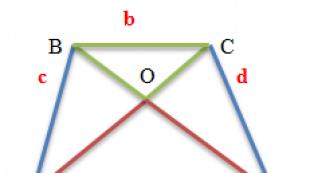
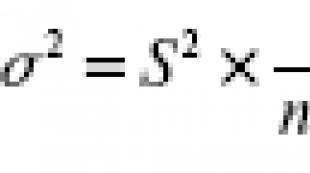Սեմինարի թեման. Նմուշառում սոցիոլոգիական հետազոտություններում Հիմնական հասկացություններ: Ներկայացուցչական նմուշ Նմուշ և ընդհանուր բնակչություն
Վիճակագրական հետազոտությունները շատ աշխատատար և թանկ են, ուստի միտք ծագեց շարունակական դիտարկումը ընտրովիով փոխարինելու մասին:
Անընդհատ դիտարկման հիմնական նպատակն է ուսումնասիրված վիճակագրական բնակչության բնութագրերի ձեռքբերումը դրա հետազոտված մասի համար:
Ընտրովի դիտարկում- Սա վիճակագրական հետազոտության մեթոդ է, որի դեպքում բնակչության ընդհանրացված ցուցանիշները սահմանվում են միայն առանձին մասի համար `պատահական ընտրության դրույթների հիման վրա:
Նմուշառման մեթոդով ուսումնասիրվում է ուսումնասիրված բնակչության միայն որոշակի մասը, մինչդեռ ուսումնասիրվող վիճակագրական բնակչությունը կոչվում է ընդհանուր բնակչություն:
Նմուշի բնակչությունը կամ պարզապես նմուշը կարելի է անվանել ընդհանուր բնակչությունից ընտրված միավորների մի մաս, որը ենթակա կլինի վիճակագրական հետազոտության:
Նմուշառման մեթոդի արժեքը. Ուսումնասիրվող ստորաբաժանումների նվազագույն թվաքանակով վիճակագրական ուսումնասիրություն կիրականացվի ավելի կարճ ժամանակահատվածում և միջոցների և աշխատանքի նվազագույն արժեքով:
Ընդհանուր բնակչության մեջ ուսումնասիրվող հատկանիշ ունեցող միավորների այն համամասնությունը կոչվում է ընդհանուր համամասնություն (նշվում է Ռ),իսկ ուսումնասիրված փոփոխականի բնութագրի միջին արժեքը ընդհանուր միջինն է (նշվում է NS):
Նմուշի բնակչության շրջանում ուսումնասիրվող հատկանիշի մասնաբաժինը կոչվում է ընտրանքի բաժին կամ մաս (նշվում է w- ով), ընտրանքի միջին արժեքը նմուշի միջին:
Եթե հետազոտության ընթացքում պահպանվում են նրա գիտական կազմակերպության բոլոր կանոնները, ապա ընտրանքի մեթոդը կտա բավականին ճշգրիտ արդյունքներ, և, հետևաբար, նպատակահարմար է օգտագործել այս մեթոդը `շարունակական դիտարկման տվյալները ստուգելու համար:
Այս մեթոդը լայն տարածում է գտել պետական և ոչ գերատեսչական վիճակագրության մեջ, քանի որ ուսումնասիրված միավորների նվազագույն քանակի ուսումնասիրության ժամանակ այն թույլ է տալիս ուշադիր և ճշգրիտ ուսումնասիրություն կատարել:
Ուսումնասիրված վիճակագրական պոպուլյացիան բաղկացած է տարբեր բնութագրիչներով միավորներից: Նմուշի բնակչության կազմը կարող է տարբերվել ընդհանուր բնակչության կազմից, ընտրանքի և ընդհանուր բնակչության բնութագրիչների միջև այս անհամապատասխանությունը ընտրանքի սխալն է:
Նմուշի դիտարկման բնորոշ սխալները բնութագրում են ընտրանքի դիտման տվյալների և ամբողջ բնակչության միջև եղած անհամապատասխանության չափը: Նմուշառման ընթացքում առաջացած սխալները կոչվում են ներկայացուցչականության սխալներ և բաժանվում են պատահական և համակարգված:
Եթե նմուշի բնակչությունը ճշգրիտ չի վերարտադրում ամբողջ պոպուլյացիան դիտարկումների անխափան բնույթի պատճառով, ապա դա կոչվում է պատահական սխալներ, և դրանց չափերը որոշվում են բավարար ճշգրտությամբ `մեծ թվերի օրենքի և հավանականության տեսության հիման վրա:
Համակարգված սխալներն առաջանում են դիտարկման համար բնակչության միավորների ընտրության ժամանակ պատահականության սկզբունքի խախտման արդյունքում:
2. Ընտրության տեսակները և սխեմաները
Նմուշառման սխալի չափը և դրա որոշման մեթոդները կախված են ընտրության տեսակից և սխեմայից:
Դիտորդական ստորաբաժանումների ընտրության չորս տեսակ կա.
1) պատահական;
2) մեխանիկական;
3) բնորոշ;
4) սերիական (բնադրված):
Պատահական նմուշառում- պատահական նմուշի ընտրության ամենատարածված մեթոդը, այն կոչվում է նաև վիճակահանության մեթոդ, որում վիճակագրական բնակչության յուրաքանչյուր միավորի համար պատրաստվում է սերիական համարով տոմս:
Ավելին, վիճակագրական բնակչության անհրաժեշտ քանակի միավորները պատահականորեն ընտրվում են: Այս պայմաններում դրանցից յուրաքանչյուրն ունի նմուշում ընդգրկվելու նույն հավանականությունը, օրինակ ՝ շահումների խաղարկությունները, երբ թողարկված տոմսերի ընդհանուր թվից պատահականորեն ընտրվում է այն թվերի որոշակի մասը, որոնց վրա ընկնում են շահումները: Միևնույն ժամանակ, բոլոր թվերին տրվում է նմուշի մեջ մտնելու հավասար հնարավորություն:
Մեխանիկական ընտրություն- սա մեթոդ է, երբ ամբողջ բնակչությունը ըստ պատահական չափանիշի բաժանվում է համասեռ ծավալի խմբերի, այնուհետև յուրաքանչյուր խմբից վերցվում է միայն մեկ միավոր: Ուսումնասիրված վիճակագրական բնակչության բոլոր միավորները նախապես դասավորված են որոշակի հերթականությամբ, բայց կախված նմուշի չափը, միավորների պահանջվող քանակը մեխանիկորեն ընտրվում է որոշակի ընդմիջումով ...
Տիպիկ ընտրություն -Սա մի մեթոդ է, որով ուսումնասիրված վիճակագրական պոպուլյացիան ըստ նշանակալի, բնորոշ հատկանիշի բաժանվում է որակապես միատարր, նմանատիպ խմբերի, այնուհետև այս խմբից յուրաքանչյուրից պատահականորեն ընտրվում է որոշակի քանակությամբ միավոր `համամասնորեն խմբի հատուկ քաշին: ամբողջ բնակչությունը:
Տիպիկ ընտրությունը տալիս է ավելի ճշգրիտ արդյունքներ, քանի որ այն ներառում է նմուշի բոլոր բնորոշ խմբերի ներկայացուցիչներին:
Սերիական (ներկառուցված) ընտրություն:Ամբողջ խմբերը (շարքեր, բներ), պատահական կամ մեխանիկորեն ընտրված, ենթակա են ընտրության: Յուրաքանչյուր այդպիսի խմբի և շարքի համար շարունակական դիտարկում է իրականացվում, և արդյունքները փոխանցվում են ամբողջ բնակչությանը:
Նմուշառման ճշգրտությունը կախված է նաև ընտրության սխեմայից: Նմուշառումը կարող է իրականացվել կրկնվող և չկրկնվող ընտրանքի սխեմայի համաձայն:
Կրկնվող ընտրություն:Յուրաքանչյուր ընտրված միավոր կամ շարք վերադարձվում է ամբողջ բնակչությանը և կարող է վերադարձվել նմուշին: Սա այսպես կոչված վերադարձված գնդակի սխեման է:
Չկրկնվող ընտրություն:Յուրաքանչյուր հետազոտված ստորաբաժանում դուրս է բերվում և չի վերադարձվում համախառն, ուստի այն չի ենթարկվում վերանայման: Այս սխեման կոչվում է չվերադարձված գնդակ:
Կրկնվող ընտրանքը տալիս է ավելի ճշգրիտ արդյունքներ, քանի որ նույն ընտրանքի չափի համար դիտարկումը ներառում է ուսումնասիրված բնակչության ավելի շատ միավորներ:
Համակցված ընտրությունկարող է անցնել մեկ կամ մի քանի քայլ: Նմուշը կոչվում է մեկ փուլ, եթե հետազոտվում են մեկ անգամ ընտրված բնակչության միավորները:
Նմուշը կոչվում է բազմափուլ, եթե բնակչության ընտրությունը անցնում է փուլերով, հաջորդական փուլերով, և յուրաքանչյուր փուլ, ընտրության փուլ, ունի ընտրության իր միավորը:
Բազմաֆազ ընտրանք - ընտրանքի բոլոր փուլերում պահպանվում է նմուշառման նույն միավորը, սակայն իրականացվում են ընտրանքային հետազոտությունների մի քանի փուլեր, որոնք տարբերվում են հետազոտության ծրագրի լայնությամբ և ընտրանքի չափով:
Ընդհանուր բնակչության և ընտրանքային բնակչության պարամետրերի բնութագրերը նշվում են հետևյալ խորհրդանիշներով.
Ն- ընդհանուր բնակչության ծավալը.
n- նմուշի չափը;
X- ընդհանուր միջին;
ԱԱ- միջին նմուշ;
Ռ- ընդհանուր բաժնեմաս;
w -ընտրովի բաժնետոմս;
2 - ընդհանուր շեղում (ընդհանուր բնակչության մեջ հատկանիշի շեղում);
2 - նույն հատկանիշի ընտրանքային շեղում.
