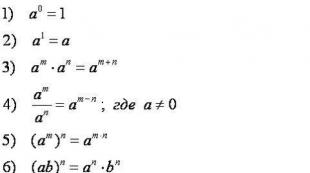विकल्प की भिन्नता रेंज। विविधता और सांख्यिकीय वितरण श्रृंखला। Wilkexon मानदंड के मूल्य की व्याख्या कैसे करें
इस प्रयोग में अध्ययन किए गए मूल्य के मूल्यों का सेट या परिमाण (आरोही या अवरोही) में अग्रेषित पैरामीटर के अवलोकन को एक विविधता संख्या कहा जाता है।
मान लीजिए हमने रक्तचाप की ऊपरी दहलीज प्राप्त करने के लिए दस रोगियों में रक्तचाप को माप लिया: सिस्टोलिक दबाव, यानी। केवल एक संख्या।
कल्पना कीजिए कि 10 टिप्पणियों में धमनी सिस्टोलिक दबाव के अवलोकन (सांख्यिकीय कुल) की एक श्रृंखला निम्नानुसार है (तालिका 1):
तालिका एक
विविधता संख्या के घटकों को विकल्प कहा जाता है। विकल्प अध्ययन चिह्न का एक संख्यात्मक मान हैं।
भिन्नता श्रृंखला के सांख्यिकीय कुल अवलोकन से निर्माण - पूरी आबादी की विशेषताओं की समझ के लिए केवल पहला कदम। इसके बाद, परिणामी मात्रात्मक सुविधा (रक्त प्रोटीन का औसत स्तर, रोगियों का औसत वजन, संज्ञाहरण की घटना का औसत समय, आदि) के औसत स्तर को निर्धारित करना आवश्यक है।
औसत स्तर मानदंडों का उपयोग करके मापा जाता है जिसे औसत मान कहा जाता है। औसत मूल्य गुणात्मक रूप से सजातीय मूल्यों की सामान्यीकृत संख्यात्मक विशेषता है, जो एक आधार पर पूरे सांख्यिकीय सेट की एक संख्या में दर्शाता है। औसत मूल्य सामान्य रूप से व्यक्त किया जाता है, जो अवलोकनों के इस सेट में एक संकेत की विशेषता है।
तीन प्रकार के औसत मान आमतौर पर उपयोग किए जाते हैं: फैशन (), औसत () और मध्यम-टैरिफ मान ()।
किसी भी औसत को निर्धारित करने के लिए, व्यक्तिगत अवलोकनों के परिणामों का उपयोग करना आवश्यक है, उन्हें भिन्नता श्रृंखला (तालिका 2) के रूप में लिखना आवश्यक है।
फैशन - अवलोकनों की एक श्रृंखला में सबसे आम मूल्य। फैशन \u003d 120 के हमारे उदाहरण में। यदि विविधता श्रृंखला में कोई दोहराए गए मूल्य नहीं हैं, तो वे कहते हैं कि कोई मोड नहीं है। यदि कई मानों को समान संख्या में दोहराया जाता है, तो उनमें से सबसे छोटा फैशन के रूप में लेता है।
मंझला - वितरण को दो बराबर भागों में विभाजित करना, अवलोकनों की एक श्रृंखला के केंद्रीय या औसत मूल्य, आरोही या अवरोही द्वारा आदेश दिया गया। इसलिए, यदि मानों में से 5 की भिन्नता श्रृंखला में, तो इसका औसत भिन्नता श्रृंखला के तीसरे सदस्य के बराबर है, यदि लगातार सदस्यों की संख्या भी है, तो मध्ययुगीन अपने दो केंद्रीय अवलोकनों का अंकगणितीय औसत है, अर्थात यदि 10 टिप्पणियां हैं, तो औसत औसत अंकगणितीय 5 और 6 टिप्पणियों के बराबर है। हमारे उदाहरण में।
हम फैशन और मध्य विशेषज्ञों की एक महत्वपूर्ण विशेषता पर ध्यान देते हैं: चरम विकल्प के संख्यात्मक मान उनके मूल्यों को प्रभावित नहीं करते हैं।
मध्य अंकगणितीय मूल्य सूत्र द्वारा गणना:
कहां - अवलोकन का मनाया गया मूल्य, और अवलोकनों की संख्या। हमारे मामले के लिए।
औसत अंकगणितीय मूल्य में तीन गुण होते हैं:
औसत श्रृंखला में औसत एक मध्य स्थिति है। एक सख्ती से सममित पंक्ति में।
औसत एक सामान्यीकरण परिमाण है और औसत के लिए यादृच्छिक उतार-चढ़ाव, व्यक्तिगत डेटा में मतभेदों द्वारा दिखाई नहीं दे रहे हैं। यह उस विशिष्टता को दर्शाता है, जो पूरी कुटिलता के लिए विशिष्ट है।
औसत से सभी विकल्प के विचलन की मात्रा शून्य है :. माध्यम से विचलन विकल्प संकेत दिया जाता है।
विविधता श्रृंखला में एक विकल्प और संबंधित आवृत्तियों शामिल हैं। अंक 120 के दस मूल्यों में से 6 गुना, 115 - 3 गुना, 125 - 1 बार मिले। आवृत्ति () कुल मिलाकर व्यक्तिगत विकल्प की पूर्ण संख्या है, यह दर्शाती है कि भिन्नता श्रृंखला में यह विकल्प कितनी बार पाया जाता है।
विविधता श्रृंखला सरल (आवृत्ति \u003d 1) या संक्षिप्त लघु, 3-5 विकल्प हो सकती है। एक साधारण श्रृंखला का उपयोग छोटी संख्या के अवलोकन (), समूह के साथ किया जाता है - बड़ी संख्या में अवलोकन ()।
सांख्यिकीय विश्लेषण में एक विशेष स्थान अध्ययन चिह्न या घटना के औसत स्तर की परिभाषा से संबंधित है। औसत विशेषता स्तर औसत मूल्यों द्वारा मापा जाता है।
औसत मूल्य अध्ययन के तहत विशेषता के समग्र मात्रात्मक स्तर की विशेषता है और एक सांख्यिकीय समुच्चय की एक समूह संपत्ति है। यह स्तर, एक या दूसरे तरीके से व्यक्तिगत अवलोकनों के यादृच्छिक विचलन को कमजोर करता है और अध्ययन चिह्न की मुख्य, विशिष्ट संपत्ति को हाइलाइट करता है।
औसत चर का व्यापक रूप से उपयोग किया जाता है:
1. जनसंख्या के स्वास्थ्य की स्थिति का आकलन करने के लिए: शारीरिक विकास (विकास, वजन, छाती परिधि, आदि) की विशेषताएं, विभिन्न बीमारियों की प्रसार और अवधि का पता लगाने, जनसांख्यिकीय संकेतकों का विश्लेषण (जनसंख्या का प्राकृतिक आंदोलन, औसत) आगामी जीवन की अवधि, जनसंख्या प्रजनन, औसत आबादी और आदि)।
2. चिकित्सा और प्रोफाइलैक्टिक संस्थानों, चिकित्सा कर्मियों की गतिविधियों का अध्ययन करने और उनके काम की गुणवत्ता का आकलन करने, विभिन्न प्रकार की चिकित्सा देखभाल में आबादी की जरूरतों की योजना बनाने और निर्धारित करने के लिए (प्रति वर्ष प्रति निवासी अपील या यात्राओं की औसत संख्या, अस्पताल में रोगी के ठहरने की औसत अवधि, रोगी के सर्वेक्षण की औसत अवधि, डॉक्टरों, धनुष, आदि की औसत सुरक्षा)।
3. स्वच्छता और महामारी विज्ञान की स्थिति को चिह्नित करने के लिए (कार्यशाला में हवा की औसत धूल, प्रति व्यक्ति औसत क्षेत्र, प्रोटीन की खपत के औसत मानदंड, वसा और कार्बोहाइड्रेट इत्यादि)।
4. सामाजिक-स्वच्छता, नैदानिक, प्रयोगात्मक अध्ययनों में नमूना अध्ययन के परिणामों की विश्वसनीयता स्थापित करने के लिए, प्रयोगशाला डेटा की प्रसंस्करण के दौरान, सामान्य रूप से और शारीरिक संकेतक, सामान्य रूप से और शारीरिक संकेतक निर्धारित करने के लिए।
औसत मूल्यों की गणना भिन्नता श्रृंखला पर आधारित है। विविधता श्रृंखला - यह गुणात्मक संबंध में एक सजातीय सांख्यिकीय सेट है, जिनमें से कुछ इकाइयां अध्ययन की विशेषता या घटना में मात्रात्मक मतभेदों को दर्शाती हैं।
मात्रात्मक भिन्नता दो प्रकार हो सकती है: एक समाप्त (असतत) और निरंतर।
एक असंतुलित (असतत) सुविधा केवल पूर्णांक द्वारा व्यक्त की जाती है और इसमें कोई मध्यवर्ती मूल्य नहीं हो सकता है (उदाहरण के लिए, यात्राओं की संख्या, जनसंख्या आबादी, परिवार में बच्चों की संख्या, अंक की गंभीरता, आदि आदि ।)।
एक निरंतर संकेत भिन्नता सहित कुछ सीमाओं के भीतर किसी भी मूल्य ले सकता है, और केवल लगभग व्यक्त किया जाता है (उदाहरण के लिए, वजन - वयस्कों के लिए किलोग्राम तक सीमित हो सकता है, और नवजात शिशुओं के लिए - ग्राम; विकास, रक्तचाप, समय पर खर्च किया गया रोगी का स्वागत, आदि)।
भिन्नता सीमा में शामिल प्रत्येक व्यक्तिगत सुविधा या घटना का डिजिटल मान को विकल्प कहा जाता है और पत्र द्वारा संकेत दिया जाता है वी । गणितीय साहित्य में अन्य पदनाम भी हैं, उदाहरण के लिए एक्स। या वाई
एक भिन्नता सीमा, जहां प्रत्येक विकल्प एक बार निर्दिष्ट किया जाता है, को सरल कहा जाता है। कंप्यूटर डेटा प्रोसेसिंग के मामले में ऐसी पंक्तियों का उपयोग अधिकांश सांख्यिकीय कार्यों में किया जाता है।
एक नियम के रूप में अवलोकनों की संख्या में वृद्धि के साथ, दोहराव मूल्य विकल्प विकल्प हैं। इस मामले में बनाया गया है समूहित विविधताएंजहां पुनरावृत्ति की संख्या इंगित की जाती है (आवृत्ति पत्र द्वारा इंगित की जाती है " आर »).
