojavih, naključna ali "pomembna". Je bila na primer premajhna teža ugotovljena naključno pri nekaj vzorcih embaliranega blaga ali pa kaže na sistematično zavajanje kupcev? Ali se je stopnja ozdravitve pri bolnikih, ki so jemali novo zdravilo, povečala po naključju ali je to posledica učinka zdravila?
Normalni zakon ima posebno pomembno vlogo v teoriji verjetnosti in njeni praktični uporabi. Zgoraj smo že videli, da je naključna spremenljivka - število pojavitev nekega dogodka v Bernoullijevi shemi - z p-» °° se reducira na normalni zakon. Vendar pa obstaja veliko bolj splošen rezultat.
Centralni mejni izrek. Vsota velikega števila neodvisnih (ali šibko odvisnih) naključnih spremenljivk, ki so med seboj primerljive po vrstnem redu svojih varianc, se porazdeli po normalnem zakonu, ne glede na to, kakšni so bili zakoni porazdelitve členov. Zgornja izjava je groba kvalitativna formulacija teorije osrednje meje. Ta izrek ima veliko oblik, ki se med seboj razlikujejo po pogojih, ki jih morajo izpolnjevati naključne spremenljivke, da se njihova vsota »normalizira« s povečanjem števila členov.
Normalna porazdelitvena gostota Dx) je izražena s formulo:
Kje A - matematično pričakovanje naključne spremenljivke X s= V7) je njegov standardni odklon.
Za izračun verjetnosti, da x pade v interval (x 1? x 2), se uporabi integral:
Ker integral (9.14) pri gostoti (9.13) ni izražen z elementarnimi funkcijami ("se ne vzame"), potem za izračun (9.14) uporabljajo tabele funkcije integralne porazdelitve standardne normalne porazdelitve, ko a = 0, a = 1 (takšne tabele so na voljo v katerem koli učbeniku teorije verjetnosti):
Verjetnost (9.14) z uporabo enačbe (10.15) je izražena s formulo:
Primer. Poiščite verjetnost, da naključna spremenljivka X, ki ima normalno porazdelitev s parametri A, a, bo odstopal od svojega matematičnega pričakovanja modulo za največ 3.
Z uporabo formule (9.16) in tabele porazdelitvene funkcije normalnega zakona dobimo:
Primer. V vsakem od 700 neodvisnih poskusov dogodek A zgodi s stalno verjetnostjo R= 0,35. Poiščite verjetnost, da dogodek A se bo zgodilo:
- 1) natanko 270-krat;
- 2) manj kot 270-krat in več kot 230-krat;
- 3) več kot 270-krat.
Iskanje matematičnega pričakovanja A = itd in standardni odklon:
![]()
naključna spremenljivka - število pojavitev dogodka A:

Iskanje centrirane in normalizirane vrednosti X:

Iz tabel normalne porazdelitve gostote najdemo f(x):
![]()

Poiščimo ga zdaj R w (x,> 270) = P 700 (270 F(1,98) = = 1 - 0,97615 = 0,02385.
Resen korak v raziskovanju problemov velikih števil je leta 1867 naredil P. L. Čebišev. Upošteval je zelo splošen primer, ko se od neodvisnih naključnih spremenljivk ne zahteva nič razen obstoja matematičnih pričakovanj in varianc.
Čebiševljeva neenakost. Za poljubno majhno pozitivno število e velja neenakost:
Čebiševljev izrek.če x x, x 2, ..., x p - po paru neodvisne naključne spremenljivke, od katerih ima vsaka matematično pričakovanje E(Xj) = ci in varianco D(x,) =), variance pa so enakomerno omejene, tj. 1,2 ..., potem za poljubno majhno pozitivno število e velja naslednja relacija:
Posledica. če a,= aio, -o 2 , i= 1,2 ..., torej
Naloga. Kolikokrat je treba vreči kovanec, da verjetnost ni manjša od y- 0,997, bi lahko trdili, da bo pogostost izpadanja grba v intervalu (0,499; 0,501)?
Predpostavimo, da je kovanec simetričen, p - q - 0,5. Uporabimo Čebiševljev izrek v formuli (9.19) za naključno spremenljivko X- pogostost pojavljanja grba v p meti kovancev. To smo že pokazali zgoraj X = X x + X 2 + ... +X„, Kje X t - naključna spremenljivka, ki ima vrednost 1, če je kovanec glava, in vrednost 0, če je rep. Torej:
Zapišimo neenakost (9.19) za dogodek, ki je nasproten dogodku, označenemu pod znakom verjetnosti:

V našem primeru je [e = 0,001, cj 2 = /?-p)]t število pojavitev grba v p metanje. Če te količine nadomestimo v zadnjo neenakost in ob upoštevanju, da mora biti glede na pogoje problema neenakost izpolnjena, dobimo:

Navedeni primer ponazarja možnost uporabe Čebiševljeve neenakosti za oceno verjetnosti določenih odstopanj naključnih spremenljivk (kot tudi težave, kot je ta primer, povezane z izračunom teh verjetnosti). Prednost Čebiševljeve neenakosti je, da ne zahteva poznavanja zakonov porazdelitve naključnih spremenljivk. Seveda, če je tak zakon znan, potem Čebiševljeva neenakost daje preveč grobe ocene.
Poglejmo isti primer, vendar z uporabo dejstva, da je met kovanca poseben primer Bernoullijeve sheme. Število uspehov (v primeru - število grbov) upošteva binomski zakon in z velikim p ta zakon je mogoče predstaviti z normalnim zakonom z matematičnim pričakovanjem zaradi integralnega izreka Moivre - Laplace a = pr = n? 0,5 in s standardno deviacijo a = yfnpq - 25=0,5l/l. Naključna spremenljivka - pogostost izpadanja grba - ima matematično pričakovanje = 0,5 in standardno deviacijo

Potem imamo:

Iz zadnje neenakosti dobimo:

Iz običajnih porazdelitvenih tabel najdemo:

Vidimo, da normalni približek daje število metov kovancev, ki zagotavlja dano napako pri oceni verjetnosti grba, ki je 37-krat manjša v primerjavi z oceno, dobljeno s pomočjo neenakosti Čebiševa (vendar neenakost Čebiševa omogoča, da podobne izračune v primeru, ko nimamo informacij o zakonu porazdelitve preučevane naključne spremenljivke).
Oglejmo si zdaj uporabni problem, rešen s formulo (9.16).
Problem konkurence. Dve konkurenčni železniški družbi imata vsak po en vlak med Moskvo in Sankt Peterburgom. Ti vlaki so približno enako opremljeni ter odhajajo in prihajajo ob približno istem času. Pretvarjajmo se, da p= 1000 potnikov samostojno in naključno izbere svoj vlak, zato kot matematični model za izbiro vlaka s strani potnikov uporabimo Bernoullijevo shemo z p izzivi in verjetnost uspeha R= 0,5. Podjetje se mora odločiti, koliko sedežev bo zagotovilo na vlaku, ob upoštevanju dveh medsebojno nasprotujočih si pogojev: po eni strani ne želite imeti praznih sedežev, po drugi strani pa ne želite, da so ljudje nezadovoljni z pomanjkanje sedežev (naslednjič bodo raje imeli konkurenčna podjetja). Seveda se lahko zagotovi na vlaku p= 1000 mest, potem pa bodo očitno ostala prazna mesta. Naključna spremenljivka - število potnikov na vlaku - v okviru sprejetega matematičnega modela z uporabo integralne teorije Moivre - Laplace upošteva normalni zakon z matematičnim pričakovanjem a = pr = str/2 in varianco a 2 = npq = str/4 zaporedno. Verjetnost, da več kot s potnikov, se določi z razmerjem:

Nastavite stopnjo tveganja A, tj. verjetnost, da bo prišlo več s potniki: 
Od tod: 
če A je koren tveganja zadnje enačbe, ki ga najdemo iz tabel porazdelitvene funkcije normalnega zakona, potem dobimo: 
Če npr. p = 1000, A= 0,01 (ta stopnja tveganja pomeni, da število mest s zadostuje v 99 primerih od 100), potem x a ~ 2,33 in s = 537 mest. Še več, če obe podjetji sprejmeta enake stopnje tveganja A= 0,01, potem bosta vlaka imela skupaj 1074 sedežev, od tega bo 74 praznih. Podobno je mogoče izračunati, da bi 514 sedežev zadostovalo v 80 % vseh primerov, 549 sedežev pa bi zadostovalo v 999 od 1000 primerov.
Podobni premisleki veljajo za težave pri drugih konkurenčnih storitvah. Na primer, če T kinematografi tekmujejo za isto p gledalcev, potem je treba sprejeti R= -. Dobimo,
koliko je sedežev s v kinu je treba določiti z razmerjem:

Skupno število praznih mest je enako:

Za A = 0,01, p= 1000 in T= 2, 3, 4 so vrednosti tega števila približno enake 74, 126, 147.
Poglejmo še en primer. Naj bo vlak sestavljen iz P - 100 vagonov. Teža vsakega avtomobila je naključna spremenljivka z matematičnim pričakovanjem A - 65 ton in srednje kvadratno pričakovanje o = 9 ton Lokomotiva lahko vozi vlak, če njena teža ne presega 6600 ton; v nasprotnem primeru morate priklopiti drugo lokomotivo. Najti morate verjetnost, da vam tega ne bo treba narediti.
teže posameznih avtomobilov:  , ki ima enako matematično pričakovanje A - 65 in enako varianco d- o 2 = 81. Po pravilu matematičnih pričakovanj: E(x) - 100 * 65 = 6500. Po pravilu dodajanja varianc: D(x) = 100 x 81 = 8100. Z izluščitvijo korena dobimo standardni odklon. Da bi ena lokomotiva vlekla vlak, mora biti teža vlaka X se je izkazalo za omejujoče, tj. spada v interval (0; 6600). Naključno spremenljivko x - vsoto 100 členov - lahko štejemo za normalno porazdeljeno. Z uporabo formule (9.16) dobimo:
, ki ima enako matematično pričakovanje A - 65 in enako varianco d- o 2 = 81. Po pravilu matematičnih pričakovanj: E(x) - 100 * 65 = 6500. Po pravilu dodajanja varianc: D(x) = 100 x 81 = 8100. Z izluščitvijo korena dobimo standardni odklon. Da bi ena lokomotiva vlekla vlak, mora biti teža vlaka X se je izkazalo za omejujoče, tj. spada v interval (0; 6600). Naključno spremenljivko x - vsoto 100 členov - lahko štejemo za normalno porazdeljeno. Z uporabo formule (9.16) dobimo:

Iz tega sledi, da se bo lokomotiva »kosila« z vlakom s približno verjetnostjo 0,864. Zmanjšajmo zdaj število vagonov v vlaku za dva, tj p= 98. Če zdaj izračunamo verjetnost, da se bo lokomotiva "kosila" z vlakom, dobimo vrednost reda 0,99, to je skoraj gotov dogodek, čeprav je bilo za to treba odstraniti le dva vagona.
Torej, če imamo opravka z vsotami velikega števila naključnih spremenljivk, potem lahko uporabimo normalni zakon. Seveda se ob tem pojavi vprašanje: koliko naključnih spremenljivk je treba dodati, da je porazdelitveni zakon vsote že »normaliziran«? Odvisno od tega, kakšni so zakoni porazdelitve pojmov. Obstajajo tako zapleteni zakoni, da pride do normalizacije le pri zelo velikem številu izrazov. Toda te zakone so izumili matematiki, narava takšnih težav praviloma ne ustvarja namerno. Običajno je v praksi dovolj pet ali šest mandatov, da lahko uporabimo normalno pravo.
Hitrost, s katero se “normalizira” porazdelitveni zakon vsote enako porazdeljenih naključnih spremenljivk, lahko ponazorimo na primeru naključnih spremenljivk z enakomerno porazdelitvijo na intervalu (0, 1). Krivulja takšne porazdelitve ima obliko pravokotnika, ki ni več podobna normalnemu zakonu. Dodamo še dve taki neodvisni spremenljivki – dobimo naključno spremenljivko porazdeljeno po tako imenovanem Simpsonovem zakonu, katere grafični prikaz ima obliko enakokrakega trikotnika. Prav tako ni videti kot običajen zakon, vendar je boljši. In če seštejete tri tako enakomerno porazdeljene naključne spremenljivke, dobite krivuljo, sestavljeno iz treh segmentov parabol, ki je zelo podobna normalni krivulji. Če seštejete šest takih naključnih spremenljivk, dobite krivuljo, ki se ne razlikuje od običajne. To je osnova za široko uporabljeno metodo za pridobivanje normalno porazdeljene naključne spremenljivke, vsi sodobni računalniki pa so opremljeni s senzorji za enakomerno porazdeljena (0, 1) naključna števila.
Naslednjo metodo priporočamo kot enega praktičnih načinov za preverjanje tega. Konstruiramo interval zaupanja za pogostost dogodka s stopnjo pri= 0,997 po pravilu treh sigm:

in če oba njegova konca ne segata čez segment (0, 1), potem lahko uporabimo normalni zakon. Če je katera od meja intervala zaupanja izven segmenta (0, 1), potem normalnega zakona ni mogoče uporabiti. Vendar pa pod nekaterimi pogoji binomski zakon za frekvenco nekega naključnega dogodka, če se ne nagiba k normalnemu, se lahko nagiba k drugemu zakonu.
V številnih aplikacijah se Bernoullijeva shema uporablja kot matematični model naključnega eksperimenta, v katerem število poskusov p velik, je naključni dogodek precej redek, tj. R = itd ni majhna, velika pa tudi ne (niha v območju O -5-20). V tem primeru velja limitna relacija:
Formulo (9.20) imenujemo Poissonov približek za binomski zakon, ker se porazdelitev verjetnosti na njeni desni strani imenuje Poissonov zakon. Za Poissonovo porazdelitev pravimo, da je porazdelitev verjetnosti za redke dogodke, ker se pojavi, ko so izpolnjene meje: p -»°°, R-»0, ampak X = pr oo.
Primer. Rojstni dnevi. Kakšna je verjetnost R t (k) da v družbi 500 ljudi Za so bili ljudje rojeni na novoletni dan? Če je teh 500 ljudi izbranih naključno, potem lahko Bernoullijevo shemo uporabimo z verjetnostjo uspeha P = 1/365. Potem

Izračuni verjetnosti za različne Za podajte naslednje vrednosti: RU = 0,3484...; R 2 = 0,2388...; R 3 = 0,1089...; P 4 = 0,0372...; R 5 = 0,0101...; R 6= 0,0023... Ustrezni približki z uporabo Poissonove formule za X = 500 1/365 = 1,37
podajte naslednje vrednosti: Ru = 0,3481...; R 2 = 0,2385...; P ъ = 0,1089; R 4 = 0,0373...; P 5 = 0,0102...; P 6 = 0,0023... Vse napake so le na četrtem decimalnem mestu.
Tu so primeri situacij, v katerih lahko uporabite Poissonov zakon redkih dogodkov.
Na telefonski centrali z majhno verjetnostjo pride do nepravilne povezave R, ponavadi R~0,005. Potem nam Poissonova formula omogoča, da najdemo verjetnost nepravilnih povezav za dano skupno število povezav n~ 1000 ko X = pr =1000 0,005 = 5.
Pri peki žemljic v testo dodamo rozine. Zaradi mešanja je treba pričakovati, da bo pogostost žemljic z rozinami približno sledila Poissonovi porazdelitvi R p (k, X), Kje X- gostota rozin v testu.
Radioaktivna snov oddaja π delce. Dogodek, da se število d-delcev sčasoma poveča t določeno območje prostora, ima fiksno vrednost za, upošteva Poissonov zakon.
Število živih celic s spremenjenimi kromosomi, izpostavljenih rentgenskim žarkom, sledi Poissonovi porazdelitvi.
Torej zakoni velikih števil omogočajo rešitev problema matematične statistike, povezane z ocenjevanjem neznanih verjetnosti elementarnih izidov naključnega eksperimenta. Zahvaljujoč temu znanju naredimo metode teorije verjetnosti praktično smiselne in uporabne. Zakoni velikih števil omogočajo tudi reševanje problema pridobivanja informacij o neznanih elementarnih verjetnostih v drugi obliki - obliki preverjanja statističnih hipotez.
Oglejmo si podrobneje formulacijo in verjetnostni mehanizem za reševanje problemov testiranja statističnih hipotez.
Zakon velikih števil v teoriji verjetnosti trdi, da je empirična sredina (aritmetična sredina) dovolj velikega končnega vzorca iz fiksne porazdelitve blizu teoretične sredine (matematičnega pričakovanja) te porazdelitve. Glede na vrsto konvergence ločimo šibki zakon velikih števil, ko pride do konvergence po verjetnosti, in močan zakon velikih števil, ko pride do konvergence skoraj povsod.
Vedno obstaja končno število poskusov, v katerih je s katero koli vnaprejšnjo verjetnostjo manj 1 relativna pogostost pojavljanja nekega dogodka se bo čim manj razlikovala od njegove verjetnosti.
Splošni pomen zakona velikih števil: skupno delovanje velikega števila enakih in neodvisnih naključnih dejavnikov vodi do rezultata, ki v meji ni odvisen od naključja.
Na tej lastnosti temeljijo metode za ocenjevanje verjetnosti na podlagi analize končnih vzorcev. Nazoren primer je napoved volilnih rezultatov na podlagi ankete na vzorcu volivcev.
Enciklopedični YouTube
1 / 5
✪ Zakon velikih števil
✪ 07 - Teorija verjetnosti. Zakon velikih števil
✪ 42 Zakon velikih števil
✪ 1 - Čebiševljev zakon velikih števil
✪ 11. razred, lekcija 25, Gaussova krivulja. Zakon velikih števil
Podnapisi
Poglejmo si zakon velikih števil, ki je morda najbolj intuitiven zakon v matematiki in teoriji verjetnosti. In ker velja za toliko stvari, se včasih uporablja in napačno razume. Naj ga najprej opredelim zaradi natančnosti, potem pa bomo govorili o intuiciji. Vzemimo naključno spremenljivko, na primer X. Recimo, da poznamo njeno matematično pričakovanje ali povprečje populacije. Zakon velikih števil preprosto pravi, da če vzamemo primer n-tega števila opazovanj naključne spremenljivke in povprečje vseh teh opazovanj... Vzemimo spremenljivko. Imenujmo ga X s indeksom n in črto na vrhu. To je aritmetična sredina n-tega števila opazovanj naše naključne spremenljivke. Tukaj je moja prva ugotovitev. Enkrat izvedem poskus in opazujem, nato ga naredim še enkrat in opazujem, nato znova naredim in dobim to. Ta poskus izvedem n-to število krat in nato delim s številom svojih opazovanj. Tukaj je moje vzorčno povprečje. Tukaj je povprečje vseh mojih opažanj. Zakon velikih števil nam pove, da se bo moja vzorčna sredina približala pričakovani vrednosti naključne spremenljivke. Lahko pa tudi zapišem, da se bo moje vzorčno povprečje približalo populacijskemu povprečju za n-to količino, ki teži k neskončnosti. Ne bom jasno razlikoval med "približevanjem" in "konvergenco", vendar upam, da intuitivno razumete, da bom, če tukaj vzamem dokaj velik vzorec, dobil pričakovano vrednost za celotno populacijo. Mislim, da vas večina intuitivno razume, da če opravim dovolj testov z velikim vzorcem primerov, mi bodo sčasoma testi dali vrednosti, ki jih pričakujem, ob upoštevanju pričakovane vrednosti in verjetnosti ter vsega tega neumnega. Ampak mislim, da je pogosto nejasno, zakaj se to zgodi. In preden začnem pojasnjevati, zakaj je tako, naj navedem konkreten primer. Zakon velikih števil nam pove, da... Recimo, da imamo naključno spremenljivko X. Je enako številu glav pri 100 metih poštenega kovanca. Najprej poznamo matematično pričakovanje te naključne spremenljivke. To je število metov kovancev ali poskusov, pomnoženo z verjetnostjo uspeha katerega koli poskusa. Torej je to enako 50. To pomeni, da zakon velikih števil pravi, da če vzamemo vzorec ali če povprečim te poskuse, bom dobil. .. Ko prvič delam test, bom 100-krat vrgel kovanec ali vzel škatlo s sto kovanci, jo stresel in nato preštel, koliko glav dobim, in dobil bi recimo številko 55. To bi bil X1. Nato ponovno pretresem škatlo in dobim številko 65. Potem spet in dobim 45. In to naredim n-krat, nato pa to delim s številom poskusov. Zakon velikih števil nam pove, da se bo to povprečje (povprečje vseh mojih opazovanj) približalo 50, ko se n približuje neskončnosti. Zdaj bi rad malo spregovoril o tem, zakaj se to zgodi. Marsikdo meni, da če je po 100 poskusih moj rezultat nadpovprečen, potem bi moral po zakonih verjetnosti dobiti več ali manj glav, da tako rekoč nadomestim razliko. To ni ravno to, kar se bo zgodilo. To se pogosto imenuje "hazarderjeva zmota". Naj vam pokažem razliko. Uporabil bom naslednji primer. Naj narišem graf. Spremenimo barvo. To je n, moja os x je n. To je število testov, ki jih bom opravil. In moja os Y bo vzorčna sredina. Vemo, da je matematično pričakovanje te poljubne spremenljivke 50. Naj ga narišem. To je 50. Vrnimo se k našemu primeru. Če je n ... Med prvim testom sem dobil 55, to je moje povprečje. Imam samo eno točko za vnos podatkov. Nato po dveh testih dobim 65. Torej bi bilo moje povprečje 65+55 deljeno z 2. To je 60. In moje povprečje se je malo povečalo. Potem sem dobil 45, kar je spet znižalo moje aritmetično povprečje. Ne bom narisal 45. Zdaj moram vse to povprečiti. Čemu je enako 45+65? Naj izračunam to vrednost, ki predstavlja točko. To je 165 deljeno s 3. To je 53. Ne, 55. Torej se povprečje vrne na 55. S temi testi lahko nadaljujemo. Potem ko smo opravili tri poskuse in dobili to povprečje, mnogi ljudje mislijo, da bodo bogovi verjetnosti poskrbeli, da bomo v prihodnosti dobili manj glav, da bo naslednjih nekaj poskusov imelo nižje rezultate, da se zniža povprečje. Vendar ni vedno tako. V prihodnosti ostaja verjetnost vedno enaka. Vedno bo 50-odstotna možnost, da bom dobil glave. Ne gre za to, da na začetku dobim določeno število glav, več kot pričakujem, potem pa moram nenadoma dobiti repke. To je hazarderjeva zmota. Samo zato, ker dobite nesorazmerno veliko število glav, ne pomeni, da boste na neki točki začeli dobivati nesorazmerno veliko število repov. To ne drži povsem. Zakon velikih števil nam pove, da ni pomembno. Recimo, da je po določenem končnem številu testov vaše povprečje... Verjetnost za to je precej majhna, a kljub temu... Recimo, da je vaše povprečje doseglo to mejo - 70. Mislite si: "Vau, oddaljili smo se od pričakovane vrednosti." Toda zakon velikih števil pravi, da ni vseeno, koliko testov opravimo. Pred nami je še neskončno število izzivov. Matematično pričakovanje tega neskončnega števila poskusov, zlasti v takšni situaciji, bi bilo naslednje. Ko pridete do končnega števila, ki izraža neko veliko vrednost, bo neskončno število, ki konvergira z njim, spet vodilo do pričakovane vrednosti. To je seveda zelo ohlapna razlaga, a to nam pove zakon velikih števil. Je pomembno. Ne pove nam, da če dobimo veliko glav, se bo verjetnost, da bomo dobili repe, nekako povečala, da bi nadomestila. Ta zakon nam pove, da ni pomembno, kakšen je izid pri končnem številu poskusov, dokler imate na voljo še neskončno število poskusov. In če jih naredite dovolj, se boste spet vrnili na pričakovano vrednost. To je pomembna točka. Premisli. Ampak to se ne uporablja vsak dan v praksi pri loterijah in igralnicah, čeprav je znano, da če narediš dovolj testov ... Lahko celo izračunamo ... kakšna je verjetnost, da resno odstopimo od norme? Toda igralnice in loterije delujejo vsak dan po načelu, da če vzameš dovolj ljudi, naravno, v kratkem času, z majhnim vzorcem, bo nekaj ljudi zadelo jackpot. Toda v daljšem časovnem obdobju bo igralnica vedno zmagala zaradi parametrov iger, v katere vas povabijo. To je pomembno načelo verjetnosti, ki je intuitivno. Čeprav je včasih, ko vam je formalno razloženo z naključnimi spremenljivkami, vse skupaj videti nekoliko zmedeno. Vse, kar ta zakon pravi, je, da več kot je vzorcev, bolj se bo aritmetična sredina teh vzorcev nagibala k pravi sredini. In če smo natančnejši, se bo aritmetična sredina vašega vzorca zbližala z matematičnim pričakovanjem naključne spremenljivke. To je vse. Se vidimo v naslednjem videu!
Šibek zakon velikih števil
Šibek zakon velikih števil se imenuje tudi Bernoullijev izrek po Jacobu Bernoulliju, ki ga je dokazal leta 1713.
Naj obstaja neskončno zaporedje (zaporedno štetje) enako porazdeljenih in nekoreliranih naključnih spremenljivk. To je njihova kovarianca c o v (X i , X j) = 0 , ∀ i ≠ j (\displaystyle \mathrm (cov) (X_(i),X_(j))=0,\;\forall i\not =j). Pustiti . Označimo z vzorčnim povprečjem prvega n (\displaystyle n)člani:
.
Potem X ¯ n → P μ (\displaystyle (\bar (X))_(n)\to ^(\!\!\!\!\!\!\mathbb (P) )\mu ).
Se pravi za vsako pozitivno ε (\displaystyle \varepsilon)
lim n → ∞ Pr (| X ¯ n − μ |< ε) = 1. {\displaystyle \lim _{n\to \infty }\Pr \!\left(\,|{\bar {X}}_{n}-\mu |<\varepsilon \,\right)=1.}Okrepljen zakon velikih števil
Naj obstaja neskončno zaporedje neodvisnih enako porazdeljenih naključnih spremenljivk ( X i ) i = 1 ∞ (\displaystyle \(X_(i)\)_(i=1)^(\infty )), definiran na enem verjetnostnem prostoru (Ω , F , P) (\displaystyle (\Omega ,(\mathcal (F)),\mathbb (P))). Pustiti E X i = μ , ∀ i ∈ N (\displaystyle \mathbb (E) X_(i)=\mu ,\;\forall i\in \mathbb (N) ). Označimo z X ¯ n (\displaystyle (\bar (X))_(n)) vzorčno povprečje prvega n (\displaystyle n)člani:
X ¯ n = 1 n ∑ i = 1 n X i , n ∈ N (\displaystyle (\bar (X))_(n)=(\frac (1)(n))\sum \limits _(i= 1)^(n)X_(i),\;n\in \mathbb (N) ).Potem X ¯ n → μ (\displaystyle (\bar (X))_(n)\to \mu ) skoraj vedno.
Pr (lim n → ∞ X ¯ n = μ) = 1. (\displaystyle \Pr \!\left(\lim _(n\to \infty )(\bar (X))_(n)=\mu \ desno)=1.) .Tako kot vsak matematični zakon je tudi zakon velikih števil mogoče uporabiti v resničnem svetu samo pod določenimi predpostavkami, ki jih je mogoče izpolniti le z določeno stopnjo natančnosti. Na primer, zaporednih testnih pogojev pogosto ni mogoče vzdrževati v nedogled in z absolutno natančnostjo. Poleg tega zakon velikih števil govori le o neverjetnost pomembno odstopanje povprečne vrednosti od matematičnega pričakovanja.