? - ընդհանուր բնակչության ստանդարտ շեղում;
? - նմուշի ստանդարտ շեղում:
3. Նմուշառման սխալներ
Նմուշի դիտարկման յուրաքանչյուր միավոր պետք է ունենա ընտրության հավասար հնարավորություն մյուսների հետ. Սա ինքն պատահական ընտրանքի հիմքն է:
Ինքնուրույն պատահական ընտրանք - Սա ամբողջ ընդհանուր բնակչությունից միավորների ընտրություն է `վիճակահանությամբ կամ այլ նման եղանակով:
Պատահականության սկզբունքն այն է, որ նմուշից օբյեկտի ներառման կամ բացառման վրա չի կարող ազդել որևէ այլ գործոն, քան դեպքը:
Նմուշի բաժնեմասԱրդյո՞ք նմուշի միավորների քանակի հարաբերակցությունը ընդհանուր բնակչության միավորների թվին.
Իր մաքուր տեսքով ճիշտ պատահական ընտրությունը նախնականն է ընտրության բոլոր այլ տեսակների միջև, այն պարունակում և իրականացնում է ընտրովի վիճակագրական դիտարկման հիմնական սկզբունքները:
Նմուշառման մեթոդում օգտագործվող ընդհանրացնող ցուցանիշների երկու հիմնական տեսակներն են քանակական բնութագրի միջին արժեքը և այլընտրանքային բնութագրի հարաբերական արժեքը:
Նմուշի կոտորակը (w) կամ մասնավորը որոշվում է ուսումնասիրված հատկությամբ միավորների թվի հարաբերակցությամբ մ,նմուշի միավորների ընդհանուր թվին (n).
Նմուշառման ցուցանիշների հուսալիությունը բնութագրելու համար առանձնանում են ընտրանքի միջին և սահմանային սխալները:
Նմուշառման սխալը, որը նաև կոչվում է ներկայացուցչականության սխալ, համապատասխան ընտրանքի և ընդհանուր բնութագրերի միջև տարբերությունն է.
?x = | x - x |;
?w = | x - p |.
Նմուշառման սխալը բնորոշ է միայն ընտրանքային դիտարկումներին
Նմուշի միջին և ընտրանքային մասնաբաժինը- դրանք պատահական փոփոխականներ են, որոնք տարբեր արժեքներ են ընդունում `կախված ուսումնասիրված վիճակագրական պոպուլյացիայի միավորներից, որոնք ներառվել են նմուշում: Ըստ այդմ, ընտրանքային սխալները նույնպես պատահական արժեքներ են և կարող են նաև տարբեր արժեքներ ընդունել: Հետևաբար, որոշվում է հնարավոր սխալների միջինը `ընտրանքի միջին սխալը:
Նմուշառման միջին սխալը որոշվում է ընտրանքի չափով. Որքան մեծ է թիվը, այլ բաներ հավասար են, այնքան փոքր է միջին ընտրանքի սխալը: Ընդհանուր բնակչության աճող թվաքանակը ծածկելով ընտրանքային հետազոտությամբ ՝ մենք ավելի ու ավելի ճշգրիտ ենք բնութագրում ընդհանուր ընդհանուր բնակչությանը:
Նմուշառման միջին սխալը կախված է ուսումնասիրված հատկության տատանումների աստիճանից, իր հերթին տատանումների աստիճանը բնութագրվում է շեղումով: 2 կամ w (l - w)- այլընտրանքային հատկանիշի համար: Որքան քիչ է հատկանիշի և շեղման տատանումը, այնքան քիչ է ընտրանքի միջին սխալը և հակառակը:
Պատահական կրկնակի ընտրանքի համար միջին սխալները տեսականորեն հաշվարկվում են ՝ օգտագործելով հետևյալ բանաձևերը.
1) միջին քանակական հատկանիշի համար.
որտե՞ղ 2 - քանակական հատկության շեղման միջին արժեքը:
2) բաժնետոմսի համար (այլընտրանքային հատկանիշ).
Այսպիսով, ինչպե՞ս է ընդհանուր բնակչության մեջ մի հատկության շեղումը: 2 -ը ճշգրիտ հայտնի չէ, գործնականում նրանք օգտագործում են S 2 շեղման արժեքը, որը հաշվարկվում է ընտրանքային պոպուլյացիայի համար `մեծ թվերի օրենքի հիման վրա, ըստ որի` բավականաչափ մեծ նմուշի չափ ունեցող ընտրանքի բնակչությունը ճշգրիտ վերարտադրում է ընդհանուր բնակչությունը:
Պատահական նմուշառման միջին ընտրանքի սխալի բանաձևերը հետևյալն են. Քանակական հատկանիշի միջին արժեքի համար. Ընդհանուր շեղումը ընտրովիի միջոցով արտահայտվում է հետևյալ կերպ.
որտեղ S2- ը շեղման արժեքն է:
Մեխանիկական նմուշառում- Սա ընդհանուր բնակչությունից նմուշի միավորների ընտրությունն է, որը բաժանված է հավասար խմբերի `չեզոք չափանիշի համաձայն. կատարվում է այնպես, որ յուրաքանչյուր այդպիսի խմբից ընտրվի միայն մեկ միավոր:
Մեխանիկական ընտրության ժամանակ ուսումնասիրվող վիճակագրական պոպուլյացիայի միավորները նախապես դասավորված են որոշակի հերթականությամբ, որից հետո որոշակի ընդմիջումով մեխանիկորեն ընտրվում են որոշակի քանակությամբ միավորներ: Ավելին, ընդհանուր բնակչության ընդմիջման չափը հավասար է ընտրանքային մասնաբաժնի փոխադարձությանը:
Բավական մեծ բնակչությամբ, մեխանիկական ընտրությունը արդյունքների ճշգրտության առումով մոտ է պատահականին: Հետևաբար, մեխանիկական ընտրության միջին սխալը որոշելու համար օգտագործվում են ինքն պատահական ոչ կրկնվող նմուշառման բանաձևերը:
Տարբեր բնակչությունից միավորներ ընտրելու համար օգտագործվում է այսպես կոչված տիպիկ նմուշառում, այն օգտագործվում է այն դեպքում, երբ ընդհանուր բնակչության բոլոր միավորները կարելի է բաժանել մի քանի որակապես միատարր, նմանատիպ խմբերի `ըստ բնութագրերի, որոնցից կախված են ուսումնասիրված ցուցանիշները:
Հետո, յուրաքանչյուր տիպիկ խմբից, ընտրանքային պոպուլյացիայի մեջ միավորների անհատական ընտրությունը կատարվում է ինքն պատահական կամ մեխանիկական ընտրանքով:
Տիպիկ նմուշառումը սովորաբար օգտագործվում է բարդ վիճակագրական պոպուլյացիաների ուսումնասիրության ժամանակ:
Տիպիկ նմուշառումը տալիս է ավելի ճշգրիտ արդյունքներ: Բնակչության ընդհանուր բնութագրումը ապահովում է նման նմուշի ներկայացուցչականությունը, յուրաքանչյուր տիպաբանական խմբի ներկայացվածությունը դրանում, ինչը հնարավորություն է տալիս բացառել միջխմբային շեղման ազդեցությունը միջին ընտրանքի սխալի վրա: Հետեւաբար, տիպիկ նմուշի միջին սխալը որոշելիս ներխմբային շեղումների միջինը օգտագործվում է որպես տատանումների ցուցանիշ:
Սերիական նմուշառումը ներառում է հավասար խմբերի ընդհանուր բնակչությունից պատահական ընտրություն `բոլոր խմբերին նման խմբերում դիտարկման ենթարկելու համար:
Քանի որ առանց բացառության բոլոր միավորները ուսումնասիրվում են խմբերի ներսում (սերիաներ), ընտրանքի միջին սխալը (հավասար չափերի սերիա ընտրելիս) կախված է միայն միջխմբային (միջսերիալների) շեղումից:
4. Ընդհանուր բնակչությանը ընտրանքային արդյունքների բաշխման եղանակներ
Նմուշի արդյունքների հիման վրա ընդհանուր բնակչության բնութագրումը նմուշի դիտարկման վերջնական նպատակն է:
Նմուշառման մեթոդը օգտագործվում է նմուշի որոշակի ցուցանիշների համար ընդհանուր բնակչության բնութագրերը ստանալու համար: Կախված ուսումնասիրության նպատակներից, դա իրականացվում է ընդհանուր բնակչության ընտրանքային ցուցանիշների ուղղակի վերահաշվարկով կամ ուղղիչ գործոնների հաշվարկման մեթոդով:
Ուղղակի վերահաշվարկի մեթոդն այն է, որ դրա հետ միասին ընտրանքային մասնաբաժնի ցուցանիշները wկամ միջին ԱԱվերաբերում է ընդհանուր բնակչությանը `հաշվի առնելով ընտրանքի սխալը:
Ուղղիչ գործոնների մեթոդը օգտագործվում է այն դեպքում, երբ ընտրանքի մեթոդի նպատակը ամբողջական հաշվառման արդյունքների հստակեցումն է: Այս մեթոդը օգտագործվում է բնակչության շրջանում անասունների տարեկան մարդահամարի տվյալները ճշգրտելու համար:
Վիճակագրական բնակչություն- զանգվածների, տիպականության, որակական միատարրության և տատանումների առկայությամբ միավորների ամբողջություն:
Վիճակագրական բնակչությունը բաղկացած է նյութապես գոյություն ունեցող օբյեկտներից (աշխատողներ, ձեռնարկություններ, երկրներ, տարածաշրջաններ), օբյեկտ է:
Համախառն միավոր- վիճակագրական բնակչության յուրաքանչյուր առանձին միավոր:
Միևնույն վիճակագրական պոպուլյացիան կարող է մի հատկանիշում լինել միատարր, իսկ մյուսում ՝ տարասեռ:
Որակական միատեսակություն- ինչ -ինչ պատճառներով ագրեգատի բոլոր միավորների նմանությունը և մնացած բոլորի նմանությունը:
Վիճակագրական բնակչության մեջ բնակչության մեկ միավորի և մյուսի միջև եղած տարբերությունները հաճախ քանակական բնույթ են կրում: Բնակչության տարբեր միավորների բնութագրի արժեքների քանակական փոփոխությունները կոչվում են տատանումներ:
Առանձնահատկության տատանում- հատկության քանակական փոփոխություն (քանակական հատկանիշի համար) բնակչության մեկ միավորից մյուսը անցնելու ընթացքում:
ՆշանԱյն միավորների, առարկաների և երևույթների հատկություն, բնութագրական հատկություն կամ այլ հատկություն է, որը կարելի է դիտարկել կամ չափել: Նշանները բաժանվում են քանակական և որակական: Բնակչության առանձին միավորներում հատկության արժեքի բազմազանությունն ու փոփոխականությունը կոչվում է տատանում.