प्रतिदिन विविधताएं इसमें आरोही क्रम या अवरोही में व्यवस्थित एक विकल्प शामिल है। दोनों सरल और समूहीकृत पंक्तियों को रैंकिंग के साथ संकलित किया जा सकता है।
अंतराल विविधता श्रृंखला एक कंप्यूटर के उपयोग के बिना किए गए बाद की गणना को सरल बनाने के लिए, बहुत बड़ी संख्या में अवलोकन इकाइयों (1000 से अधिक) के साथ।
निरंतर विविधता श्रृंखला उस विकल्प के मान शामिल हैं जिन्हें किसी भी मान द्वारा व्यक्त किया जा सकता है।
यदि भिन्नता श्रृंखला में विशेषता (विकल्प) के मान व्यक्तिगत विशिष्ट संख्याओं के रूप में दिए जाते हैं, तो ऐसा नंबर कहा जाता है अलग.
सामान्य लक्षण भिन्नता श्रृंखला में दिखाई देने वाले संकेत औसत मूल्य हैं। उनमें से सबसे अधिक उपयोग किया जाता है: औसत अंकगणितीय मूल्य म,फैशन एमओऔर मेडियाना मैं।इनमें से प्रत्येक विशेषता मूल रूप से है। वे एक दूसरे को प्रतिस्थापित नहीं कर सकते हैं और केवल कुल पूरी तरह से और संपीड़ित रूप में भिन्नता श्रृंखला की विशेषताएं हैं।
मॉडय (मो) सबसे आम विकल्पों के मूल्य को कॉल करें।
मंझला (मुझे) - यह रैंकिंग विविधताओं को आधे में विभाजित करने वाले विकल्पों का मूल्य है (मध्ययुगीन के प्रत्येक पक्ष पर आधा विकल्प है)। दुर्लभ मामलों में, जब एक सममित भिन्नता श्रृंखला होती है, तो एक मॉड और औसत एक दूसरे के बराबर होते हैं और औसत अंकगणित के मूल्य के साथ मेल खाते हैं।
मूल्यों की सबसे विशिष्ट विशेषता विकल्प है मध्य अंकगणित मात्रा ( म। )। गणितीय साहित्य में, यह संकेत दिया जाता है .
मध्य अंकगणितीय मूल्य (म, ) - यह एक गुणात्मक सजातीय सांख्यिकीय कुल मिलाकर अध्ययन की गई घटनाओं के एक निश्चित संकेत की कुल मात्रात्मक विशेषता है। औसत अंकगणित सरल और भारित के बीच अंतर करें। औसत अंकगणित सरल है कि इस भिन्नता सीमा में शामिल विकल्पों की कुल संख्या के लिए इस राशि को विभाजित करके और इस राशि को विभाजित करके सरल भिन्नता श्रृंखला के लिए गणना की जाती है। गणना सूत्र द्वारा की जाती है:
कहा पे: म। - औसत अंकगणितीय सरल;
Σ वी - राशि विकल्प;
एन - अवलोकनों की संख्या।
एक समूहित भिन्नता श्रृंखला में, एक भारित औसत अंकगणित निर्धारित किया जाता है। इसकी गणना का सूत्र:
कहा पे: म। - औसत अंकगणित भार;
Σ वी.पी. - उनकी आवृत्ति पर उत्पादों के विकल्प की मात्रा;
एन - अवलोकनों की संख्या।
मैन्युअल गणना के मामले में बड़ी संख्या में टिप्पणियों के साथ, क्षणों की विधि लागू की जा सकती है।
औसत अंकगणित में निम्नलिखित गुण होते हैं:
औसत से विचलन विकल्प की मात्रा ( Σ डी ) शून्य के बराबर (तालिका 15 देखें);
· एक ही कारक (विभाजक) पर सभी विकल्पों के गुणा (विभाजन) पर, औसत अंकगणित एक ही कारक (विभाजक) को गुणा (विभाजित) गुणा किया जाता है;
· यदि आप सभी प्रकारों को जोड़ते हैं (वही संख्या, एक ही संख्या में औसत अंकगणितीय वृद्धि (घटती है)।
श्रृंखला की विविधता को ध्यान में रखे बिना, औसत अंकगणितीय मान, जिनमें से इसकी गणना की जाती है, वे भिन्नता श्रृंखला के गुणों को पूरी तरह से प्रतिबिंबित नहीं कर सकते हैं, खासकर जब अन्य माध्यमों की तुलना की आवश्यकता होती है। सही माध्यम को एक पंक्ति से बिखरने की विभिन्न डिग्री के साथ प्राप्त किया जा सकता है। एक दूसरे के करीब उनके मात्रात्मक विशेषता में कुछ विकल्प, कम बिखरने (परिवर्तनशीलता, परिवर्तनशीलता) एक संख्या, इसके औसत के अधिक विशिष्ट।
मुख्य पैरामीटर जो सुविधा की विविधता का मूल्यांकन करने की अनुमति देते हैं:
· दायरा;
आयाम;
औसत वर्गिक विचलन;
भिन्नता का गुणांक।
लगभग संकेत के वर्गों के बारे में भिन्नता श्रृंखला के दायरे और आयाम से निर्णय लिया जा सकता है। स्कोप पंक्ति में अधिकतम (v अधिकतम) और न्यूनतम (v min) विकल्प इंगित करता है। आयाम (एक एम) इन विकल्पों का अंतर है: एक एम \u003d वी अधिकतम - वी मिन।
मुख्य, आम तौर पर भिन्नता सीमा भिन्नताओं का स्वीकार्य उपाय है फैलाव (डी )। लेकिन सबसे अधिक उपयोग किए जाने वाले अधिक सुविधाजनक पैरामीटर, फैलाव के आधार पर गणना - औसत वर्गिक विचलन ( σ )। यह विचलन की परिमाण को ध्यान में रखता है ( डी ) अपने मध्य अंकगणित से भिन्नता सीमा के प्रत्येक प्रकार ( डी \u003d वी - एम ).