Հատկանշական (որակական) բնութագրերը չեն համապատասխանում թվային արտահայտությանը (բնակչության կազմը ըստ սեռի): Քանակական բնութագրերը թվայինորեն արտահայտված են (բնակչության կազմը ըստ տարիքների):
Ինդեքս- դա միավորների կամ ամբողջության ցանկացած գույքի քանակականորեն ամփոփող որակական բնութագիր է ժամանակի և վայրի որոշակի պայմաններում:
Հաշվի քարտՄի շարք ցուցանիշներ են, որոնք համակողմանիորեն արտացոլում են ուսումնասիրվող երևույթը:
Օրինակ, աշխատավարձը ուսումնասիրվում է.- Առանձնահատկություն - աշխատավարձ
- Վիճակագրական բնակչություն `բոլոր աշխատակիցները
- Ընդհանուր միավոր `յուրաքանչյուր աշխատող
- Որակական միատարրություն `կուտակված աշխատավարձ
- Նշանի տատանում - մի շարք թվեր
Ընդհանուր բնակչությունը և նմուշը դրանից
Հիմքը մեկ կամ մի քանի հատկանիշների չափման արդյունքում ստացված տվյալների ամբողջությունն է: Փաստորեն դիտարկվող օբյեկտների խումբը, որը վիճակագրորեն ներկայացված է պատահական փոփոխականի մի շարք դիտարկումներով, է նմուշառումև ենթադրաբար գոյություն ունեցող (ենթադրյալ) - ընդհանուր բնակչությունը... Ընդհանուր բնակչությունը կարող է սահմանափակ լինել (դիտարկումների թիվը N = կազմ) կամ անսահման ( N =), իսկ ընդհանուր բնակչությունից նմուշը միշտ սահմանափակ թվով դիտարկումների արդյունք է: Նմուշ կազմող դիտարկումների թիվը կոչվում է նմուշի չափը... Եթե նմուշի չափը բավականաչափ մեծ է ( n →) նմուշը համարվում է մեծհակառակ դեպքում այն կոչվում է նմուշ սահմանափակ ծավալ... Նմուշը համարվում է փոքրեթե միաչափ պատահական փոփոխականի չափման ժամանակ ընտրանքի չափը չի գերազանցում 30-ը ( n<= 30 ), և մի քանիսը չափելիս ( կ) բազմաչափ տարածության առանձնահատկությունները, հարաբերակցությունը nԴեպի կավելի քիչ քան 10 (հ / կ< 10) ... Նմուշի ձևերը տատանումների տիրույթեթե նրա անդամներն են հերթական վիճակագրությունայսինքն ՝ պատահական փոփոխականի ընտրանքային արժեքներ ԱԱդասավորված են աճման կարգով (դասակարգված), հատկության արժեքները կոչվում են ընտրանքներ.
Օրինակ... Գրեթե պատահականորեն ընտրված օբյեկտների հավաքածուն `Մոսկվայի մեկ վարչական շրջանի առևտրային բանկերը, կարող են դիտվել որպես օրինակ այս շրջանի բոլոր առևտրային բանկերի ընդհանուր բնակչությունից և որպես օրինակ` Մոսկվայի բոլոր առևտրային բանկերի ընդհանուր բնակչությունից: , ինչպես նաև երկրի առևտրային բանկերի նմուշ և այլն:
Նմուշառման հիմնական մեթոդները
Վիճակագրական եզրակացությունների հուսալիությունը և արդյունքների իմաստալից մեկնաբանությունը կախված են դրանից ներկայացուցչականություննմուշառում, այսինքն. ընդհանուր բնակչության հատկությունների լիարժեքությունն ու համարժեքությունը, որոնց նկատմամբ այս նմուշը կարելի է համարել ներկայացուցչական: Բնակչության վիճակագրական հատկությունների ուսումնասիրությունը կարող է կազմակերպվել երկու եղանակով շարունակականեւ անընդհատ Շարունակական դիտարկումնախատեսում է բոլորի հետազոտություն միավորներսովորել է ագրեգատը, ա անընդհատ (ընտրովի) դիտարկում- դրա միայն մասերը:
Գոյություն ունեն նմուշների դիտման կազմակերպման հինգ հիմնական եղանակ.
1. պարզ պատահական ընտրություն, որի դեպքում օբյեկտները պատահականորեն արդյունահանվում են օբյեկտների ընդհանուր պոպուլյացիայից (օրինակ ՝ օգտագործելով աղյուսակ կամ պատահական թվերի գեներատոր), որոնցից յուրաքանչյուրի հավանական նմուշները հավասար հավանականություն ունեն: Նման նմուշները կոչվում են պատշաճ պատահական;
2. պարզ ընտրություն `օգտագործելով սովորական ընթացակարգիրականացվում է մեխանիկական բաղադրիչի միջոցով (օրինակ ՝ ամսաթիվ, շաբաթվա օր, բնակարանի համար, այբուբենի տառ և այլն), և այսպես ստացված նմուշները կոչվում են մեխանիկական;
3. շերտավորվածընտրությունը բաղկացած է այն հանգամանքից, որ ծավալի ընդհանուր բնակչությունը ստորաբաժանվում է ծավալի ենթախմբերի կամ շերտերի (շերտերի) այնպես, որ. Շերտերը վիճակագրական բնութագրերի առումով միատարր օբյեկտներ են (օրինակ ՝ բնակչությունը ըստ տարիքային խմբերի կամ սոցիալական խավերի բաժանվում է շերտերի, ձեռնարկությունները ՝ ըստ արդյունաբերության): Այս դեպքում նմուշները կոչվում են շերտավորված(հակառակ դեպքում, շերտավորված, բնորոշ, գոտիավորված);
4. մեթոդներ սերիականընտրությունը օգտագործվում է ձևավորման համար սերիականկամ բնադրված նմուշներ... Նրանք հարմար են, եթե անհրաժեշտ է միանգամից ուսումնասիրել «բլոկ» կամ մի շարք օբյեկտներ (օրինակ ՝ ապրանքների խմբաքանակ, որոշակի շարքի արտադրանք կամ երկրի տարածքային-վարչական բաժանման բնակչություն): Սերիաների ընտրությունը կարող է իրականացվել զուտ պատահական կամ մեխանիկական եղանակով: Այս դեպքում իրականացվում է ապրանքների որոշակի խմբաքանակի կամ ամբողջ տարածքային միավորի (բնակելի շենք կամ եռամսյակ) ամբողջական հետազոտություն.
5. համակցված(քայլ առ քայլ) ընտրությունը կարող է համատեղել ընտրության միանգամից մի քանի մեթոդներ (օրինակ ՝ շերտավորված և պատահական կամ պատահական և մեխանիկական); նման նմուշը կոչվում է համակցված.
Ընտրության տեսակները
Ըստ միտքտարբերակել անհատական, խմբային և համակցված ընտրությունը: Ժամը անհատական ընտրություննմուշի մեջ ընտրվում են ընդհանուր բնակչության առանձին միավորներ խմբերի ընտրություն- միավորների որակապես միատարր խմբեր (շարքեր), և համակցված ընտրությունենթադրում է առաջին և երկրորդ տեսակների համադրություն:
Ըստ մեթոդըընտրությունը տարբերակել կրկնվող և չկրկնվողնմուշ
Չկրկնվողկոչվում է ընտրություն, որի դեպքում նմուշի մեջ մտնող միավորը չի վերադառնում սկզբնական բնակչությանը և չի մասնակցում հետագա ընտրությանը. մինչդեռ ընդհանուր բնակչության միավորների թիվը Ննվազեցվում է ընտրության գործընթացում: Ժամը կրկնեցընտրություն բռնելնմուշի մեջ գրանցումից հետո ստորաբաժանումը վերադարձվում է ընդհանուր բնակչությանը և դրանով իսկ պահպանում է հավասար հնարավորություններ `այլ ստորաբաժանումների հետ միասին` հետագա ընտրության ընթացակարգում օգտագործվելու համար. մինչդեռ ընդհանուր բնակչության միավորների թիվը Նմնում է անփոփոխ (մեթոդը հազվադեպ է օգտագործվում սոցիալ-տնտեսական հետազոտություններում): Այնուամենայնիվ, մեծի հետ N (N ∞ ∞)համար բանաձևեր անկրկնելիընտրանքները մոտենում են նրանց, ում համար է կրկնեցընտրություն և գրեթե ավելի հաճախ օգտագործվում են վերջինները ( N = կազմ).
Ընդհանուր և ընտրանքային բնակչության պարամետրերի հիմնական բնութագրերը
Հետազոտության վիճակագրական եզրակացությունները հիմնված են պատահական փոփոխականի բաշխման վրա, մինչդեռ դիտարկված արժեքները (x 1, x 2, ..., x n)կոչվում են պատահական փոփոխականի իրացում ԱԱ(n- նմուշի չափն է): Պատահական փոփոխականի բաշխումը ընդհանուր բնակչության մեջ տեսական է, իդեալական, և դրա օրինակելի անալոգը էմպիրիկբաշխում. Որոշ տեսական բաշխումներ տրվում են վերլուծականորեն, այսինքն. նրանց ընտրանքներորոշեք բաշխման գործառույթի արժեքը յուրաքանչյուր կետում `պատահական փոփոխականի հնարավոր արժեքների տարածքում: Նմուշի համար բաշխման գործառույթը դժվար է որոշել, և երբեմն անհնար է, հետևաբար ընտրանքներգնահատվում են էմպիրիկ տվյալներից, այնուհետև դրանք փոխարինվում են տեսական բաշխումը նկարագրող վերլուծական արտահայտությամբ: Այս դեպքում ենթադրությունը (կամ վարկածը) բաշխման տեսակի մասին կարող է լինել վիճակագրորեն ճիշտ և սխալ: Բայց ամեն դեպքում, նմուշից վերակառուցված էմպիրիկ բաշխումը միայն կոպիտ է բնութագրում իրականը: Բաշխման ամենակարևոր պարամետրերն են ակնկալվող արժեքըև շեղում:
Իրենց բնույթով բաշխումներն են շարունակականեւ դիսկրետ... Առավել հայտնի շարունակական բաշխումն է նորմալ... Պարամետրերի ընտրովի անալոգներ և դրա համար են `միջին արժեքը և էմպիրիկ շեղումը: Սոցիալ-տնտեսական հետազոտությունների առանձին տարբերակներից, առավել հաճախ օգտագործվողը այլընտրանքային (երկփեղկված)բաշխում. Այս բաշխման մաթեմատիկական ակնկալիքի պարամետրը արտահայտում է հարաբերական արժեքը (կամ բաժանել) ուսումնասիրվող հատկանիշ ունեցող բնակչության միավորները (դա նշվում է տառով). բնակչության այն մասնաբաժինը, որը չունի այս հատկությունը, նշվում է տառով q (q = 1 - p)... Այլընտրանքային բաշխման շեղումը ունի նաև էմպիրիկ անալոգ:
Բաշխման պարամետրերի բնութագրերը հաշվարկվում են տարբեր եղանակներով `կախված բաշխման տեսակից և բնակչության միավորների ընտրության եղանակից: Տեսական և էմպիրիկ բաշխումների համար հիմնականները տրված են աղյուսակում: 1.
Նմուշի կոտորակ k nնմուշի միավորների քանակի հարաբերությունն է ընդհանուր բնակչության միավորների թվին.
k n = n / N.
Նմուշ կոտորակ wԱրդյո՞ք միավորների հարաբերակցությունը ուսումնասիրված հատկության հետ xնմուշի չափին n:
w = n n / n.
Օրինակ. 1000 միավոր պարունակող ապրանքների խմբաքանակում ՝ 5% նմուշով ընտրանքային կոտորակ k nբացարձակ արժեքով `50 միավոր: (n = N * 0.05); եթե այս նմուշում հայտնաբերվել է 2 թերի արտադրանք, ապա ընտրովի թափոնների մակարդակը wկլինի 0.04 (w = 2/50 = 0.04 կամ 4%):
Քանի որ ընտրանքային բնակչությունը տարբերվում է ընդհանուր բնակչությունից, ապա նմուշառման սխալներ.
Աղյուսակ 1. Ընդհանուր և ընտրանքային բնակչության հիմնական պարամետրերը
Նմուշառման սխալներ
(Անկացած (հիմնավոր և ընտրովի) դեպքում կարող են առաջանալ երկու տեսակի սխալներ `գրանցում և ներկայացուցչականություն: Սխալներ Գրանցումկարող է ունենալ պատահականեւ համակարգվածբնավորությունը: Պատահականսխալները կազմված են բազմաթիվ տարբեր անվերահսկելի պատճառներից, ակամա են և սովորաբար իրար հավասարակշռում են (օրինակ ՝ սենյակում ջերմաստիճանի տատանումների ժամանակ գործիքի ընթերցումների փոփոխությունները):
Համակարգվածսխալները տենդենցային են, քանի որ դրանք խախտում են նմուշի օբյեկտների ընտրության կանոնները (օրինակ ՝ չափումների շեղումներ չափման սարքի պարամետրը փոխելիս):
Օրինակ.Քաղաքում բնակչության սոցիալական կարգավիճակը գնահատելու համար նախատեսվում է հետազոտել ընտանիքների 25% -ը: Եթե, միևնույն ժամանակ, յուրաքանչյուր չորրորդ բնակարանի ընտրությունը հիմնված է նրա թվի վրա, ապա կա միայն մեկ տեսակի (օրինակ ՝ մեկ սենյականոց) բնակարանների ընտրության վտանգ, ինչը կապահովի համակարգված սխալ և կխեղաթյուրի արդյունքները; Բնակարանի համարի ընտրությունը վիճակախաղով ավելի նախընտրելի է, քանի որ սխալը պատահական կլինի:
Ներկայացուցչական սխալներբնորոշ են միայն ընտրովի դիտարկմանը, դրանք հնարավոր չէ խուսափել և դրանք առաջանում են այն բանի արդյունքում, որ ընտրանքը լիովին չի վերարտադրում ընդհանուր բնակչությանը: Նմուշից ստացված ցուցանիշների արժեքները տարբերվում են ընդհանուր բնակչության նույն արժեքների ցուցանիշներից (կամ ստացվել են շարունակական դիտարկումների միջոցով):
Նմուշի դիտարկման սխալընդհանուր բնակչության պարամետրի արժեքի և դրա ընտրանքի արժեքի տարբերությունն է: Քանակական բնութագրի միջին արժեքի համար այն հավասար է., Իսկ բաժնեմասի համար (այլընտրանքային բնութագիր) -.
Նմուշառման սխալները բնորոշ են միայն ընտրանքային դիտարկումների համար: Որքան մեծ են այդ սխալները, այնքան էմպիրիկ բաշխումը տարբերվում է տեսականից: Էմպիրիկ բաշխման պարամետրերը պատահական արժեքներ են, հետևաբար, ընտրանքային սխալները նույնպես պատահական արժեքներ են, դրանք կարող են տարբեր արժեքներ վերցնել տարբեր նմուշների համար, և, հետևաբար, ընդունված է հաշվարկել միջին սխալ.
Նմուշառման միջին սխալկա մի արժեք, որն արտահայտում է ընտրանքի միջին ստանդարտ շեղումը մաթեմատիկական ակնկալիքից: Այս արժեքը, որը ենթակա է պատահական ընտրության սկզբունքին, հիմնականում կախված է նմուշի չափից և հատկանիշի տատանումների աստիճանից. ընտրանքի միջին սխալ: Ընդհանուր և ընտրանքային պոպուլյացիաների տատանումների միջև հարաբերակցությունը արտահայտվում է բանաձևով.
դրանք բավականաչափ մեծի համար կարող ենք ենթադրել, որ. Նմուշառման միջին սխալը ցույց է տալիս ընտրանքի բնակչության պարամետրի հնարավոր շեղումները ընդհանուր բնակչության պարամետրից: Սեղան 2 -ը ցույց է տալիս դիտման կազմակերպման տարբեր մեթոդների ընտրանքային միջին սխալը հաշվարկելու արտահայտություններ:
Աղյուսակ 2. Նմուշի միջին և համամասնության միջին սխալը (մ) տարբեր տեսակի նմուշների համար
Որտե՞ղ է ներխմբային ընտրանքային շեղումների միջինը շարունակական հատկանիշի համար.
Ներխմբային բաժնետոմսերի շեղումների միջին;
- ընտրված սերիաների թիվը, - սերիաների ընդհանուր թիվը.
 ,
,
որտեղ է -րդ շարքի միջինը.
- ընդհանուր միջինը ամբողջ նմուշի համար `շարունակական հատկանիշի համար.
 ,
,
որտե՞ղ է հատկանիշի մասնաբաժինը th շարքում.
- հատկության ընդհանուր մասնաբաժինը ամբողջ նմուշում:
Այնուամենայնիվ, միջին սխալի արժեքը կարելի է դատել միայն որոշակի, հավանականության P- ով (P ≤ 1): Լյապունով Ա.Մ. ապացուցեց, որ ընտրանքային միջոցների բաշխումը և, հետևաբար, դրանց շեղումները ընդհանուր միջինից, բավականաչափ մեծ թվով մոտավորապես ենթարկվում է բաշխման սովորական օրենքին, պայմանով, որ ընդհանուր բնակչությունը ունենա միջին միջին և սահմանափակ շեղում:
Մաթեմատիկորեն, միջին արժեքի այս արտահայտությունը արտահայտվում է հետևյալ կերպ.

իսկ կոտորակի համար (1) արտահայտությունը կունենա հետևյալ տեսքը.
որտեղ  -
կա նմուշառման սահմանային սխալ, որը միջին նմուշառման սխալի բազմապատիկն է ,
իսկ բազմազանության գործոնը ԱՄՆ -ի կողմից առաջարկվող Ուսանողի թեստն է («վստահության գործոն»): Գոսեթ (կեղծանուն «Ուսանող»); նմուշի տարբեր չափերի արժեքները պահվում են հատուկ աղյուսակում:
-
կա նմուշառման սահմանային սխալ, որը միջին նմուշառման սխալի բազմապատիկն է ,
իսկ բազմազանության գործոնը ԱՄՆ -ի կողմից առաջարկվող Ուսանողի թեստն է («վստահության գործոն»): Գոսեթ (կեղծանուն «Ուսանող»); նմուշի տարբեր չափերի արժեքները պահվում են հատուկ աղյուսակում:

Հետևաբար, արտահայտությունը (3) կարելի է կարդալ հետևյալ կերպ ՝ հավանականությամբ P = 0.683 (68.3%)կարելի է պնդել, որ ընտրանքի և ընդհանուր միջինի միջև տարբերությունը չի գերազանցի միջին սխալի մեկ արժեքը մ (t = 1), հավանականությամբ P = 0.954 (95.4%)- որ այն չի գերազանցի երկու միջին սխալների արժեքը մ (t = 2),հավանականությամբ P = 0.997 (99.7%)- չի գերազանցի երեք արժեքը մ (t = 3):Այսպիսով, հավանականությունը, որ այս տարբերությունը կգերազանցի միջին սխալը երեք անգամ սխալի մակարդակև այլևս չկա 0,3% .