चूंकि औसत से विचलन विकल्प सकारात्मक और नकारात्मक हो सकता है, फिर सारांशित करते समय, वे मूल्य "0" देते हैं डी \u003d 0।)। इससे बचने के लिए, विचलन मूल्य ( डी) दूसरी डिग्री में जल्दी और औसत हैं। इस प्रकार, विविधता श्रृंखला का फैलाव मध्य अंकगणित से विचलन विकल्प का औसत वर्ग है और सूत्र द्वारा गणना की जाती है:
यह परिवर्तनशीलता की सबसे महत्वपूर्ण विशेषता है और इसका उपयोग कई सांख्यिकीय मानदंडों की गणना करने के लिए किया जाता है।
चूंकि फैलाव विचलन के वर्ग द्वारा व्यक्त किया जाता है, इसलिए इसका मूल्य औसत अंकगणित की तुलना में नहीं किया जा सकता है। इन उद्देश्यों के लिए लागू होता है औसत वर्गिक विचलनजिसे "सिग्मा" साइन द्वारा इंगित किया गया है ( σ )। यह मध्य अंकगणितीय मूल्य से एक ही इकाइयों में मध्य मूल्य के रूप में सभी भिन्नता भिन्नता के औसत विचलन को चिह्नित करता है, इसलिए उन्हें एक साथ उपयोग किया जा सकता है।
औसत वर्गबद्ध विचलन सूत्र द्वारा निर्धारित किया जाता है:
यह सूत्र अवलोकनों की संख्या के साथ लागू होता है ( एन ) 30 से अधिक। एक छोटी संख्या के साथ एन औसत वर्गिक विचलन मूल्य में गणितीय विस्थापन से जुड़ी त्रुटि होगी ( एन - एक)। इस संबंध में, मानक विचलन की गणना के लिए सूत्र में इस तरह के विस्थापन को ध्यान में रखते हुए एक और सटीक परिणाम प्राप्त किया जा सकता है:
मानक विचलन (एस ) - यह एक यादृच्छिक चर के रिकंडक्टिक विचलन का मूल्यांकन है एच इसके फैलाव के अविश्वसनीय अनुमान के आधार पर इसकी गणितीय उम्मीद के संबंध में।
मूल्यों पर एन \u003e 30 औसत वर्गिक विचलन ( σ ) और मानक विचलन ( एस ) एक ही हो जाएगा ( Σ \u003d एस। ). इसलिए, सबसे व्यावहारिक लाभों में, इन मानदंडों को विविध माना जाता है। एक्सेल प्रोग्राम में, मानक विचलन गणना फ़ंक्शन \u003d स्टैंडऑट क्लोन (रेंज) द्वारा की जा सकती है। और औसत वर्गबद्ध विचलन की गणना करने के लिए, एक उपयुक्त सूत्र बनाने के लिए आवश्यक है।
औसत वर्गबद्ध या मानक विचलन आपको यह निर्धारित करने की अनुमति देता है कि चरित्र मूल्य औसत मूल्य से भिन्न हो सकते हैं। मान लीजिए गर्मियों में एक ही औसत दिन के तापमान वाले दो शहर हैं। इन शहरों में से एक तट पर स्थित है, और दूसरा महाद्वीप पर है। यह ज्ञात है कि तट पर स्थित शहरों में, दिन के तापमान में मतभेद महाद्वीप के अंदर स्थित शहरों से छोटे होते हैं। इसलिए, तटीय शहर में दिन के तापमान का औसत वर्गबद्ध विचलन दूसरे शहर से कम होगा। अभ्यास में, इसका मतलब है कि महाद्वीप पर स्थित शहर में प्रत्येक विशेष दिन का औसत हवा का तापमान तट पर शहर की तुलना में औसत मूल्य से कठिन होगा। इसके अलावा, मानक विचलन आपको संभावना के आवश्यक स्तर के साथ औसत तापमान विचलन का अनुमान लगाने की अनुमति देता है।
संभावना के सिद्धांत के अनुसार, सामान्य वितरण कानून में प्रस्तुत घटना में, औसत अंकगणितीय, औसत वर्गिक विचलन के मूल्यों के बीच और विकल्पों में एक सख्त निर्भरता है ( नियम तीन सिग्म)। उदाहरण के लिए, भिन्नता सुविधा के 68.3% मान एम ± 1 के भीतर हैं σ , 95.5% - एम ± 2 के भीतर σ और 99.7% - एम ± 3 के भीतर σ .
औसत वर्गबद्ध विचलन की परिमाण भिन्नता श्रृंखला और अध्ययन समूह की एकरूपता की प्रकृति का न्याय करने की अनुमति देता है। यदि औसत वर्गबद्ध विचलन की परिमाण छोटी है, तो यह अध्ययन के तहत घटना की पर्याप्त उच्च समानता को इंगित करता है। इस मामले में औसत अंकगणित को इस भिन्नता श्रृंखला की काफी विशेषता के रूप में पहचाना जाना चाहिए। हालांकि, बहुत छोटा सिग्मा अवलोकनों के कृत्रिम चयन के बारे में सोचता है। एक बहुत बड़ी सिग्मा के साथ, एक कम हद तक औसत अंकगणित भिन्नता श्रृंखला की विशेषता है, जो अध्ययन के तहत अध्ययन किए गए चरित्र या घटना या समूह की विषमता की एक महत्वपूर्ण परिवर्तनशीलता को इंगित करता है। हालांकि, औसत वर्गबद्ध विचलन की परिमाण की तुलना केवल उसी आयाम के संकेतों के लिए संभव है। दरअसल, यदि आप नवजात बच्चों और वयस्कों के वजन की विविधता की तुलना करते हैं, तो हम हमेशा वयस्कों में उच्च सिग्मा मूल्य प्राप्त करते हैं।
विभिन्न आयामों के लक्षणों की विविधता की तुलना का उपयोग करके किया जा सकता है गुणांक भिन्नता। यह औसत मूल्य के प्रतिशत के रूप में एक किस्म व्यक्त करता है, जो विभिन्न संकेतों की तुलना की अनुमति देता है। चिकित्सा साहित्य में भिन्नता का गुणांक संकेत द्वारा इंगित किया गया है " से ", और गणितीय" वी"और सूत्र द्वारा गणना की:
10% से कम के भिन्नता गुणांक के मान 10 से 20% तक एक छोटे से बिखरने का संकेत देते हैं - औसतन 20% से अधिक - मध्य अंकगणित के आसपास के विकल्प को मजबूत बिखरने के बारे में।
औसत अंकगणितीय मान आमतौर पर डेटा के चयनात्मक सेट के आधार पर गणना की जाती है। बार-बार अध्ययन के साथ, यादृच्छिक घटनाओं के प्रभाव में, औसत अंकगणित बदल सकते हैं। यह इस तथ्य के कारण है कि इसकी जांच की जाती है, एक नियम के रूप में, अवलोकन की संभावित इकाइयों का केवल एक हिस्सा, यह एक चुनिंदा कुल है। अध्ययन की गई घटनाओं का प्रतिनिधित्व करने वाली सभी संभावित इकाइयों के बारे में जानकारी पूरी सामान्य जनसंख्या का अध्ययन करते समय प्राप्त की जा सकती है, जो हमेशा संभव नहीं होती है। साथ ही, प्रयोगात्मक डेटा को सामान्य करने के उद्देश्य से, सामान्य जनसंख्या में औसत का मूल्य ब्याज की है। इसलिए, अध्ययन की घटना के बारे में सामान्य निष्कर्ष के निर्माण के लिए, चुनिंदा कुल के आधार पर प्राप्त परिणामों को सांख्यिकीय तरीकों के सामान्य सेट में स्थानांतरित किया जाना चाहिए।