Սեղան 3 -ը ցույց է տալիս նմուշառման սահմանային սխալի հաշվարկման բանաձևերը:
Աղյուսակ 3. Նմուշի սահմանային սխալ (D) միջին և համամասնություն (p) տարբեր տեսակի ընտրանքների դիտարկման համար
Նմուշի արդյունքների բաշխում ընդհանուր բնակչությանը
Ընտրովի դիտարկման վերջնական նպատակն է բնութագրել ընդհանուր բնակչությանը: Նմուշի փոքր չափերի դեպքում պարամետրերի (և) էմպիրիկ գնահատումները կարող են էապես շեղվել դրանց իսկական արժեքներից (և): Հետևաբար, անհրաժեշտ է դառնում սահմանների սահմանումը, որոնցում իրական արժեքները (և) ընկած են պարամետրերի ընտրանքային արժեքների համար (և):
Վստահության միջակայքընդհանուր բնակչության θ պարամետրը կոչվում է այս պարամետրի արժեքների պատահական տիրույթ, որը 1 -ին մոտ հավանականությամբ ( հուսալիություն) պարունակում է այս պարամետրի իրական արժեքը:
Մարգինալ սխալնմուշառում Δ թույլ է տալիս որոշել ընդհանուր բնակչության բնութագրերի և դրանց սահմանային արժեքները վստահության միջակայքերըորոնք հավասար են.
Ներքեւի գիծ վստահության միջակայքստացված հանելով սահմանային սխալնմուշի միջինից (բաժնեմաս), իսկ վերինինը `այն ավելացնելով:
Վստահության միջակայքմիջին հաշվով, այն օգտագործում է ընտրանքային սահմանային սխալ և տվյալ վստահության մակարդակի համար որոշվում է բանաձևով.
Սա նշանակում է, որ տրված հավանականությամբ Ռ, որը կոչվում է վստահության մակարդակ և եզակիորեն որոշվում է արժեքով տ, կարելի է պնդել, որ միջին արժեքի իրական արժեքը գտնվում է սկսած միջակայքում ![]() , և կոտորակի իրական արժեքը գտնվում է միջակայքում
, և կոտորակի իրական արժեքը գտնվում է միջակայքում
Վստահության երեք ստանդարտ մակարդակի վստահության միջակայքը հաշվարկելիս P = 95%, P = 99% և P = 99.9%արժեքը ընտրված է. Դիմումները `կախված ազատության աստիճանների քանակից: Եթե նմուշի չափը բավականաչափ մեծ է, ապա այդ հավանականություններին համապատասխանող արժեքները տհավասար են. 1,96, 2,58 եւ 3,29 ... Այսպիսով, ընտրանքի սահմանային սխալը հնարավորություն է տալիս որոշել ընդհանուր բնակչության բնութագրիչների և դրանց վստահության միջակայքերի սահմանափակող արժեքները.
Սոցիալ-տնտեսական հետազոտություններում ընտրովի դիտարկումների արդյունքների բաշխումը ընդհանուր բնակչությանը ունի իր առանձնահատկությունները, քանի որ այն պահանջում է իր բոլոր տեսակների և խմբերի ներկայացուցչականության ամբողջականությունը: Նման բաշխման հնարավորության հիմքը հաշվարկն է հարաբերական սխալ:

որտեղ Δ % - համեմատական սահմանային ընտրանքի սխալ; ,
Գոյություն ունի ընդհանուր բնակչության վրա ընտրանքային դիտարկումը տարածելու երկու հիմնական մեթոդ. ուղղակի փոխարկումը և գործակիցների մեթոդը.
Էությունը ուղղակի փոխակերպումբաղկացած է նմուշի միջին արժեքը !! \ overline (x) ընդհանուր բնակչության չափով բազմապատկելուց:
Օրինակ... Թող քաղաքում փոքրիկների միջին թիվը գնահատվի ընտրանքային մեթոդով և լինի մարդ: Եթե քաղաքում կա 1000 երիտասարդ ընտանիք, ապա քաղաքային մանկապարտեզներում անհրաժեշտ տեղերի քանակը ձեռք է բերվում այս միջինը բազմապատկելով ընդհանուր բնակչության N = 1000 չափի վրա, այսինքն. կկազմի 1200 տեղ:
Գործակիցների մեթոդընպատակահարմար է օգտագործել այն դեպքում, երբ կատարվում է ընտրովի դիտարկում ՝ շարունակական դիտարկման տվյալները պարզաբանելու համար:
Այս դեպքում օգտագործվում է բանաձևը.
որտեղ բոլոր փոփոխականները բնակչության թիվն են.
Պահանջվող նմուշի չափը
Աղյուսակ 4. Նմուշի դիտարկման կազմակերպման տարբեր տեսակների համար պահանջվող ընտրանքի չափը (n)
Նմուշառման թույլատրելի սխալի կանխորոշված արժեքով նմուշի դիտարկում պլանավորելիս անհրաժեշտ է ճիշտ գնահատել պահանջվող նմուշի չափը... Այս ծավալը կարող է որոշվել նմուշի դիտարկման թույլատրելի սխալի հիման վրա `տրված հավանականության հիման վրա, որը երաշխավորում է սխալի մակարդակի թույլատրելի արժեքը (հաշվի առնելով դիտարկումը կազմակերպելու եղանակը): Նմուշի պահանջվող չափը որոշելու բանաձևերը հեշտությամբ կարելի է ստանալ անմիջապես ընտրանքային սահմանային սխալի բանաձևերից: Այսպիսով, սահմանային սխալի արտահայտությունից.
նմուշի չափը ուղղակիորեն որոշվում է n:
Այս բանաձևը ցույց է տալիս, որ նվազագույն ընտրանքային սխալի նվազումով Δ նմուշի պահանջվող չափը զգալիորեն մեծանում է, ինչը համաչափ է Ուսանողի թեստի շեղման և քառակուսու հետ:
Դիտարկումների կազմակերպման հատուկ մեթոդի համար անհրաժեշտ նմուշի չափը հաշվարկվում է ըստ աղյուսակում տրված բանաձևերի: 9.4.
Գործնական հաշվարկման օրինակներ
Օրինակ 1. Միջին և վստահության միջակայքի հաշվարկ անընդհատ քանակական բնութագրի համար:
Պարտատերերի հետ հաշվարկների արագությունը գնահատելու համար բանկը կատարեց 10 վճարային փաստաթղթերի պատահական նմուշ: Նրանց արժեքները հավասար են (օրերով) `10; 3; 15; 15; 22; 7; ութ; 1; 19; քսան:
Անհրաժեշտ է հավանականությամբ P = 0.954որոշել սահմանային սխալը Δ միջին հաշվարկի և վստահության սահմանները հաշվարկների միջին ժամանակի համար:
Լուծում:Միջին արժեքը հաշվարկվում է աղյուսակից բերված բանաձևի միջոցով: 9.1 նմուշի համար
![]()
Շեղումը հաշվարկվում է աղյուսակից բերված բանաձևով: 9.1.
![]()
Օրվա միջին քառակուսի սխալը:
Միջին սխալը հաշվարկվում է բանաձևով.
![]()
դրանք միջինն է x ± m = 12.0 ± 2.3 օր.
Միջինի հուսալիությունը եղել է
![]()
Սահմանափակող սխալը հաշվարկվում է աղյուսակից բերված բանաձևով: 9.3 կրկնակի ընտրանքի համար, քանի որ բնակչության չափն անհայտ է, և P = 0.954վստահության մակարդակ:
Այսպիսով, միջին արժեքը հավասար է `x ± D =` x ± 2m = 12.0 ± 4.6, այսինքն. դրա իրական արժեքը տատանվում է 7,4 -ից 16,6 օրվա ընթացքում:
Օգտագործելով Ուսանողի սեղանը: Դիմումը թույլ է տալիս եզրակացնել, որ n = 10 - 1 = 9 աստիճանի ազատության դեպքում ստացված արժեքը հուսալի է ՝ 00 0.001 նշանակության մակարդակով, այսինքն. ստացված միջին արժեքը զգալիորեն տարբերվում է 0 -ից:
Օրինակ 2. Հավանականության գնահատում (ընդհանուր մասնաբաժին) p.
1000 ընտանիքի սոցիալական կարգավիճակի հետազոտման մեխանիկական ընտրանքային մեթոդով պարզվել է, որ ցածր եկամուտ ունեցող ընտանիքների մասնաբաժինը w = 0.3 (30%)(նմուշը եղել է 2% , այսինքն ՝ n / N = 0.02): Անհրաժեշտ է վստահության մակարդակով p = 0.997որոշեք ցուցանիշը Ռցածր եկամուտ ունեցող ընտանիքներ ամբողջ տարածաշրջանում:
Լուծում:Ըստ գործառույթի ներկայացված արժեքների Ф (t)գտնել տվյալ վստահության մակարդակի համար P = 0.997իմաստը t = 3(տես բանաձև 3): Բաժնետոմսերի սահմանային սխալ wորոշվում է աղյուսակի բանաձևով: 9.3 ոչ կրկնվող նմուշառման համար (մեխանիկական նմուշառումը միշտ էլ չի կրկնվում).
Մեջ սահմանային հարաբերական ընտրանքի սխալը % կլինի:
Մարզի ցածր եկամուտ ունեցող ընտանիքների հավանականությունը (ընդհանուր մասնաբաժինը) կլինի p = w ± Δ w, իսկ վստահության սահմանները p հաշվարկվում են կրկնակի անհավասարության հիման վրա.
w - Δ w ≤ p ≤ w - Δ w, այսինքն ՝ p- ի իրական արժեքը գտնվում է.
0,3 — 0,014 < p <0,3 + 0,014, а именно от 28,6% до 31,4%.
Այսպիսով, 0.997 հավանականությամբ կարելի է պնդել, որ ցածր եկամուտ ունեցող ընտանիքների մասնաբաժինը տարածաշրջանի բոլոր ընտանիքների միջև տատանվում է 28.6% -ից մինչև 31.4% -ի սահմաններում:
Օրինակ 3.Միջին և վստահության միջակայքի հաշվարկ դիսկրետ հատկանիշի համար, որը նշված է ընդմիջումներով:
Սեղան 5. սահմանվել է պատվերների արտադրության պատվերների բաշխում ըստ ձեռնարկության կողմից դրանց կատարման ժամկետների:
Աղյուսակ 5. Դիտարկումների բաշխում ըստ առաջացման ժամանակիԼուծում: Պատվերի կատարման միջին ժամանակը հաշվարկվում է բանաձևով.
Միջին ժամանակահատվածը կլինի.
= (3 * 20 + 9 * 80 + 24 * 60 + 48 * 20 + 72 * 20) / 200 = 23.1 ամիս:
Նույն պատասխանը մենք ստանում ենք, եթե աղյուսակի նախավերջին սյունակից օգտագործենք p i- ի տվյալները: 9.5 բանաձևով.
Նկատի ունեցեք, որ վերջին աստիճանավորման համար միջակայքի կեսը հայտնաբերվում է արհեստականորեն այն լրացնելով նախորդ դասակարգման միջակայքի լայնությամբ `60 - 36 = 24 ամիս:
Շեղումը հաշվարկվում է բանաձևով
![]()
որտեղ x i- միջակայքի տողի կեսը:
Հետեւաբար !! \ sigma = \ frac (20 ^ 2 + 14 ^ 2 + 1 + 25 ^ 2 + 49 ^ 2) (4), իսկ արմատը նշանակում է քառակուսի սխալ:
Միջին սխալը հաշվարկվում է ամսվա բանաձևի միջոցով, այսինքն. միջինն է !! \ overline (x) ± m = 23.1 ± 13.4:
Սահմանափակող սխալը հաշվարկվում է աղյուսակից բերված բանաձևով: 9.3 կրկնակի ընտրանքի համար, քանի որ բնակչության չափը անհայտ է, 0.954 վստահության մակարդակի համար.
Այսպիսով, միջինը հետևյալն է.
դրանք դրա իրական արժեքը տատանվում է 0 -ից 50 ամսվա ընթացքում:
Օրինակ 4.Առևտրային բանկում կորպորացիայի N = 500 ձեռնարկությունների պարտատերերի հետ հաշվարկների արագությունը որոշելու համար անհրաժեշտ է անցկացնել ընտրանքային ուսումնասիրություն `պատահական չկրկնվող ընտրության մեթոդով: Որոշեք նմուշի պահանջվող չափը n այնպես, որ P = 0.954 հավանականությամբ, նմուշի միջին սխալը չգերազանցի 3 օրը, եթե փորձարկման գնահատականները ցույց տվեցին, որ ստանդարտ շեղումը s- ը 10 օր է:
Լուծում... N- ի անհրաժեշտ ուսումնասիրությունների քանակը որոշելու համար մենք կօգտագործենք Աղյուսակից կրկնակի ընտրության բանաձևը: 9.4:

Դրա մեջ t- ի արժեքը որոշվում է P = 0.954 վստահության մակարդակից: Այն հավասար է 2. Արմատի միջին քառակուսին s = 10, ընդհանուր բնակչության չափը ՝ N = 500, իսկ միջինի սահմանային սխալը ՝ Δ x = 3. Այս արժեքները բանաձևի փոխարինելով ՝ ստանում ենք.
![]()
դրանք բավական է 41 ձեռնարկության օրինակ կազմել `պահանջվող պարամետրը գնահատելու համար` վարկատուների հետ հաշվարկների արագությունը:
Նմուշ - սա:
1) հետազոտության օբյեկտի այն տարրերի ամբողջությունը, որոնք ուղղակիորեն ուսումնասիրվելու են.
2) հետազոտության օբյեկտի տարրերի ընտրության մեթոդներն ու ընթացակարգերը:
Ընդհանուր բնակչություն - ուսումնասիրվող խնդրին առնչվող օբյեկտների ամբողջական փաթեթ: Սոցիոլոգիական հետազոտություններում, ինչպես G.S. ամենից հաճախ կան անհատների համախմբումներ `բնակչություն (քաղաքներ, երկրներ և այլն), սոցիալական խումբ (երիտասարդներ, գործազուրկներ, գործարարներ և այլն), զանգվածային լրատվության միջոցների լսարան (ՈMSԱԿ) և այլն: Այնուամենայնիվ, շատ դեպքերում , Գ.Ս ... կարող է բաղկացած լինել ավելի մեծ տարրերից (օբյեկտներից) `ընտանիքներ (տնային տնտեսություններ), ակադեմիական խմբեր, ձեռնարկություններ, կրոնական համայնքներ, առանձին բնակավայրեր կամ նահանգներ և այլն:
Նմուշի բնակչություն - ուսումնասիրության համար ընտրված ընդհանուր բնակչության օբյեկտների մի մասը `ընդհանուր ընդհանուր բնակչության վերաբերյալ եզրակացություն անելու համար:
Որպեսզի նմուշը հետազոտելով ձեռք բերված եզրակացությունը տարածվի ամբողջ ընդհանուր բնակչության վրա, նմուշը պետք է ունենա ներկայացուցչականության հատկություն:
Ներկայացուցչականություն Նմուշի ունակությունն է `ներկայացնել թիրախային բնակչությունը: Որքան ավելի ճշգրիտ է ընտրանքի կազմը ներկայացնում բնակչությունը ուսումնասիրվող հարցերի վերաբերյալ, այնքան ավելի բարձր է դրա ներկայացուցչականությունը:
ՕՐԻՆԱԿ. Ներկայացուցչականությունը կարելի է պատկերազարդել հետևյալ օրինակով: Ենթադրենք, որ բնակչությունը դպրոցի բոլոր աշակերտներն են (600 մարդ 20 դասարանից, յուրաքանչյուր դասարանից `30 հոգի): Ուսումնասիրության թեման ծխելու նկատմամբ վերաբերմունքն է: Ավագ դպրոցի 60 աշակերտներից բաղկացած նմուշը ներկայացնում է շատ ավելի վատ բնակչություն, քան նույն 60 աշակերտների ընտրանքը, որը ներառելու է յուրաքանչյուր դասարանից 3 աշակերտ: Դրա հիմնական պատճառը դասարաններում տարիքային անհավասար բաշխումն է: Հետևաբար, առաջին դեպքում ընտրանքի ներկայացուցչականությունը ցածր է, իսկ երկրորդ դեպքում `ներկայացուցչականությունը բարձր (մնացած բոլոր բաները հավասար են):
Նմուշի տեսակները
1. Պատահական նմուշառում:
1.1 Պարզ պատահական ընտրություն:
1.2 Սիստեմատիկ (կամ մեխանիկական) ընտրանքի մեթոդ.
1.3 Սերիական (բնադրված կամ խմբավորված) նմուշառում:
1.4 շերտավորված նմուշ:
2. Ոչ պատահական նմուշ (անհավանական):
2.2. Ինքնաբուխ նմուշառում:
2.3. Բազմաստիճան և միափուլ նմուշառում:
1. Պատահական նմուշառում:
Պատահական ընտրանքի առանձնահատկությունն այն է, որ ընդհանուր բնակչության բոլոր միավորներն ունեն ընտրանքում ընդգրկվելու հավասար հավանականություն: Պատահական նմուշառման ժամանակ, պատահականության սկզբունք... Նմուշառման շրջանակը կարող է լինել ձեռնարկության աշխատակիցների ցուցակներ, հեռախոսային տեղեկատուներ, մեքենաների սեփականատերերի գրանցման ցուցակներ, ընտրատեղամասերում ընտրողների ցուցակներ, տնային գրքեր, ինչպես նաև անձամբ սոցիոլոգի կողմից կազմված տարբեր ցուցակներ `կախված ուսումնասիրության նպատակներից (ցուցակ փողոցներ, որոնց վրա ընտրվում են հարցվողները):
Պատահական ընտրանքը սովորաբար օգտագործվում է հասարակական կարծիքի հարցումներում ՝ ընտրություններից առաջ, հանրաքվեներից և այլ հանրային միջոցառումներից առաջ:
ԳումարածԱյս մեթոդը պատահականության սկզբունքի ամբողջական պահպանումն է և, որպես հետևանք, համակարգված սխալներից խուսափելը:
Այս մեթոդի թերությունները.
- Ընդհանուր բնակչության տարրերի ցանկի անհրաժեշտությունը:
- Հարցման բարդությունը:
- համեմատաբար մեծ նմուշի չափ:
Վիճակագրության մեջ կան երկու հիմնական հետազոտական մեթոդներ `շարունակական և ընտրովի: Ընտրանքային ուսումնասիրություն իրականացնելիս պարտադիր է համապատասխանել հետևյալ պահանջներին `ընտրանքի բնակչության ներկայացուցչականությունը և բավարար թվով դիտորդական ստորաբաժանումներ: Դիտորդական միավորներ ընտրելիս դա հնարավոր է Օֆսեթ սխալներ, այսինքն ՝ այնպիսի իրադարձություններ, որոնց առաջացումը հնարավոր չէ ճշգրիտ կանխատեսել: Այս սխալները օբյեկտիվ են և բնական: Նմուշառման ուսումնասիրության ճշգրտության աստիճանը որոշելիս գնահատվում է նմուշառման գործընթացի ընթացքում առաջացող սխալի չափը ` Ներկայացուցչականության պատահական սխալ (Մ) — Դա իրական տարբերությունն է ընտրանքային հետազոտությունից ստացված միջին կամ հարաբերական արժեքների և համանման արժեքների միջև, որոնք կստացվեն ընդհանուր բնակչության վերաբերյալ հարցումից:
Հետազոտության արդյունքների հուսալիության գնահատումը ներառում է `
1. ներկայացուցչականության սխալներ
2. ընդհանուր բնակչության միջին (կամ հարաբերական) արժեքների վստահության սահմանները
3. միջին (կամ հարաբերական) արժեքների տարբերության վստահություն (ըստ t չափանիշի)
Ներկայացուցչականության սխալի հաշվարկ(մմ) թվաբանական միջին (M):
Որտեղ σ է ստանդարտ շեղումը. n նմուշի չափն է (> 30):
Հարաբերական արժեքի (Р) ներկայացուցչականության (mР) սխալի հաշվարկ.
Որտեղ P- ը համապատասխան հարաբերական արժեքն է (հաշվարկվում է, օրինակ,%-ով);
Q = 100 - Ρ% -ը P- ի փոխադարձն է. n - նմուշի չափը (n> 30)
Կլինիկական և փորձարարական աշխատանքներում հաճախ անհրաժեշտ է օգտագործել Փոքր նմուշ,Երբ դիտարկումների թիվը 30 -ից փոքր է կամ հավասար , Դիտարկումների թիվը կրճատվում է մեկով, այսինքն.