नमूना अध्ययन और सामान्य आबादी के संयोग की डिग्री निर्धारित करने के लिए, त्रुटि की परिमाण का आकलन करना आवश्यक है, जो विशिष्ट रूप से चुनिंदा अवलोकन के दौरान होता है। इस त्रुटि को " प्रतिनिधि त्रुटि"या" मध्य अंकगणितीय त्रुटि "। यह वास्तव में नमूने में प्राप्त औसत के बीच एक अंतर है सांख्यिकीय अवलोकन, और समान मान जो एक ही वस्तु के निरंतर अध्ययन के साथ प्राप्त किए जाएंगे, यानी सामान्य जनसंख्या का अध्ययन करते समय। चूंकि चुनिंदा औसत एक यादृच्छिक मूल्य है, इस तरह का पूर्वानुमान शोधकर्ता के लिए एक स्वीकार्य संभावना के साथ किया जाता है। चिकित्सा अध्ययन में, यह कम से कम 95% है।
प्रतिनिधि त्रुटि को संदर्भ त्रुटियों या ध्यान की त्रुटियों (आदि) के साथ मिश्रित नहीं किया जा सकता है, जिसे प्रयोग में उपयोग की जाने वाली पर्याप्त तकनीकों और उपकरणों द्वारा कम से कम किया जाना चाहिए।
प्रतिनिधित्व की त्रुटि की परिमाण नमूना आकार और नमूना परिवर्तनशीलता दोनों पर निर्भर करती है। अवलोकनों की संख्या जितनी अधिक होगी, सामान्य जनसंख्या की ओर नमूना और कम त्रुटि। अधिक बदलते संकेत, सांख्यिकीय त्रुटि का मूल्य जितना अधिक होगा।
अभ्यास में, भिन्नता श्रृंखला में प्रतिनिधित्व की त्रुटि निर्धारित करने के लिए निम्नलिखित सूत्र का उपयोग करता है:
कहा पे: म। - प्रतिनिधि त्रुटि;
σ - द्वितीयक द्विघात विचलन;
एन - नमूना में अवलोकनों की संख्या।
सूत्र से, यह देखा जा सकता है कि औसत त्रुटि का आकार औसत वर्गिक विचलन के लिए सीधे आनुपातिक है, यानी अध्ययन की विशेषता की विविधता, और अवलोकन की संख्या से वर्ग की जड़ के विपरीत आनुपातिक।
सापेक्ष मूल्यों की गणना के आधार पर सांख्यिकीय विश्लेषण करते समय, एक भिन्नता संख्या का निर्माण अनिवार्य नहीं है। साथ ही, सापेक्ष संकेतकों के लिए औसत त्रुटि की परिभाषा को सरलीकृत सूत्र पर किया जा सकता है:
कहा पे: आर- सापेक्ष संकेतक की परिमाण, प्रतिशत, पीपीएम, आदि में व्यक्त किया गया;
प्र - राशि, उलटा पी और (1-पी), (100-पी), (1000-पी), आदि के रूप में व्यक्त किया गया, जिस आधार पर संकेतक की गणना की जाती है;
एन - चुनिंदा कुल में अवलोकनों की संख्या।
हालांकि, सापेक्ष मूल्यों के लिए प्रतिनिधित्व की त्रुटि की गणना के लिए निर्दिष्ट सूत्र का उपयोग केवल मामले में किया जा सकता है जब संकेतक का मूल्य इसके आधार से कम होता है। कुछ मामलों में, गहन संकेतकों की गणना इस तरह की स्थिति से पालन नहीं किया जाता है, और सूचक 100% से अधिक या 1000% की संख्या से व्यक्त किया जा सकता है। ऐसी स्थिति में, एक संयोजन श्रृंखला है और मध्य द्विघात विचलन के आधार पर औसत मूल्यों के लिए सूत्र द्वारा प्रतिनिधि त्रुटि की गणना करता है।
सामान्य आबादी में औसत अंकगणित के मूल्य की भविष्यवाणी दो मानों के संकेत के साथ किया जाता है - न्यूनतम और अधिकतम। संभावित विचलन के ये चरम मूल्य, जिसके भीतर सामान्य आबादी का वांछित औसत मूल्य उतार-चढ़ाव कर सकता है, को "कहा जाता है" ट्रस्ट सीमाएं».
संभाव्यता सिद्धांत के अनुवाद साबित हुए हैं कि 99.7% की संभावना के साथ सुविधा के सामान्य वितरण में, औसत विचलन के चरम मूल्य तीन गुना प्रतिनिधित्वशीलता त्रुटि की परिमाण से अधिक नहीं होंगे ( म। ± 3। म। ); 95.5% - औसत मूल्य की दोहरी औसत त्रुटि के मूल्य से अधिक नहीं ( म। ± 2। म। ); 68.3% - एक औसत त्रुटि की राशि से अधिक नहीं ( म। ± 1। म। ) (चित्र 9)।
| पी% |
अंजीर। 9. सामान्य वितरण की संभावना की घनत्व।
ध्यान दें कि उपर्युक्त कथन केवल एक ऐसी सुविधा के लिए है जो गॉस वितरण के सामान्य कानून के अधीन है।
दवा के क्षेत्र में सबसे प्रयोगात्मक अध्ययन, माप से जुड़े होते हैं जिनके परिणाम दिए गए अंतराल पर लगभग किसी भी मूल्य ले सकते हैं, इसलिए, एक नियम के रूप में, निरंतर यादृच्छिक चर का एक मॉडल वर्णित है। इस संबंध में, अधिकांश सांख्यिकीय तरीकों में, निरंतर वितरण पर विचार किया जाता है। एक ऐसा वितरण जिसमें गणितीय आंकड़ों में मौलिक भूमिका है सामान्य, या गाऊसी, वितरण.
यह कई कारणों से समझाया गया है।
1. सबसे पहले, सामान्य वितरण का उपयोग करके कई प्रयोगात्मक अवलोकनों का सफलतापूर्वक वर्णित किया जा सकता है। यह तुरंत ध्यान दिया जाना चाहिए कि अनुभवजन्य डेटा का कोई आवंटन वितरण नहीं है जो सामान्य के साथ ठीक होगा, क्योंकि आमतौर पर वितरित यादृच्छिक मूल्य उस से लेकर होता है, जो कभी भी अभ्यास में नहीं पाया जाता है। हालांकि, सामान्य वितरण अक्सर अनुमान के रूप में उपयुक्त होता है।
चाहे मानव शरीर के वजन, विकास और अन्य शारीरिक मानकों के माप किए जाते हैं - हर जगह परिणामों में बहुत बड़ी संख्या में यादृच्छिक कारकों (प्राकृतिक कारणों और माप त्रुटियों) का असर पड़ता है। इसके अलावा, एक नियम के रूप में, इन कारकों में से प्रत्येक की कार्रवाई महत्वहीन है। अनुभव से पता चलता है कि ऐसे मामलों में परिणाम लगभग सामान्य वितरित किए जाएंगे।
2. बाद में वृद्धि के साथ एक यादृच्छिक नमूने से जुड़े कई वितरण, सामान्य पर जाते हैं।
3. सामान्य वितरण अन्य निरंतर वितरण के अनुमानित विवरण के रूप में उपयुक्त है (उदाहरण के लिए, असममित)।
4. सामान्य वितरण में कई अनुकूल गणितीय गुण होते हैं, कई मामलों में आंकड़ों में व्यापक उपयोग प्रदान करते हैं।
साथ ही, यह ध्यान दिया जाना चाहिए कि चिकित्सा डेटा में कई प्रयोगात्मक वितरण हैं, जिसका विवरण सामान्य वितरण का मॉडल असंभव है। ऐसा करने के लिए, आंकड़ों में विकसित विधियां जिन्हें "गैर-पैरामीट्रिक" कहा जाता है।
एक सांख्यिकीय विधि की पसंद जो किसी विशिष्ट प्रयोग के डेटा को संसाधित करने के लिए उपयुक्त है, सामान्य वितरण कानून में डेटा के संबंधित के आधार पर किया जाना चाहिए। सामान्य वितरण कानून द्वारा एक संकेत जमा करने पर परिकल्पना की जांच आवृत्ति वितरण हिस्टोग्राम (ग्राफ) के साथ-साथ कई सांख्यिकीय मानदंडों का उपयोग करके किया जाता है। उनमें से:
असममितता मानदंड ( बी );
एक्ससाइड चेक मानदंड ( जी );
मानदंड shapiro - Wilx ( डब्ल्यू ) .
डेटा के वितरण की प्रकृति का विश्लेषण (इसे वितरण की वैधता भी कहा जाता है) प्रत्येक पैरामीटर के लिए किया जाता है। सामान्य कानून द्वारा पैरामीटर के वितरण के अनुपालन का आत्मविश्वास से न्याय करने के लिए, पर्याप्त रूप से बड़ी संख्या में अवलोकन इकाइयों की आवश्यकता होती है (कम से कम 30 मान)।
सामान्य वितरण के लिए, विषमता और अतिरिक्तता के मानदंड 0. का मान लेते हैं। यदि वितरण दाईं ओर स्थानांतरित हो जाता है बी \u003e 0 (सकारात्मक विषमता), के साथ बी < 0 - график распределения смещен влево (отрицательная асимметрия). Критерий асимметрии проверяет форму кривой распределения. В случае нормального закона जी \u003d 0। के लिये जी \u003e 0 तेज वितरण वक्र अगर जी < 0 пик более сглаженный, чем функция нормального распределения.
Shapiro - Wilx के मानदंड द्वारा सामान्यता की जांच करने के लिए, इसे महत्वपूर्ण स्तर के महत्व के साथ सांख्यिकीय तालिकाओं पर इस मानदंड का अर्थ ढूंढना आवश्यक है और अवलोकन इकाइयों (स्वतंत्रता की डिग्री) की संख्या के आधार पर। अनुलग्नक 1. एक नियम के रूप में, इस मानदंड के छोटे मूल्यों पर सामान्यता की परिकल्पना को खारिज कर दिया जाता है, डब्ल्यू <0,8.
किसी भी सामान्य विशेषता या उच्च गुणवत्ता वाले या मात्रात्मक प्रकृति की संपत्ति द्वारा संयुक्त वस्तुओं या घटनाओं का संयोजन कहा जाता है वस्तु अवलोकन .
सांख्यिकीय अवलोकन की किसी भी वस्तु में व्यक्तिगत तत्व होते हैं - इकाइयों अवलोकन .
सांख्यिकीय अवलोकन के परिणाम संख्यात्मक जानकारी हैं - डेटा . सांख्यिकीय डेटा - यह एक सांख्यिकीय कुल में शोधकर्ता में अनुसंधान में रुचि रखने वाले मूल्यों के बारे में जानकारी है।
यदि चरित्र मान संख्याओं द्वारा व्यक्त किए जाते हैं, तो संकेत कहा जाता है मात्रात्मक .
यदि सुविधा कुल तत्वों की कुछ संपत्ति या स्थिति की विशेषता है, तो संकेत कहा जाता है गुणात्मक .
यदि अध्ययन कुल (ठोस अवलोकन) के सभी तत्वों के अधीन है, तो सांख्यिकीय समुच्चय को कहा जाता है सामान्य।
यदि कोई अध्ययन सामान्य आबादी के तत्वों के एक हिस्से के अधीन है, तो सांख्यिकीय समुच्चय को कहा जाता है चुनिंदा (नमूनाकरण) । सामान्य आबादी से चयन यादृच्छिक रूप से निकाला जाता है, ताकि प्रत्येक नमूना तत्वों में चयनित होने की समान संभावनाएं हों।
सेट के एक तत्व से दूसरे तत्व में संक्रमण के दौरान विशेषता के मान बदल दिए जाते हैं (भिन्न), इसलिए, आंकड़ों में, विभिन्न संकेत भी कहा जाता है विकल्प । विकल्प आमतौर पर छोटे लैटिन अक्षरों एक्स, वाई, जेड द्वारा इंगित किए जाते हैं।
विकल्प (साइन वैल्यू) की अनुक्रम संख्या कहा जाता है पद । एक्स 1 - 1 अवतार (पहला संकेत), एक्स 2 - दूसरा विकल्प (दूसरा साइन वैल्यू), एक्स I - आई-वें संस्करण (आई-ई साइन)।
उन शब्दों के साथ कई संकेतों (विकल्प) को बढ़ाने या घटाने के क्रम में आदेश दिया गया है जिसे उन्हें कहा जाता है पासल (पास के वितरण) के पास।
जैसा वजन का होता है आवृत्ति या आवृत्ति।
आवृत्ति(एम I) दिखाता है कि एक सांख्यिकीय कुल में एक या दूसरे (साइन वैल्यू) कितनी बार सामना किया जाता है।
आवृत्ति या सापेक्ष आवृत्ति (डब्ल्यू मैं) दर्शाता है कि संयोजन इकाइयों का कौन सा हिस्सा एक या दूसरा है। आवृत्ति की गणना पंक्ति की सभी आवृत्तियों के योग के लिए एक या किसी अन्य विकल्प की आवृत्ति के अनुपात के रूप में की जाती है।
. (6.1)
सभी आवृत्तियों का योग 1 के बराबर है।
. (6.2)
भिन्नता पंक्तियां अलग और अंतराल हैं।
असतत विविधता पंक्तियाँ आम तौर पर इस घटना में निर्माण करते हैं कि अध्ययन चिह्न के मान एक दूसरे से अलग-अलग मूल्य से कम नहीं हो सकते हैं।
असतत विविधता पंक्तियों में, बिंदु मान सेट हैं।
टेबल 6.1 में अलग विविधता संख्या का सामान्य दृश्य निर्दिष्ट किया गया है।
तालिका 6.1।
जहां i \u003d 1, 2, ..., एल
प्रत्येक अंतराल में अंतराल भिन्नता पंक्तियों में, अंतराल की ऊपरी और निचली सीमाओं को प्रतिष्ठित किया जाता है।
अंतराल की ऊपरी और निचली सीमाओं के बीच का अंतर कहा जाता है अंतराल अंतर या लंबाई (मूल्य) अंतराल .
पहले अंतराल के 1 की परिमाण सूत्र द्वारा निर्धारित किया जाता है:
k 1 \u003d। एक 2 - ए 1;
दूसरा: के 2 \u003d और 3 - एक 2; ...
अंतिम: के एल \u003d एक एल - ए एल -1।
सामान्य रूप में अंतराल अंतर K की गणना सूत्र द्वारा गणना की जाती है:
के i \u003d x i (अधिकतम) - x i (min)। (6.3)
यदि अंतराल में दोनों सीमाएं होती हैं, तो इसे बुलाया जाता है बंद किया हुआ .
पहला और अंतिम अंतराल हो सकता है खुला हुआ । केवल एक सीमा है।
उदाहरण के लिए, पहले अंतराल को "100 तक", दूसरा - "100-110", ..., अंतिम - "1 9 0-200", अंतिम - "200 और अधिक" के रूप में सेट किया जा सकता है। जाहिर है, पहले अंतराल में निचली सीमा नहीं है, और अंतिम शीर्ष, दोनों खुले हैं।
अक्सर खुले अंतराल को पवित्र करना पड़ता है। इस उद्देश्य के लिए, पहला अंतराल आमतौर पर दूसरे के मूल्य के बराबर होता है, और आखिरी व्यक्ति की परिमाण स्थायी की परिमाण होती है। हमारे उदाहरण में, दूसरे अंतराल की परिमाण 110-100 \u003d 10 है, इसलिए, पहले अंतराल की निचली सीमा सशर्त रूप से 100-10 \u003d 9 0 है; अंतिम अंतराल की परिमाण 200-190 \u003d 10 है, इसलिए, अंतिम अंतराल की ऊपरी सीमा 200 + 10 \u003d 210 में सशर्त है।
इसके अलावा, अंतराल भिन्नता समूहों को विभिन्न लंबाई के अंतराल का सामना करना पड़ सकता है। यदि भिन्नता सीमा में अंतराल की लंबाई (अंतराल अंतर) होती है, तो उन्हें बुलाया जाता है सममितीय , अन्यथा - गैर वर्दी।
एक अंतराल भिन्नता सीमा का निर्माण करते समय, अंतराल (अंतराल अंतर) के आकार का चयन करने की समस्या का अक्सर सामना करना पड़ता है।
अंतराल के इष्टतम आकार को निर्धारित करने के लिए (घटना में जो समान अंतराल वाले पंक्ति का निर्माण किया जाता है) लागू होते हैं फॉर्मूला स्टारगेसा:
 , (6.4)
, (6.4)
जहां एन कुल की इकाइयों की संख्या है,
एक्स (अधिकतम) और एक्स (न्यूनतम) - पंक्ति के रूपों का सबसे बड़ा और सबसे छोटा मूल्य।
विविधता श्रृंखला की विशेषताओं के लिए, आवृत्तियों और पार्टियों के साथ, संचित आवृत्तियों और आवृत्तियों का उपयोग किया जाता है।
संचित आवृत्तियों (आवृत्तियों) दिखाएं कि कुल की कितनी इकाइयां (उनमें से कौन सा हिस्सा) निर्दिष्ट मान (विकल्प) x से अधिक नहीं है।
संचित आवृत्तियों ( वी मैं) असतत श्रृंखला के अनुसार, निम्नलिखित सूत्र के अनुसार गणना करना संभव है:
. (6.5)
अंतराल भिन्नता श्रृंखला के लिए - यह सभी अंतराल की आवृत्तियों (आवृत्तियों) का योग है जो इससे अधिक नहीं है।
अलग-अलग विविधताओं को ग्राफिक रूप से उपयोग किया जा सकता है बहुभुज आवृत्ति वितरण या आवृत्ति.
Abscissa अक्ष के साथ एक वितरण बहुभुज का निर्माण करते समय, सुविधा (वेरिएंट) के मान स्थगित कर दिए जाते हैं, और व्यवस्थित या आवृत्ति अक्ष के साथ। फीचर और इसी आवृत्तियों (आवृत्तियों) के मूल्यों के चौराहे पर, अंक स्थगित कर दिए जाते हैं, जो बदले में, खंडों से जुड़े होते हैं। परिणामी रिसाव आवृत्ति वितरण (आवृत्ति) का बहुभुज कहा जाता है।
|
|
|

 अंजीर। 6.1।
अंजीर। 6.1। अंतराल भिन्नताओं का उपयोग करके प्रतिनिधित्व किया जा सकता है हिस्टोग्राम। फिल्म चार्ट।
Abscissa अक्ष के साथ एक हिस्टोग्राम का निर्माण करते समय, अध्ययन विशेषता (अंतराल सीमाओं) के मान स्थगित कर दिए गए हैं।
यदि अंतराल एक ही मूल्य हैं, तो ऑर्डिनेट या आवृत्तियों या आवृत्तियों को ऑर्डिनेट अक्ष के साथ स्थगित किया जा सकता है।
यदि अंतराल के पास ऑर्डिनेट अक्ष के साथ अलग-अलग परिमाण होते हैं, तो पूर्ण या सापेक्ष वितरण घनत्व के मूल्यों को स्थगित करना आवश्यक है।
निरपेक्ष घनत्व - अंतराल के आकार के अंतराल की आवृत्ति का अनुपात:
; (6.6)
कहां: एफ (ए) मैं आई-वें अंतराल की पूर्ण घनत्व है;
एम I - आई-वें अंतराल की आवृत्ति;
k i i-th अंतराल (अंतराल अंतर) का मूल्य है।
पूर्ण घनत्व से पता चलता है कि कुल की कितनी इकाइयां अंतराल की प्रति इकाई होती हैं।
आपेक्षिक घनत्व - अंतराल के आकार के अंतराल की आवृत्ति का अनुपात:
; (6.7)
कहां: एफ (ओ) मैं आई-वें अंतराल की सापेक्ष घनत्व है;
डब्ल्यू मैं आई-वें अंतराल की आवृत्ति है।
सापेक्ष घनत्व से पता चलता है कि कुल इकाइयों का कौन सा हिस्सा अंतराल की प्रति इकाई है।
|
|
|

और असतत और अंतराल विविधता श्रृंखला ग्राफिक रूप से cumulatives और rags के रूप में दर्शाया जा सकता है।
जब निर्माण संकुचित असतत श्रृंखला के अनुसार, फीचर (विकल्प) के मान ABSCISSA अक्ष के साथ स्थगित कर दिए जाते हैं, और संचित आवृत्तियों या आवृत्तियों को धुरी पर जमा किया जाता है। संकेतों (विकल्प) और संबंधित संचित आवृत्तियों (आवृत्तियों) के चौराहे पर, अंक बनाए जाते हैं, जो बदले में, सेगमेंट या वक्र से जुड़े होते हैं। परिणामी टूटी हुई (वक्र) को एक संचयी (संचयी वक्र) कहा जाता है।
Abscissa धुरी के साथ अंतराल श्रृंखला के अनुसार cunulates का निर्माण करते समय, अंतराल की सीमाओं को स्थगित कर दिया जाता है। बिंदुओं के अवशोषण अंतराल की ऊपरी सीमाएं हैं। अध्यादेश संबंधित अंतराल की संचित आवृत्तियों (आवृत्तियों) बनाते हैं। अक्सर एक और बिंदु जोड़ते हैं, जिनमें से एब्सिसा पहले अंतराल की निचली सीमा है, और ऑर्डिनेट शून्य है। वर्गों या वक्र के साथ अंक कनेक्ट करना, हम संचयी हो जाते हैं।
ओगिवा यह इसी तरह के अंतर के साथ संचयी है कि Abscissa अक्ष लागू किया गया है, संचित आवृत्तियों (जनरलों) के अनुरूप, और ordinate अक्ष के अनुसार - साइन मान (विकल्प)।
रूसी संघ के अध्यक्ष के तहत राष्ट्रीय अर्थव्यवस्था और सार्वजनिक सेवा की रूसी एकेडमी
Oryol शाखा
प्रबंधन में गणित और गणितीय तरीकों विभाग
स्वतंत्र काम
गणित
इस विषय पर "विविधता श्रृंखला और इसकी विशेषताएं"
संकाय "अर्थशास्त्र और प्रबंधन" के पूर्णकालिक विभाग के छात्रों के लिए
प्रशिक्षण "कार्मिक प्रबंधन" के निर्देश
कार्य का उद्देश्य:प्राथमिक डेटा प्रोसेसिंग के गणितीय आंकड़ों और रिसेप्शन की अवधारणाओं को महारत हासिल करना।
ठेठ कार्यों को हल करने का एक उदाहरण।
कार्य 1।
सर्वेक्षण द्वारा, निम्नलिखित डेटा () प्राप्त किए गए थे:
1 2 3 2 2 4 3 3 5 1 0 2 4 3 2 2 3 3 1 3 2 4 2 4 3 3 3 2 0 6
3 3 1 1 2 3 1 4 3 1 7 4 3 4 2 3 2 3 3 1 4 3 1 4 5 3 4 2 4 5
3 6 4 1 3 2 4 1 3 1 0 0 4 6 4 7 4 1 3 5
जरुरत:
1) एक भिन्नता श्रृंखला (नमूना का सांख्यिकीय वितरण), एक रैंकिंग असतत विकल्पों को पूर्व-लेखन करना।
2) एक बहुभुज और cumulat का निर्माण।
3) सापेक्ष आवृत्तियों (आवृत्तियों) के वितरण की एक संख्या बनाएं।
4) विविध श्रृंखला की मुख्य संख्यात्मक विशेषताओं को ढूंढें (उनके प्रवास के लिए सरलीकृत सूत्रों का उपयोग करें): ए) औसत अंकगणित, बी) औसत मैं। और फैशन एमओ, सी) फैलाव एस 2।, डी) माध्यमिक वर्गबद्ध विचलन एस, ई) विविधता गुणांक वी.
5) प्राप्त परिणामों का अर्थ स्पष्ट करें।
फेसला।
1) संकलन के लिए विकल्पों की संख्या रैंकिंग मतदान डेटा को आकार में क्रमबद्ध करें और उन्हें आरोही क्रम में रखें।
0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2
3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4
5 5 5 5 6 6 6 7 7.
हम एक विविधता श्रृंखला बनायेंगे, तालिका की पहली पंक्ति में लिखे गए मान (विकल्प), और उनके अनुरूप दूसरी आवृत्ति में (तालिका 1)
तालिका एक।
2) आवृत्ति बहुभुज एक टूटी हुई बिंदु कनेक्टिंग है ( एक्स I.; एन मैं), मैं।=1, 2,…, म।कहां है म। एक्स।.
मैं विविधता श्रृंखला (चित्र 1) की आवृत्तियों के बहुभुज को चित्रित करूंगा।

चित्र .1। बहुभुज आवृत्ति
एक अलग विविधता सीमा के लिए संचयी वक्र (cumulat) एक टूटी हुई बिंदु कनेक्टिंग का प्रतिनिधित्व करता है ( एक्स I.; एनआईएच), मैं।=1, 2,…, म।.
संचित आवृत्तियों का पता लगाएं एनआईएच (संचित आवृत्ति दिखाती है कि छोटे के संकेत के संकेत के साथ कितने विकल्प मनाए गए थे एच)। तालिका 1 की तीसरी पंक्ति में पाए गए मान।
हम संचयी (चित्र 2) का निर्माण करते हैं।

रेखा चित्र नम्बर 2। कमुलत
3) हमें सापेक्ष आवृत्तियों (आवृत्तियों) मिलते हैं, जहां, कहां म। - सुविधा के विभिन्न संकेतों की संख्या एक्स।जिसे हम एक ही सटीकता के साथ गणना करेंगे।
हम तालिका 2 के रूप में सापेक्ष आवृत्तियों (आवृत्तियों) के कई वितरण लिखते हैं
तालिका 2
4) हमें विविध श्रृंखला की मुख्य संख्यात्मक विशेषताएं मिलती हैं:
ए) एक सरलीकृत सूत्र का उपयोग कर मध्य अंकगणित पाया गया:
 ,
,
जहां - सशर्त विकल्प
डाल से\u003d 3 (औसत मनाया मूल्यों में से एक), क।\u003d 1 (दो आसन्न विकल्पों के बीच अंतर) और एक गणना तालिका (तालिका 3) बनाते हैं।
टेबल तीन।
| एक्स I. | एन मैं। | यू I | यू आई एन मैं | यू मैं 2 एन मैं |
| -3 | -12 | |||
| -2 | -26 | |||
| -1 | -14 | |||
| योग | -11 |
फिर औसत अंकगणित

b) मंझला मैं। विविधता श्रृंखला को अवलोकन की रैंकिंग पंक्ति के बीच में आने वाली विशेषता का मूल्य कहा जाता है। इस असतत विविधता सीमा में सदस्यों की संख्या भी शामिल है ( एन\u003d 80), इसका मतलब है कि औसत दो मध्य विकल्पों के मध्य के बराबर है।
मॉडय एमओ विविधता सीमा को वह विकल्प कहा जाता है जिस पर उच्चतम आवृत्ति मेल खाती है। इस भिन्नता श्रृंखला के लिए, उच्चतम आवृत्ति एन अधिकतम \u003d 24 विकल्प को पूरा करता है एच \u003d 3, फिर फैशन एमओ=3.
ग) फैलाव एस 2।जो संकेतक के संभावित मूल्यों के बिखरने का एक उपाय है एक्स। इसके औसत के आसपास, हम सरलीकृत सूत्र का उपयोग करेंगे:
 कहां है यू I - सशर्त विकल्प
कहां है यू I - सशर्त विकल्प
इंटरमीडिएट गणना भी तालिका 3 में लाती है।
फिर फैलाव

डी) माध्यमिक वर्गिक विचलन एस सूत्र द्वारा खोजें:
![]() .
.
ई) भिन्नता का गुणांक वी: (),
विविधता गुणांक एक अतुलनीय मूल्य है, इसलिए यह भिन्नता श्रृंखला के बिखरने की तुलना करने के लिए उपयुक्त है, जिनमें से विभिन्न आयाम हैं।
भिन्नता का गुणांक
![]() .
.
5) प्राप्त परिणामों का अर्थ यह है कि मूल्य औसत चिह्न को दर्शाता है एक्स। विचार के तहत नमूना के भीतर, यह है कि औसत मूल्य 2.86 था। औसत वर्गिक विचलन एस संकेतक के मूल्यों के पूर्ण बिखरने का वर्णन करता है एक्स। और इस मामले में राशि एस ≈ 1.55। भिन्नता का गुणांक वी संकेतक की सापेक्ष परिवर्तनशीलता को दर्शाता है एक्स।, यानी, अपने औसत मूल्य के आसपास रिश्तेदार स्कैटर, और इस मामले में है।
उत्तर: ; ; ; .
कार्य 2।
मध्य रूस में 40 सबसे बड़े बैंकों की अपनी राजधानी पर निम्नलिखित डेटा हैं:
| 12,0 | 49,4 | 22,4 | 39,3 | 90,5 | 15,2 | 75,0 | 73,0 | 62,3 | 25,2 |
| 70,4 | 50,3 | 72,0 | 71,6 | 43,7 | 68,3 | 28,3 | 44,9 | 86,6 | 61,0 |
| 41,0 | 70,9 | 27,3 | 22,9 | 88,6 | 42,5 | 41,9 | 55,0 | 56,9 | 68,1 |
| 120,8 | 52,4 | 42,0 | 119,3 | 49,6 | 110,6 | 54,5 | 99,3 | 111,5 | 26,1 |
जरुरत:
1) अंतराल विविधताओं का निर्माण।
2) मध्य चयनात्मक और चुनिंदा फैलाव की गणना करें
3) औसत वर्गिक विचलन, और भिन्नता का गुणांक खोजें।
4) वितरण आवृत्ति का एक हिस्टोग्राम बनाएं।
फेसला।
1) अंतराल की एक मनमानी संख्या चुनें, उदाहरण के लिए, 8. फिर अंतराल की चौड़ाई:
![]() .
.
चलो एक गणना तालिका बनाते हैं:
| अंतराल विकल्प एक्स के -एक्स के +1 | आवृत्ति, एन मैं | मध्य अंतराल एक्स I. | सशर्त विकल्प और मैं। | और मैं एन मैं | और मैं। 2 एन मैं | (और मैं +।1) 2 एन मैं |
| 10 – 25 | 17,5 | – 3 | – 12 | |||
| 25 – 40 | 32,5 | – 2 | – 10 | |||
| 40 – 55 | 47,5 | – 1 | – 11 | |||
| 55 – 70 | 62,5 | |||||
| 70 – 85 | 77,5 | |||||
| 85 – 100 | 92,5 | |||||
| 100 – 115 | 107,5 | |||||
| 115 – 130 | 122,5 | |||||
| योग | – 5 |
झूठी शून्य के रूप में, मान चुना जाता है c \u003d।62.5 (यह विकल्प विविधता श्रृंखला के बीच में लगभग स्थित है) .
सशर्त विकल्प सूत्र द्वारा निर्धारित किए जाते हैं
संख्याओं का समूह, किसी भी संकेत द्वारा संयुक्त, कहा जाता है कुल।
जैसा कि ऊपर बताया गया है, प्राथमिक सांख्यिकीय खेल सामग्री बिखरे हुए नंबरों का एक समूह है जो विचारों के कोच को किसी घटना या प्रक्रिया के सार के बारे में नहीं देते हैं। यह कार्य इस कुलता को सिस्टम में बदलना है और आवश्यक जानकारी प्राप्त करने के लिए संकेतकों के साथ इसका उपयोग करना है।
भिन्नता श्रृंखला की तैयारी निश्चित रूप से एक निश्चित गणितीय का गठन है
उदाहरण 2. 34 स्कीयर में एथलीटों को दूरी (सेकंड में) के बाद इस तरह के एक पल्स रिकवरी समय पंजीकृत किया गया है:
81; 78: 84; 90; 78; 74; 84; 85; 81; 84: 79; 84; 74; 84; 84;
85; 81; 84; 78: 81; 74; 84; 81; 84; 85; 81; 78; 81; 81; 84;
जैसा कि देखा जा सकता है, संख्याओं के इस समूह को कोई जानकारी नहीं है।
विविधता संख्या की तैयारी के लिए, पहले ऑपरेशन का उत्पादन रैंकिंग - संख्याओं का स्थान आरोही क्रम या अवरोही में है। उदाहरण के लिए, आरोही क्रम में, रैंकिंग निम्न की ओर जाता है;
78; 78; 78; 78; 78; 78;
81; 81; 81; 81; 81; 81; 81; 81; 81;
84; 84; 84; 84; 84; 84; 84; 84; 84; 84; 84;
अवरोही क्रम में, रैंकिंग संख्याओं के ऐसे समूह की ओर जाता है:
84; 84; 84; 84; 84; 84; 84; 84: 84: 84; 84;
81; 81; 81; 81; 8!; 81: 81; 81; 81;
78; 78; 78; 78; 78; 78;
रैंकिंग के बाद, संख्याओं की संख्या के इस समूह की रिकॉर्डिंग का तर्कहीन रूप और एक ही संख्या कई बार दोहराई गई संख्या बन रही है। इसलिए, एक प्राकृतिक विचार रिकॉर्डिंग को इस तरह से परिवर्तित करने के लिए होता है ताकि यह निर्दिष्ट किया जा सके कि कौन सी संख्या दोहराई गई है। उदाहरण के लिए, आरोही क्रम में रैंकिंग पर विचार:
यहां, संख्या 34 एथलीटों के इस समूह में इस गवाही के पुनरावृत्ति के दाईं ओर, एथलीट की नाड़ी के पुनर्प्राप्ति के समय को इंगित करने वाली संख्या द्वारा दर्ज की गई है।
गणितीय प्रतीकों के बारे में उपर्युक्त अवधारणाओं के अनुसार, माप के माना समूह किसी भी पत्र को नामित करेगा, उदाहरण के लिए x। इस समूह में संख्याओं के बढ़ते क्रम को देखते हुए: x 1 -74 सी; x 2 - 78 एस; x 3 - 81 एस; x 4 - 84 एस; एक्स 5 - 85 एस; एक्स 6 एन - 9 0 एस, प्रत्येक माना जाने वाला नंबर एक्स I प्रतीक द्वारा नामित किया जा सकता है।
पत्र के माना माप के पुनरावृत्ति की संख्या को दर्शाता है। फिर:
n 1 \u003d 4; N 2 \u003d 6; N 3 \u003d 9; N 4 \u003d 11; N 5 \u003d 3; n 6 \u003d n n \u003d 1, और पुनरावृत्ति की प्रत्येक संख्या को एन I के रूप में दर्शाया जा सकता है।
उदाहरण की स्थिति से निम्न मापों की कुल संख्या 34 है। इसका मतलब है कि सभी एन का योग 34 के बराबर है। या प्रतीकात्मक अभिव्यक्ति में:
एक अक्षर - एन द्वारा इस राशि को इंगित करें। फिर विचाराधीन उदाहरण के प्रारंभिक डेटा को इस फॉर्म (तालिका 1) में दर्ज किया जा सकता है।
नस्लों का परिणामी समूह काम की शुरुआत में कोच द्वारा प्राप्त अराजक बिखरी हुई गवाही की रूपांतरित श्रृंखला है।
तालिका एक
| एक्स I. | एन मैं |
| N \u003d 34। |
ऐसा समूह एक विशिष्ट प्रणाली है जिसका पैरामीटर माप को दर्शाता है। माप परिणामों का प्रतिनिधित्व करने वाली संख्या (x i) कॉल विकल्प; एन मैं - उनकी पुनरावृत्ति की संख्या - कहा जाता है आवृत्तियों; एन - सभी आवृत्तियों का योग - वहाँ कुलता की मात्रा।
पूरी प्राप्त प्रणाली को बुलाया जाता है पासल के पास। कभी-कभी इन पंक्तियों को अनुभवजन्य या सांख्यिकीय कहा जाता है।
यह ध्यान रखना आसान है कि विविधता श्रृंखला का एक विशेष मामला संभव है, जब सभी आवृत्तियों एक एन i \u003d\u003d 1 के बराबर होती है, यानी, संख्याओं के इस समूह में प्रत्येक माप केवल एक बार मुलाकात की जाती है।
परिणामी भिन्नता श्रृंखला, किसी अन्य की तरह, ग्राफिक रूप से दर्शाया जा सकता है। परिणामी श्रृंखला का ग्राफ बनाने के लिए, आपको सबसे पहले क्षैतिज और ऊर्ध्वाधर धुरी के पैमाने पर होना चाहिए।
इस कार्य में, क्षैतिज धुरी पर, हम पल्स रिकवरी समय (एक्स 1) को इस तरह से जमा करेंगे कि मनमाने ढंग से निर्वाचित लंबाई की लंबाई एक सेकंड के मूल्य से मेल खाती है। यह इन मूल्यों को 70 सेकंड से स्थगित करना शुरू कर देगा, पारंपरिक रूप से दो अक्ष 0 के चौराहे से पीछे हटना शुरू कर देगा।
ऊर्ध्वाधर धुरी पर, हमारी पंक्ति (एन I) की आवृत्तियों के मानों को स्थगित करें, पैमाने लेना: लंबाई की इकाई आवृत्ति की एक इकाई के बराबर है।
शेड्यूल बनाने के लिए शर्तों को तैयार करें, प्राप्त विविधता के साथ काम करने के लिए आगे बढ़ें।
संख्या x 1 \u003d 74 की पहली जोड़ी, एन 1 \u003d 4 इस तरह के चार्ट पर लागू होती है: एक्स अक्ष पर; हम एक्स 1 पाते हैं =74 और हम इस बिंदु से लंबवत पुनर्स्थापित करते हैं, एन अक्ष पर हमें एन 1 \u003d 4 मिलते हैं और बहाल लंबवत के साथ चौराहे तक एक क्षैतिज रेखा लेते हैं। दोनों लाइनें लंबवत और क्षैतिज सहायक लाइनें हैं और इसलिए बिंदीदार रेखा के चित्रण पर लागू होते हैं। उनके चौराहे का बिंदु इस ग्राफ के पैमाने पर एक अनुपात x 1 \u003d 74 और n 1 \u003d 4 है।
इसी तरह, अनुसूची के अन्य सभी बिंदु लागू किए जाते हैं। फिर वे सीधी रेखाओं के वर्गों से जुड़े हुए हैं। अनुसूची के लिए एक बंद रूप होने के लिए, चरम बिंदु क्षैतिज धुरी के आसन्न बिंदुओं के साथ सेगमेंट को जोड़ते हैं।
परिणामी आंकड़ा हमारी विविधता श्रृंखला (चित्र 1) का एक ग्राफ है।
यह स्पष्ट है कि प्रत्येक भिन्नता श्रृंखला का अपना कार्यक्रम प्रतीत होता है।

अंजीर। 1. विविधता श्रृंखला का ग्राफिक प्रतिनिधित्व।
अंजीर में। 1 शो:
1) सबसे अधिक सर्वेक्षण किए गए सबसे बड़े समूह एथलीटों के लिए जिम्मेदार हैं, पल्स का वसूली का समय, जो 84 एस;
2) इस बार कई 81 हैं;
3) सबसे छोटा समूह एक छोटी नाड़ी वसूली के समय के साथ एथलीट था - 74 एस और बड़े - 90 एस।
इस प्रकार, परीक्षणों की एक श्रृंखला करके, प्राप्त संख्याओं को रैंक किया जाना चाहिए और एक भिन्नता श्रृंखला तैयार की जानी चाहिए, जो एक विशिष्ट गणितीय प्रणाली है। स्पष्टता के लिए, विविधताओं को अनुसूची द्वारा सचित्र किया जा सकता है।
उपरोक्त भिन्नता सीमा को अभी तक बुलाया जाता है अलग अगला - यह, जिसमें प्रत्येक विकल्प एक संख्या में व्यक्त किया जाता है।
आइए विविधता श्रृंखला को संकलित करने के लिए कुछ और उदाहरण दें।
उदाहरण 3। 12 निशानेबाजों, 10 शॉट्स में से एक अभ्यास का प्रदर्शन करते हुए, ऐसे परिणाम दिखाए गए (चश्मे में):
94; 91; 96; 94; 94; 92; 91; 92; 91; 95; 94; 94.
एक भिन्नता सीमा बनाने के लिए, हम डेटा संख्या रैंक करेंगे;
94; 94; 94; 94; 94;
रैंकिंग के बाद, हम एक भिन्नता श्रृंखला (तालिका 3) बनाते हैं।