![]() ; .
; .
Ներկայացուցչական սխալի մեծությունը կախված է նմուշի չափից. Որքան մեծ է դիտարկումների քանակը, այնքան փոքր է սխալը: Նմուշի ցուցիչի հուսալիությունը գնահատելու համար որդեգրվում է հետևյալ մոտեցումը. Ցուցանիշը (կամ միջին արժեքը) պետք է 3 անգամ գերազանցի իր սխալը, այս դեպքում այն համարվում է հուսալի:
Սխալի մեծությունը իմանալը բավարար չէ նմուշառման ուսումնասիրության արդյունքներին վստահ լինելու համար, քանի որ ընտրանքի ուսումնասիրության հատուկ սխալը կարող է զգալիորեն ավելի մեծ (կամ պակաս) լինել, քան ներկայացուցչականության միջին սխալի արժեքը: Որպեսզի հետազոտողը ցանկանա հասնել արդյունքի, վիճակագրությունը օգտագործում է այնպիսի հասկացություն, ինչպիսին է սխալ կանխատեսման հավանականությունը, ինչը բնորոշ է ընտրովի կենսաբժշկական վիճակագրական ուսումնասիրությունների արդյունքների հուսալիությանը: Սովորաբար, կենսաբժշկական վիճակագրական ուսումնասիրություններ կատարելիս օգտագործվում է 95% կամ 99% անխափան կանխատեսման հավանականությունը: Ամենակրիտիկական դեպքերում, երբ անհրաժեշտ է հատկապես կարևոր եզրակացություններ անել տեսական կամ գործնական առումով, օգտագործվում է 99,7% -ի անթերի կանխատեսման հավանականությունը:
Անսխալ կանխատեսման հավանականության որոշակի աստիճանը համապատասխանում է որոշակի արժեքի Պատահական նմուշառման սահմանային սխալը (Δ - դելտա), որը որոշվում է բանաձևով.
Δ = t * m, որտեղ t- ը վստահության գործակիցն է, որը 95% անթերի կանխատեսման հավանականությամբ մեծ նմուշի համար կազմում է 2.6; 99% անխափան կանխատեսման հավանականությամբ `3.0; 99.7% - 3.3 առանց սխալների կանխատեսման հավանականությամբ և փոքր նմուշով այն որոշվում է Ուսանողի t արժեքների հատուկ աղյուսակով:
Օգտագործելով նմուշառման սահմանային սխալը (Δ), կարելի է որոշել Վստահության սահմաններ, որում, առանց սխալների կանխատեսման որոշակի հավանականությամբ, վիճակագրական մեծության փաստացի արժեքը , Բնութագրում է ամբողջ ընդհանուր բնակչությանը (միջին կամ հարաբերական):
Հետևյալ բանաձևերն օգտագործվում են վստահության սահմանները որոշելու համար.
1) միջին արժեքների համար.
Որտեղ Mgen - ընդհանուր բնակչության միջին վստահության սահմանները.
Msample - միջին , Ստացվել է ընտրանքային պոպուլյացիայի վերաբերյալ ուսումնասիրություն իրականացնելիս. t- ը վստահության գործակիցն է, որի արժեքը որոշվում է առանց սխալների կանխատեսման հավանականության աստիճանի, որով հետազոտողը ցանկանում է ստանալ արդյունքը. mM- ը միջինի ներկայացուցչականության սխալն է:
2) հարաբերական արժեքների համար.
Որտեղ Pgen - ընդհանուր բնակչության հարաբերական արժեքի վստահության սահմանները. Psyb - ընտրանքային պոպուլյացիայի վերաբերյալ ուսումնասիրություն կատարելիս ստացված հարաբերական արժեքը. t- ը վստահության գործոնն է. mP հարաբերական արժեքի ներկայացուցչականության սխալն է:
Վստահության սահմանները ցույց են տալիս, թե որքանով է ընտրանքի չափը տատանվում `կախված պատահական պատճառներից:
Փոքր թվով դիտումներով (n<30), для вычисления доверительных границ значение коэффициента t находят по специальной таблице Стьюдента. Значения t расположены в таблице на пересечении с избранной вероятностью безошибочного прогноза и строки, Ազատության աստիճանների քանակի նշում (n) , Որն է n-1:
Իրականում, մենք կսկսենք ոչ թե մեկ, այլ երեք հարցով. Ի՞նչ է նմուշառում: ե՞րբ է այն ներկայացուցչական ինչ է դա
Ագրեգատը Արդյո՞ք մեզ հետաքրքրող մարդկանց, կազմակերպությունների, իրադարձությունների որևէ խումբ, որի մասին մենք ցանկանում ենք եզրակացություններ անել, և տեղի է ունենում,կամ օբյեկտ, - նման հավաքածուի ցանկացած տարր 1 .Նմուշ - վերլուծության համար հատկացված դեպքերի (առարկաների) ցանկացած ենթախումբ: Եթե մենք ցանկանում ենք ուսումնասիրել նահանգի օրենսդիրների որոշումների կայացման գործունեությունը, մենք կարող ենք ուսումնասիրել նման գործունեությունը Վիրջինիա, Հյուսիսային Կարոլինա և Հարավային Կարոլինա նահանգների օրենսդիր մարմիններում, և ոչ բոլոր հիսուն նահանգներում և, դրա հիման վրա, տարածվելստացված տվյալները այն բնակչության համար, որից ընտրվել են այս երեք նահանգները: Եթե մենք ցանկանում ենք հետաքննել Փենսիլվանիայի ընտրողների նախընտրությունների համակարգը, մենք դա կարող ենք անել ՝ հարցազրույց վերցնելով Յու -ի 50 աշխատակցից: S. Steele »Պիտսբուրգում և տարածեք հարցման արդյունքները նահանգի բոլոր ընտրողներին: Նմանապես, եթե մենք ուզում ենք չափել քոլեջի ուսանողների ինտելեկտը, մենք կարող ենք փորձարկել Օհայոյի բոլոր պաշտպանական խաղացողները տվյալ ֆուտբոլային մրցաշրջանի համար, այնուհետև արդյունքները ընդհանրացնել այն բնակչությանը, որի մաս են նրանք: Յուրաքանչյուր օրինակում մենք գործում ենք հետևյալ կերպ. Մենք ստեղծում ենք ենթախումբ բնակչության ներսում մենք ուսումնասիրում ենք այս ենթախումբը կամ նմուշը մանրամասնորեն և մեր արդյունքները տարածում ենք ամբողջ բնակչության վրա: Սրանք ընտրանքի հիմնական փուլերն են:
Այնուամենայնիվ, ակնհայտ է թվում, որ այս նմուշներից յուրաքանչյուրն ունի զգալի թերություն: Օրինակ, մինչ Վիրջինիայի, Հյուսիսային Կարոլինայի և Հարավային Կարոլինայի օրենսդիր մարմինները նահանգի օրենսդիր մարմինների համախմբի մաս են կազմում, պատմական, աշխարհագրական և քաղաքական պատճառներով, նրանք, ամենայն հավանականությամբ, գործելու են շատ նման և շատ տարբեր ձևերով, քան օրենսդիր մարմինները նահանգներ, ինչպիսիք են Նյու Յորքը, Նեբրասկան և Ալյասկան: Թեև Պիտսբուրգի պողպատի հիսուն աշխատողները կարող են իսկապես լինել Փենսիլվանիայի ընտրողներ, սակայն նրանց սոցիալ -տնտեսական կարգավիճակը, կրթությունը և կյանքի փորձը, ամենայն հավանականությամբ, կունենան հայացքներ, որոնք տարբերվում են շատ նման ընտրողներից: Նմանապես, չնայած Օհայոյի ֆուտբոլիստները քոլեջի ուսանողներ են, նրանք տարբեր պատճառներով կարող են շատ տարբերվել մյուս ուսանողներից: Այլ կերպ ասած, չնայած այս ենթախմբերից յուրաքանչյուրն իսկապես նմուշ է, յուրաքանչյուրի անդամները համակարգվածորեն տարբերվում են իրենց ընտրած մնացած բնակչության մեծամասնությունից: Որպես առանձին խումբ, դրանցից ոչ մեկը բնորոշ չէ ընդհանուր բնակչության կարծիքների հատկությունների, վարքագծի շարժառիթների և բնութագրերի բաշխման առումով, որոնց հետ այն կապված է: Ըստ այդմ, քաղաքագետները կասեն, որ այս նմուշներից ոչ մեկը ներկայացուցչական չէ:
Ներկայացուցչական նմուշ - սա նմուշ է, որտեղ ընդհանուր բնակչության բոլոր հիմնական հատկանիշները, որոնցից վերցված է այս նմուշը, ներկայացված են մոտավորապես նույն համամասնությամբ կամ նույն հաճախականությամբ, որով այս հատկությունը հայտնվում է այս ընդհանուր բնակչության շրջանում: Այսպիսով, եթե բոլոր նահանգների օրենսդիր մարմինների 50% -ը հանդիպում են միայն երկու տարին մեկ, ապա նահանգի օրենսդիր մարմինների ներկայացուցչական նմուշի մոտավորապես կեսը պետք է այս տիպի լինի: Եթե Փենսիլվանիայի ընտրողների 30% -ը կապույտ է, ապա ներկայացուցչի մոտ 30% -ը Այս ընտրողների նմուշները (ոչ թե 100% -ով, ինչպես վերը նշված օրինակում) պետք է լինեն կապույտ օձիքով: Եվ եթե քոլեջի ուսանողների 2% -ը մարզիկներ են, քոլեջի ուսանողների ներկայացուցչական նմուշի մոտավորապես նույն համամասնությունը պետք է լինեն մարզիկներ: Այլ կերպ ասած, ներկայացուցչական նմուշը միկրոկոսմոս է, բնակչության ավելի փոքր, բայց ճշգրիտ մոդելը, որը պետք է ներկայացնի: Որքանով որ նմուշը ներկայացուցչական է, այդ նմուշի ուսումնասիրությունից արված եզրակացությունները կարելի է ապահով ենթադրել, որ վերաբերում են սկզբնական բնակչությանը: Արդյունքների այս տարածումը այն է, ինչ մենք անվանում ենք ընդհանրացում:
Թերևս գրաֆիկական պատկերազարդումը կօգնի պարզաբանել դա: Ենթադրենք, մենք ցանկանում ենք ուսումնասիրել ԱՄՆ չափահաս բնակչության շրջանում քաղաքական խմբերի անդամակցության օրինաչափությունները: Նկար 5.1 -ը ցույց է տալիս երեք շրջան ՝ բաժանված վեց հավասար հատվածների: Նկար 5.1 ա -ն ներկայացնում է դիտարկվող ամբողջ բնակչությունը: Բնակչության անդամները դասակարգվում են ըստ այն քաղաքական խմբերի (ինչպիսիք են կուսակցությունները և շահերի խմբերը), որոնց նրանք պատկանում են: Այս օրինակում յուրաքանչյուր մեծահասակ պատկանում է առնվազն մեկ և ոչ ավելի, քան վեց քաղաքական խմբերի. և անդամակցության այս վեց մակարդակները հավասարապես տարածված են ընդհանուրի մեջ (հետևաբար `հավասար հատվածներ): Ենթադրենք, մենք ցանկանում ենք ուսումնասիրել խմբին միանալու շարժառիթները, խմբի ընտրությունը և մասնակցության ձևերը, սակայն սահմանափակ ռեսուրսների պատճառով մենք ի վիճակի ենք հետազոտել բնակչության յուրաքանչյուր վեց անդամից միայն մեկին: Ո՞վ պետք է ընտրվի վերլուծության համար:
Բրինձ 5.1. Նմուշառում ընդհանուր բնակչությունից
Տվյալ չափի հնարավոր նմուշներից մեկը պատկերված է Նկար 5.1 բ -ի ստվերավորված տարածքով, սակայն այն հստակ չի արտացոլում բնակչության կառուցվածքը: Եթե ընդհանրացնենք այս նմուշը, ապա եզրակացություն կանենք (1), որ բոլոր չափահաս ամերիկացիները պատկանում են հինգ քաղաքական խմբերի, և (2), որ ամերիկյան բոլոր խմբային վարքագիծը համընկնում է հենց հինգ խմբերի վարքագծի հետ: Այնուամենայնիվ, մենք գիտենք, որ առաջին եզրակացությունը ճիշտ չէ, և դա կարող է կասկածներ հարուցել մեր մեջ երկրորդի վավերականության վերաբերյալ: Այսպիսով, Նկար 5.1 բ -ում ներկայացված նմուշը ներկայացուցչական չէ, քանի որ այն չի արտացոլում տվյալ բնակչության սեփականության բաշխումը (հաճախ կոչվում է պարամետր ) ըստ իր իրական բաշխման: Նշվում է, որ նման նմուշ է տեղափոխվեց դեպիհինգ խմբի անդամներ կամ հեռացել էխմբի անդամակցության մյուս բոլոր մոդելները: Նման կողմնակալ նմուշի հիման վրա մենք հակված ենք սխալ եզրակացություններ անել բնակչության վերաբերյալ:
Սա առավել հստակորեն կարող է ցուցադրվել 1930 -ականներին «Literary Digest» ամսագրին հասած աղետի օրինակով, որը ընտրությունների արդյունքների վերաբերյալ հասարակական կարծիքի հարցում էր կազմակերպել: Literary Digest- ը պարբերական էր, որում վերատպվում էին թերթերի և հասարակական կարծիքը արտացոլող այլ նյութերի խմբագրություններ. այս ամսագիրը շատ տարածված էր դարասկզբին: Սկսած 1920 թվականից ՝ ամսագիրն անցկացրեց լայնամասշտաբ համազգային հարցումներ, որոնցում փոստով քվեաթերթիկներ ուղարկվեցին ավելի քան մեկ միլիոն մարդու ՝ խնդրելով նշել, թե ում թեկնածությունն են նախընտրում առաջիկա նախագահական ընտրություններին: Տարիների ընթացքում ամսագրի հարցման արդյունքները այնքան ճշգրիտ էին, որ սեպտեմբերին անցկացված հարցումը, կարծես, քիչ նշանակություն ունեցավ նոյեմբերի ընտրություններին: Իսկ ինչպե՞ս կարող էր սխալ տեղի ունենալ նման մեծ նմուշի մեջ: Այնուամենայնիվ, 1936 թվականին դա հենց այն է, ինչ տեղի ունեցավ. Ձայների մեծամասնությամբ (60:40) հաղթանակ կանխատեսվեց հանրապետական թեկնածու Ալֆ Լենդոնի համար: Ընտրություններում Լենդոնը պարտվեց հաշմանդամի - Ֆրանկլին Դ. Ռուզվելտ - գործնականում նույն արդյունքով, որով նա պետք է հաղթեր: «Literary Digest» - ի արժանահավատությունը այնքան խաթարվեց, որ ամսագիրը կարճ ժամանակ անց դադարեցրեց հրատարակությունը: Ինչ է պատահել? Պարզապես, Digest- ի հարցումը օգտագործեց կողմնակալ ընտրանք: Բացիկներն ուղարկվել են այն մարդկանց, որոնց անունները քաղված են երկու աղբյուրներից `հեռախոսային տեղեկատուներ և մեքենաների գրանցման ցուցակներ: Եվ չնայած ընտրության այս մեթոդը շատ չէր տարբերվում նախկին մեթոդներից, իրավիճակը բոլորովին այլ էր այժմ ՝ 1936 թվականի Մեծ դեպրեսիայի ժամանակ, երբ ավելի քիչ հարուստ ընտրողները ՝ Ռուզվելտի ամենահավանական հենարանը, չէին կարող ունենալ հեռախոս ունենալու հնարավորություն, ուր մնաց մեքենան: Այսպիսով, ըստ էության, Digest- ի հարցման ժամանակ օգտագործված նմուշը կողմնակալ էր հանրապետականների նկատմամբ, և դեռ զարմանալի է, որ Ռուզվելտը նման լավ արդյունք է ունեցել:
Ինչպե՞ս կարող է լուծվել այս խնդիրը: Վերադառնալով մեր օրինակին ՝ համեմատեք Նկար 5.1 բ -ում ներկայացված նմուշը Նկար 5.1c- ի հետ: Վերջին դեպքում, վերլուծության համար ընտրվել է նաև բնակչության վեցերորդ մասը, սակայն բնակչության հիմնական տեսակներից յուրաքանչյուրը ներկայացված է ընտրանքի մեջ այն համամասնությամբ, որով այն ներկայացված է ամբողջ բնակչության մեջ: Այս ընտրանքը ցույց է տալիս, որ յուրաքանչյուր վեց մեծահասակ ամերիկացին պատկանում է մեկ քաղաքական խմբին, մեկը վեցից երկուսը և այլն: Նման նմուշառումը նաև կբացահայտի իր անդամների այլ տարբերություններ, որոնք կարող են փոխկապակցվել տարբեր խմբերի մասնակցության հետ: Այսպիսով, Նկար 5.1c- ում ցուցադրված ընտրանքը դիտարկվող բնակչության համար ներկայացուցչական նմուշ է:
Իհարկե, այս օրինակը պարզեցված է առնվազն երկու չափազանց կարևոր տեսանկյունից: Նախ, քաղաքագետներին հետաքրքրող պոպուլյացիաների մեծ մասն ավելի բազմազան են, քան ներկայացված է օրինակում: Մարդիկ, փաստաթղթեր, կառավարություններ, կազմակերպություններ, որոշումներ և այլն: միմյանցից տարբերվում են ոչ թե մեկ, այլ շատ ավելի մեծ թվով նշաններով: Այսպիսով, ներկայացուցչական նմուշը պետք է լինի այնպիսին, որ ամեն մեկըհիմնական, տարբերվող մյուս տարածքներից էր ներկայացված է համախառն իր մասնաբաժնի համամասնությամբ: Երկրորդ, այն իրավիճակը, երբ փոփոխականների կամ բնութագրերի իրական բաշխումը, որոնք մենք ցանկանում ենք չափել, նախապես հայտնի չէ, տեղի է ունենում շատ ավելի հաճախ, քան հակառակը. Գուցե դա չափված չէր նախորդ մարդահամարի ժամանակ: Այսպիսով, ներկայացուցչական նմուշը պետք է նախագծվի այնպես, որ այն կարողանա ճշգրիտ արտացոլել առկա բաշխումը նույնիսկ այն դեպքում, երբ մենք չենք կարող ուղղակիորեն գնահատել դրա վավերականությունը: Նմուշառման ընթացակարգը պետք է ունենա ներքին տրամաբանություն, որը կարող է մեզ համոզել, որ եթե մենք կարողանայինք ընտրանքը համեմատել մարդահամարի հետ, ապա այն իսկապես ներկայացուցչական կլիներ:
Որպեսզի ապահովվի, որ տվյալ բնակչության բարդ կազմակերպվածությունը կարող է ճշգրիտ արտացոլվել և որոշակի վստահություն, որ առաջարկվող ընթացակարգերը կարող են դա անել, հետազոտողները դիմում են վիճակագրական մեթոդներին: Այնուամենայնիվ, նրանք գործում են երկու ուղղությամբ. Նախ, օգտագործելով որոշակի կանոններ (ներքին տրամաբանություն), հետազոտողները որոշում են այն հարցը, թե կոնկրետ ինչ օբյեկտներ պետք է ուսումնասիրեն, ինչը կոնկրետ պետք է ներառվի կոնկրետ նմուշում: Երկրորդ, օգտագործելով շատ տարբեր կանոններ, նրանք որոշում են, թե քանի օբյեկտ ընտրել: Մենք մանրամասն չենք ուսումնասիրի այս բազմաթիվ կանոնները, մենք կդիտարկենք միայն դրանց դերը քաղաքագիտական հետազոտությունների մեջ: Սկսենք ներկայացուցչական նմուշ կազմող օբյեկտների ընտրության ռազմավարություններից: