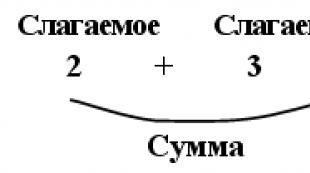
Gene locus definition. Bestämning av förhållandet mellan två genloci. Avslöjande vidhäftning. Se vad "Locus" är i andra ordböcker
Grisavel i Europa och Amerika börjar använda genomiskt urval. Dess teknologier gör det möjligt att dechiffrera genotypen av grisar vid födseln och välja ut de bästa djuren för avel. Denna senaste teknologi är designad för att ytterligare öka urvalsnoggrannheten och tillförlitligheten av avelsvärdet hos grisar.
Förfadern till genomiskt urval är markörselektion.
Markörselektion är användningen av markörer för att markera gener av en kvantitativ egenskap, vilket gör det möjligt att fastställa närvaron eller frånvaron av vissa gener (alleler av gener) i genomet.
En gen är en bit av DNA, en specifik sekvens av nukleotider, i vilken information om syntesen av en proteinmolekyl (eller RNA) kodas, och som en konsekvens tillhandahåller bildandet av en egenskap och dess överföring genom nedärvning.
Gener representerade i populationen av flera former - alleler - är polymorfa gener. Alleler av gener delas in i dominanta och recessiva. Genetisk polymorfism ger en mängd olika egenskaper inom en art.
Men bara ett fåtal egenskaper kontrolleras av individuella gener (till exempel hårfärg). Produktivitetsindikatorer är som regel kvantitativa egenskaper, för utvecklingen och manifestationen av vilka många gener är ansvariga. Vissa av dessa gener kan ha mer uttalade effekter. Dessa gener kallas de grundläggande generna för de kvantitativa egenskapsställena (QTL). Quantitative trait loci (QTL) är DNA-regioner som innehåller gener eller kopplade till gener som ligger bakom en kvantitativ egenskap.
För första gången underbyggdes idén om att använda markörer i avel teoretiskt av A.S. Serebrovsky redan på 1920-talet. Markör (som då kallas "signal", den engelska termen "marker" började användas senare) enligt AS Serebrovsky är en allel av en gen som har en uttalad fenotypisk manifestation, lokaliserad bredvid en annan allel som bestämmer en ekonomiskt viktig studerad egenskap, men har ingen tydlig fenotypisk manifestation; Genom att göra ett urval för den fenotypiska manifestationen av denna signalallel, finns det ett urval av länkade alleler som bestämmer manifestationen av egenskapen som studeras.
Inledningsvis användes morfologiska (fenotypiska) egenskaper som genetiska markörer. Men mycket ofta har kvantitativa egenskaper en komplex karaktär av arv, deras manifestation bestäms av miljöförhållanden och antalet markörer som används som fenotypiska egenskaper är begränsat. Sedan användes genprodukter (proteiner) som markörer. Men det är mest effektivt att testa genetisk polymorfism inte på nivån av genprodukter, utan direkt på nivån av gener, det vill säga att använda polymorfa DNA-nukleotidsekvenser som markörer.
Vanligtvis ärvs DNA-fragment som ligger nära varandra på kromosomen tillsammans. Denna egenskap gör att en markör kan användas för att bestämma det exakta arvsmönstret för en gen som ännu inte har exakt lokaliserats.
Markörer är således polymorfa regioner av DNA med en känd position på kromosomen, men okända funktioner, som kan användas för att identifiera andra gener. Genetiska markörer måste vara lätt identifierbara, kopplade till ett specifikt lokus och mycket polymorfa eftersom homozygoter inte ger någon information.
Den utbredda användningen av varianter av DNA-polymorfism som genetiska markörer började 1980. Molekylärgenetiska markörer användes för program för att bevara genpoolerna av raser av husdjur, med deras hjälp, problemen med rasernas ursprung och distribution, upprättande av relationer, kartlägga de viktigaste platserna för kvantitativa egenskaper, studera de genetiska orsakerna till ärftliga sjukdomar, acceleration av urval enligt individuella egenskaper - motstånd mot vissa faktorer, enligt produktiva indikatorer. I Europa har genetiska markörer använts i grisuppfödning sedan början av 1990-talet. att befria befolkningen från halotangenen, som orsakar stresssyndrom hos grisar.
Det finns flera typer av molekylärgenetiska markörer. Tills nyligen var mikrosatelliter mycket populära, eftersom de är utbredda i genomet och har en hög nivå av polymorfism. Mikrosatelliter - SSR (Simple Sequence Repeats) eller STR (Simple Tandem Repeats) består av DNA-sektioner 2-6 baspar långa, upprepade i tandem många gånger. Till exempel har det amerikanska företaget Applied Biosystems utvecklat ett genotypningstestsystem för 11 mikrosatelliter (TGLA227, BM2113, TGLA53, ETH10, SPS115, TGLA126, TGLA122, INRA23, ETH3, ETH225, BM1824). Emellertid är mikrosatelliter ofta otillräckliga för finkartläggning av enskilda regioner av genom; de höga kostnaderna för utrustning och reagens och utvecklingen av automatiserade metoder som använder SNP-chips driver dem ur praktiken.
En mycket bekväm typ av genetiska markörer är SNP (Single Nucleotide Polymorphisms) - snip eller enkel nukleotidpolymorfism- dessa är skillnader i DNA-sekvensen för en nukleotid i genomet hos representanter för samma art eller mellan homologa regioner av homologa kromosomer hos en individ. SNP är punktmutationer som kan uppstå som ett resultat av spontana mutationer och verkan av mutagener. En skillnad på ens ett baspar kan vara orsaken till en förändring i egenskapen. SNP:er är brett spridda i genomet (hos människor, cirka 1 SNP per 1000 baspar). Grisgenomet har miljontals punktmutationer. Ingen annan typ av genomisk skillnad är kapabel att tillhandahålla en sådan täthet av markörer. Dessutom har SNP: er en låg mutationshastighet per generation (~ 10-8), i motsats till mikrosatelliter, vilket gör dem bekväma markörer för populationsgenetisk analys. Den största fördelen med SNP är möjligheten att använda automatiska metoder för att detektera dem, till exempel användningen av DNA-mallar.
För att öka antalet SNP-markörer på senare tid har ett antal utländska företag anslutit sig till deras ansträngningar och skapat en enhetlig databas för att genom att testa ett stort antal djur som testats för produktivitet för polymorfism kunna avslöja förekomsten av kopplingar mellan kända punktmutationer och produktivitet.
För närvarande har ett stort antal polymorfa varianter av gener och deras ömsesidiga inflytande på de produktiva egenskaperna hos grisar identifierats. Flera genetiska tester som använder produktionsmarkörer är allmänt tillgängliga och används i avelsprogram. Genom att använda dessa markörer kan du förbättra några av prestationsindikatorerna.
Exempel på produktivitetsmarkörer:
- fertilitetsmarkörer: ESR - östrogenreceptorgen, EPOR - erytropoietinreceptorgen;
- sjukdomsresistensmarkörer - ECR F18-receptorgen;
- markörer för tillväxteffektivitet, köttproduktivitet - MC4R, HMGA1, CCKAR, POU1F1.
MC4R - genen för melanokortin 4-receptorn hos grisar finns på kromosom 1 (SSC1) q22-q27. Ersättning av en nukleotid A med G leder till en förändring i aminosyrasammansättningen av MC4-receptorn. Som ett resultat är det ett brott mot regleringen av utsöndringen av fettvävnadsceller, vilket leder till en kränkning av lipidmetabolismen och direkt påverkar processen för bildandet av tecken som kännetecknar gödnings- och köttkvaliteter hos grisar. Allel A är ansvarig för snabb tillväxt och större fetttjocklek, medan allel G är ansvarig för effektiv tillväxt och en hög andel magert kött. Homozygota grisar med genotyp AA når marknadsvikten tre dagar snabbare än grisar som är homozygota för G-allelen (GG), men grisar med genotyp GG har 8 % mindre fett och har en högre foderomvandlingshastighet.
Dessutom påverkas kött- och gödningsproduktiviteten av andra gener som styr ett komplex av associerade fysiologiska processer. POU1F1-genen, en hypofys transkriptionsfaktor, är en regulatorisk transkriptionsfaktor som bestämmer uttrycket av tillväxthormon och prolaktin. Hos grisar kartläggs POU1F1-lokuset på kromosom 13. Dess polymorfism beror på en punktmutation som leder till bildandet av två alleler - C och D. Närvaron av allel C i grisgenotypen är associerad med ökad genomsnittlig daglig viktökning och högre mognad.
Markörer låter dig också testa genotypen av galtar för könsbegränsade egenskaper, som endast manifesteras hos suggor. Det är till exempel fertilitet (antal smågrisar per grisning), som galten för vidare till avkomman. Till exempel, testning av genotypen av en galt för östrogenreceptormarkörer (ESR) kommer att välja ut de galtar för avel som kommer att ge deras döttrar bättre reproduktiva egenskaper.
Med hjälp av resultaten av markörselektion är det möjligt att uppskatta frekvensen av förekomsten av önskvärda och oönskade alleler för en ras eller linje, för att genomföra ytterligare selektion så att alla djur i rasen endast har föredragna alleler av gener.

Ris. 1. Funktionsprincip för ett oligonukleotidbiochip
Ett DNA-chip är ett substrat med celler med en reagenssubstans applicerad på den. Testmaterialet märks med olika etiketter (vanligen fluorescerande färgämnen) och appliceras på biochippet. Som visas på bilden binder reagenssubstansen - oligonukleotiden - endast det komplementära fragmentet i testmaterialet - fluorescensmärkta DNA-fragment. Som ett resultat observeras en glöd på detta element av biochipet.
2009 avkodades grisens arvsmassa. SNP-chip utvecklat ( DNA-mikroarrayvariant), innehållande 60 000 genetiska markörer av genomet. För att påskynda forskningen skapades till och med speciella robotar för att läsa klipp. Ett gris-DNA-prov kan testas för närvaro eller frånvaro av praktiskt taget alla viktiga punktmutationer som bestämmer produktiva egenskaper. Således kan urvalet av de bästa djuren baseras på genetiska markörer utan att mäta fenotypiska parametrar.
Dessa framsteg har lett till introduktionen av en ny teknologi - genomiskt urval. Genomisk selektion testar genomet på en gång för ett stort antal markörer som täcker hela genomet, så att kvantitativa egenskaper loci (QTL) är i länkojämvikt med minst en markör. Vid genomisk selektion utförs genomskanning med hjälp av chips (matriser) med 50-60 tusen SNP (som markerar huvudgenerna för kvantitativa egenskaper) för att identifiera enkelnukleotidpolymorfismer längs djurets genom, bestämma genotyper med den önskade manifestationen av en uppsättning av produktiva egenskaper och bedöma djurets avelsvärde.
Termen "genomiskt urval" myntades först av Hayley och Visher 1998. Meuwissen et al. Utvecklade och presenterade 2001 en metodik för analytisk bedömning av avelsvärde med hjälp av en markörkarta som täcker hela arvsmassan.
Den praktiska tillämpningen av genomiskt urval började 2009.
Sedan 2009 har de största företagen i USA (Cooperative Resources International), Nederländerna, Tyskland, Australien börjat introducera genomiskt urval i boskapsuppfödningsprogram. Tjurar av olika raser genotypades för över 50 000 SNP.
Hypor var den första att tillkännage ett komplett säljbart Genomic Breeding-program, vilket kommer att öka noggrannheten i urvalet i grisuppfödning. Det tillkännagavs i media i juni 2012 att Hypor kunde erbjuda sina kunder en besättning utvald med Genomic Breeding Value.

Genetikföretaget Hypor började använda genomisk avel 2010, i nära samarbete med Center for Scientific Research and New Technologies i Hendrix Genetics-gruppen (Hendrix Genetics). Hendrix Genetics testar över 60 000 SNP-markörer och använder denna information för DNA-forskning. Det genomiska indexet för den genetiska potentialen hos grisar beräknas efter analys av 60 000 genmarkörer (snips) för djuret. I teorin, om det finns tillräckligt många genetiska markörer för att täcka hela grisens DNA (dess genom), är det möjligt att beskriva all genetisk variation för alla mätbara egenskaper. En modern matematisk och genetisk programvara för databehandling håller på att förberedas.
Genetikföretaget Hendrix Genetics har en stor biobank – den lagrar blod- och vävnadsprover från avelsdjur från flera gårdar och generationer för DNA-forskning (avslöjar djurens genetiska värde) och analys av djurens genotyp. Hypor har utfört gris-DNA-tester vid sina uppfödningsanläggningar i över två år. Alla prover från olika förädlingsanläggningar i olika länder skickas för bearbetning till det nya centrala Hendrix Genetics Genomic Laboratory i Plufragan (Frankrike). Gerard Albers, chef för Center for Research and Emerging Technologies, betonar: "Genomlabbet är en värdefull tillgång som används av alla genetiska företag som utgör Hendrix Genetics och är verkligen unik i grisindustrin."
Genomiskt urval är ett kraftfullt verktyg för framtiden. För närvarande begränsas effektiviteten av genomiskt urval av den olika karaktären av interaktionen mellan platserna för kvantitativa egenskaper, variationen av kvantitativa egenskaper hos olika raser och påverkan av miljöfaktorer på manifestationen av egenskapen. Men forskningsresultat i många länder har bekräftat att användningen av statistiska metoder i samband med genomisk skanning ökar tillförlitligheten i avelsvärdesförutsägelser.
Urvalet av grisar med statistiska metoder för vissa indikatorer (till exempel sjukdomsresistens, köttkvalitet, fertilitet) kännetecknas av låg effektivitet. Detta beror på följande faktorer:
- låg ärftlighet av egenskaper,
- stort inflytande på detta tecken på miljöfaktorer,
- på grund av manifestation begränsad av kön,
- manifestation av ett tecken endast under påverkan av vissa faktorer,
- när debuten av egenskapen inträffar relativt sent,
- på grund av att egenskaper är svåra att mäta (till exempel hälsoegenskaper),
- förekomsten av dolda bärare-skyltar.
Till exempel är en sådan defekt hos grisar som stresskänslighet svår att diagnostisera och visar sig i ökad dödlighet hos smågrisar under påverkan av stress (transport, etc.) och försämring av köttkvaliteten. DNA-testning med hjälp av genmarkörer gör det möjligt att identifiera alla bärare av denna defekt, inklusive dolda, och med detta i åtanke genomföra selektion.
För att bedöma produktivitetsindikatorer som är svåra att förutsäga med statistiska metoder, för en mer tillförlitlig bedömning, behövs en analys av avkomman, det vill säga det är nödvändigt att vänta på avkomman och analysera dess avelsvärde. Och användningen av DNA-markörer gör det möjligt att analysera genotypen omedelbart vid födseln, utan att vänta på manifestationen av en egenskap eller utseendet på avkomma, vilket avsevärt påskyndar urvalet.
Indexbedömningen av djuren utförs enligt de yttre och produktiva egenskaperna (tidig mognad hos smågrisar, etc.). I båda fallen används fenotypiska indikatorer, därför är det nödvändigt att känna till deras ärftlighetskoefficient för att kunna använda dessa egenskaper i beräkningar. Men även i det här fallet kommer vi att ta itu med sannolikheten för den genetiska motiveringen av någon egenskap, de genomsnittliga indikatorerna för dess förfäder och ättlingar (det finns inget sätt att avgöra vilka gener det unga djuret ärvde: den bästa eller den sämsta av detta genomsnitt). Med hjälp av genotypanalys är det möjligt att noggrant fastställa faktumet av nedärvning av vissa gener redan vid födseln, att utvärdera genotyper direkt och inte genom fenotypiska manifestationer.
Men om grisar väljs ut för indikatorer på hög ärftlighet, såsom lätt kvantifierbara spenantal, kommer genomiskt urval inte att ge några betydande fördelar.
Marköravel förnekar inte traditionella metoder för att bestämma avelsvärde. Statistisk analys och genomisk selektionsteknik kompletterar varandra. Användningen av genetiska markörer gör det möjligt att påskynda processen för urval av djur och indexmetoder - för att mer exakt bedöma effektiviteten av detta urval.
Genomisk uppfödning är en möjlighet att göra grisproduktionen till en korrekt produktion. Användningen av genomisk urvalsteknik kommer att göra det möjligt att producera en mängd olika köttprodukter som möter konsumenternas behov.
Återpublicering av material från denna webbplats är endast tillåtet om du anger en hyperlänk till informationskällan!
FÖRELÄSNING 1. Klassisk och molekylär genetik. Grundbegrepp: egenskap, fenotyp, genotyp, gen, lokus, allel, homozygot, heterozygot, hemizygot.
ICG SB RAS och FEN NSU, Novosibirsk, 2012
1.1. Klassisk och molekylär genetik
Dagens föreläsning är en introduktion, vi går vidare till detaljerna senare. Som i fallet med nästan vilken vetenskap som helst, är genetikens gränser svåra att avgränsa, och en mycket allmän definition " genetik - vetenskapen om ärftlighet"- inte särskilt fruktbart. Zhimulev, till exempel, sa en gång att nu finns genetik överallt - inom medicin, rättsmedicin, evolutionsteorin, arkeologin och i genetiken i sig är till och med nukleinsyror nästan osynliga - alla proteininteraktioner. Därmed satte han faktiskt ett likhetstecken mellan genetik och all modern biologi. Å andra sidan, under ungefär de första två tredjedelarna av 1900-talet, var genetik kanske det mest isolerade och väldefinierade området inom biologin, som främst utmärker sig för sin syntetiska metodik, i motsats till den analytiska metodiken för andra grenar. av biologi. För att ta reda på strukturen på hennes föremål delade hon inte upp det i delar, utan bedömde delarna på ett indirekt sätt, genom att observera helheten (nämligen genom att observera karaktärernas beteende i kors) och förlita sig på matematik, och hon var övertygad om riktigheten av hennes slutsatser och tog emot levande organismer med förutspådda egenskaper. Således hade genetik från allra första början förmågan att skapa något nytt, och inte bara beskriva det observerade. Samtidigt, under andra hälften av 1900-talet, utvecklades molekylärbiologin snabbt - en vetenskap till en början rent analytisk, splittrad i delar. Dess framsteg utfördes dock till stor del genom genetiska metoder - kom ihåg åtminstone att den genetiska koden etablerades i experimenten av Benzer och Crick med mutationer i bakteriofager. Men i det här fallet användes mikroorganismernas genetik, och utvecklingen av "klassisk" genetik har alltid associerats med genetiken hos eukaryoter.
Som ett resultat har molekylärbiologin fått en nästan uttömmande kunskap om vad en levande organism är gjord av och hur. Ämnena molekylärbiologi och genetik överlappade varandra på många sätt: båda studerade överföring och implementering av ärftlig information (och en levande organism är implementeringen av ärftlig information), men de gick mot att förstå detta ämne från motsatta sidor - genetik " utanför”, molekylärbiologi “inifrån”.
Under den sista tredjedelen av 1900-talet möttes molekylärbiologi och genetik så att säga, bland annat i studiet av eukaryoter. Genetikens spekulativa föremål har förvandlats till helt specifika fysikalisk-kemiska föremål med en känd struktur, och molekylärbiologi har blivit en syntetisk vetenskap, som kan påverka efter eget gottfinnande även de högsta flercelliga organismerna - ta åtminstone genetisk modifiering. Här suddades gränserna för genetik som vetenskap ut till den grad att de inte kunde urskiljas – det blev omöjligt att säga var molekylärbiologin slutar och genetiken börjar. Dessutom, för att beteckna den resulterande syntetiska vetenskapen, dök termen "molekylär genetik" upp, som ett resultat av vilket det blev svårt att förstå vad som exakt återstod i genetik utanför den senare. Genetik från den premolekylära perioden, med alla dess tillvägagångssätt baserade på korsningar och sannolikhetsteorin, tilldelades hederstiteln "klassisk genetik". Däremot skickades hon med denna titel så att säga i hederspension. Du kan komma ihåg hur Watson och Crick vägrade att diskutera sin modell av DNA:s struktur i sin artikel i Nature, eftersom konsekvenserna av det var för stora och uppenbara. Vid något tillfälle kan det tyckas att all genetik följer av denna modell.
En paradoxal situation håller på att utvecklas. Alla genetikkurser börjar med denna vetenskaps historia. Den undersöker hur Mendel arbetade med ärter, vad han fick och hur han tolkade det utifrån sina kunskaper, sedan hur Morgan och hans skola arbetade med fruktflugor, vad de fick och hur de tolkade det. Det är omöjligt att utelämna båda dessa ämnen - Mendel visar oss ett exempel på en person som utvecklades från grunden och på ett briljant sätt tillämpade en genetisk metod baserad på matematik, och Morganskolan under de första tre decennierna av 1900-talet utvecklade kromosomteorin om ärftlighet och praktiskt taget all klassisk genetik. Vidare kan genetikkurser delas in i två stora klasser. Några av dem utarbetar i detalj hela historien och den interna logiken i utvecklingen av denna vetenskap, och visar både kraften i dess metodik och förmågan hos det mänskliga sinnet i spekulativ penetrering i sakers djup. Andra kurser, som snabbt hoppar över denna historiska period, går vidare till molekylär genetik och där överväger de vad som är känt för närvarande om geners struktur och arbete. Faktum är att båda typerna av kurser placerar klassisk genetik i det förflutna och skiljer sig endast i flashback-detaljer. Det visar sig att klassisk genetik så att säga bara har historisk betydelse. Dess kraftfulla metodik har dock inte gått någonstans och är nödvändig för ett mycket brett spektrum av forskning. Om vi tittar på de artiklar som har helt molekylärbiologiska namn och publicerade i de bästa tidskrifterna, kommer vi att se att de alla är baserade på omfattande material om hundratals individuella mutationer och deras kombinationer, med hänsyn tagen till förhållandet mellan mutationers natur och fenotypen som de orsakar. Detta gäller både för Drosophila eller möss, för vilka enorma genetiska samlingar har samlats in och speciella laboratorielinjer har skapats (vissa för cirka hundra år sedan, andra nyligen), och för människor, där en enorm mängd medikogenetik, i faktum, populationsgenetisk - data associerade med ärftliga sjukdomar. Och ju rikare denna arsenal av kunskap och modellorganismer är, desto elegantare är arbetet. Alla dessa mer än seriösa studier är omöjliga utan samtidig behärskning av metodiken för klassisk och molekylär genetik. Därför är det bäst att studera dessa "två genetik" parallellt, hur svårt det än är att organisera.
Inom modern vetenskap kan man observera exempel på hur försummelsen av "föråldrad" klassisk genetik leder till kuriosa. Till exempel behövde en grupp europeiska forskare erhålla en heterozygot för translokation i ärter. (Jag talar nu på grundval av att du har en aning om vad som diskuteras. Om det inte finns spelar det ingen roll, vi kommer fortfarande att överväga allt detta nästan för mycket detaljerat, för nu pratar vi om behovet av genetisk kunskap). De fick det genom sammansmältning av protoplaster från föräldralinjerna. Regenerering från cellodling i ärter är extremt svårt, det är ett extremt mödosamt sätt. Varför gjorde de det? Tydligen trodde de att bärare av translokationen inte korsade sig med vanliga ärter! Faktum är att problem med reproduktionen vid korsning av föräldrar som skiljer sig i translokation uppstår, men bara i nästa generation och består i förlusten av endast hälften av fertiliteten.
Men dessa forskare behövde åtminstone en heterozygot. Samtidigt leder den allmänna fascinationen för molekylärbiologi och ignorering av klassisk genetik till det faktum att förekomsten av heterozygoter - det vill säga det faktum att i eukaryoter varje gen är representerad i två kopior, som kan vara olika och kan vara identiska - är ofta helt bortglömd. Till exempel kom en artikel av tyska författare för min recension, där de direkt läste en viss icke-kodande DNA-sekvens från 38 trollsländor fångade i olika regioner (Västra Europa, Västra Sibirien, Japan och Nordamerika) och hittade 20 varianter av den . Det skrevs som att det bara fanns en variant i varje individ. Men om variabiliteten verkligen är så hög som de hävdar, så är sannolikheten att det finns minst en individ i deras urval, där båda kopiorna av denna sekvens visar sig vara lika, inte mycket skild från noll. Och det diskuterades inte ens på något sätt. Efter granskningen skrev de att det i fem fall fanns misstanke om heterozygositet. Om det verkligen bara finns fem, så hade de i sina händer ett fantastiskt fenomen med omvandlingen av heterozygoter till homozygoter med hjälp av ännu okända mekanismer, men de verkade inte ens förstå detta.
Rekonstruktioner av fylogeni baserade på vissa DNA-sekvenser är nu utbredda. Så, ganska ofta görs försök på basis av divergenstiden mellan populationer att bedöma om dessa populationer tillhör samma biologiska art eller till olika. (Observera att det är tidpunkten för divergens som uppskattas, eftersom generna som studeras, vars variabilitet är mer eller mindre konstant i tiden, verkligen inte är de gener med en förändring i vilka artbildning kan associeras). Samtidigt har tidpunkten för divergens i allmänhet lite att göra med detta problem - ögonblicken då en viss lokal befolkning förvärvar reproduktiv isolering, det vill säga ögonblick av artbildning, inträffar under vissa förhållanden och tar vanligtvis inte mycket tid från en paleontologisk synvinkel (tiotals till hundratusentals år), sedan hur populationer kan divergera under lång tid utan artbildning. Frågan är just att ta reda på om det finns reproduktiv isolering (åtminstone potential) mellan populationer. För att göra detta bör du se om det finns ett utbyte av gener mellan dem (om det är fysiskt möjligt) eller inte. Här är det bara väldigt viktigt att ta reda på om heterozygoter är närvarande vid korsningen av populationer för de alleler som är karakteristiska för var och en av dem, och vad är deras frekvens. Men nästan ingen gör detta, och huruvida en population tillhör samma eller olika arter bedöms utifrån nivån på skillnaderna mellan dem, och jämför dem med skillnaderna i de fall som antas vara säkra.
I allmänhet, om en enskild organism (till exempel som en representant för sin egen art) kan undersökas med metoderna för molekylär genetik, så uppstår så snart det kommer till en mängd organismer, det vill säga ett populationsgenetiskt problem - och ett sådant problem uppstår ganska ofta, till exempel i populationsbiologi och urval - här kan man inte klara sig utan den klassiska genetikens tillvägagångssätt. Klassisk genetik är oumbärlig i allt som rör individuella skillnader och egenskaper hos många individer av samma art. Detta är just dess element, och det är i det som de nuvarande vetenskapsmännen som har ersatt den klassiska genetiska utbildningen med molekylärbiologiska ofta visar sig vara hjälplösa.
Baserat på det föregående ser jag min uppgift att presentera klassisk genetik inte så mycket i den historiska aspekten, följa de stora forskarna från det förflutna, som att utgå från det nuvarande vetenskapens tillstånd, i synnerhet, utan att abstrahera från den kunskap som du redan har mottagits i kurserna molekylärbiologi och cytologi. Samtidigt får vissa regelbundenheter som upptäckts som rent empiriska på organismnivå en helt naturlig tolkning på molekylnivå och ser nästan triviala ut. Samtidigt bör man ha en klar uppfattning om dessa lagar själva, eftersom de bör användas på organismnivå. På sätt och vis är en sådan kurs i genetik tänkt som något i stil med en "demonstration av trick med avslöjanden" - där själva tricket och dess bakgrund är lika "medicinska fakta". En sådan kurs skulle vara utformad för att lära ut en mycket produktiv metodik: att gå ner från en egenskap till gener och, genom att förstå mekanismen för deras verkan, gå tillbaka till syntesen av nya egenskaper.
Som du redan förstått är innehållet i genetik för närvarande enormt och heterogent, så den tid som tilldelats oss är osannolikt att räcka även för en kort bekantskap. Detta tvingar oss att lämna genetikens historia bakom kulisserna som ett självständigt ämne, som borde ha ägnats åt en speciell kurs.
Tyvärr motsvarar ingen av de tillgängliga läroböckerna det ideal som skisserats ovan för att studera genetik på nuvarande stadium - från egenskap till gen och vice versa - troligen för att denna vetenskap utvecklas för snabbt nu. Som en kompensation för denna omständighet kommer jag att försöka ladda upp mina blygsamma föreläsningar på min egen sida, där de kommer att vara tillgängliga för dem som jag ger sin adress till – det vill säga dig. Jag skulle rekommendera att ta Vechtomovs lärobok "Genetik med urvalets grunder" som grund. Läroboken för akademikern Igor Fedorovich Zhimulev "Allmän och molekylär genetik" är också välkänd, där huvudvikten ligger på molekylär genetik, och Leonid Vladimirovich rekommenderar den som en grundläggande lärobok. Jag förstår att två grundläggande läroböcker inte är den lämpligaste situationen för att klara provet. Men å andra sidan bidrar det till förståelsen av ämnet. Jag kan säga att jag personligen är här och i allmänhet arbetar på Institutet för cytologi och genetik enbart för att jag gick en kurs i genetik av Vladimir Aleksandrovich Berdnikov. Detta var den bästa kursen jag har hört, och den motsvarade inte någon lärobok alls, eftersom V.A. Igor Fedorovich gjorde också sin ursprungliga föreläsningskurs till en lärobok.
Vi kommer att beröra grunderna i genetik mycket grundligt för att få en bra känsla för dem. Vi kommer att börja från början, trots att de mest grundläggande grunderna för genetik lärs ut i skolan, så Gud förbjude att inte missa något enkelt, men viktigt. Å andra sidan har jag att göra med studenter som redan har slutfört en kurs i molekylärbiologi och för närvarande studerar sannolikhetsteorin och matematisk statistik, vilket gör att jag inte blir alltför distraherad av materialen i dessa kurser som är så nödvändiga för att studera genetik. Till exempel kommer jag att anta att du vet (eller kommer att veta vid rätt tidpunkt) vad alternativ splitsning eller Poisson-distribution är.
Standardlogiken för presentationen av biologi i universitetskurser är att flytta från botten till toppen, från atomer till molekyler och makromolekyler, sedan till cellens strukturer, till själva cellens liv och sedan till den flercelliga organismen. När vi känner till principerna för att organisera livet till slutet, visar sig denna presentationsordning vara organisk och naturlig. Dessa principer inkluderar också mekanismen för hur nukleinsyror fungerar som informationsbärare, främst om olika proteiner och funktionella RNA (som efter upptäckten av små RNA visade sig vara mer mångsidig än man tidigare trott), och inte bara om deras struktur, men också om när, var och hur många av dessa eller dessa RNA eller proteiner som ska syntetiseras. Kontrollen av dessa processer utförs igen med hjälp av vissa proteiner (och ofta RNA). Det finns en kaskadprincip för utvecklingen av genetiska kontrollsystem - gener kodar för proteiner (RNA) som är nödvändiga för att kontrollera gener som kodar för andra proteiner (RNA), etc. Eftersom nästan allt i kroppen i allmänhet är "gjort" av proteiner (plus några RNAs) visar det sig att information om hela organismen faktiskt registreras i nukleinsyror i allmänhet - dock är det omöjligt att läsa denna information utan tidigare syntetiserade (igen, med hjälp av DNA-matrisen) proteiner, som arbetar med DNA.
Denna presentationsordning sammanfaller helt med den ordning i vilken livet självt utvecklades. Till en början var dessa något slags "enkla" (men bara i jämförelse med vad som senare uppstod ur dem) system av självreproducerande makromolekyler, tydligen nukleinsyror. Sedan råkade de omge sig med ett fosfolipidmembran, vilket gjorde att de kunde bygga sitt eget mikrokosmos inuti det. Så här kom cellerna till. Proteiner spelade en allt viktigare roll i funktionen hos dessa första levande varelser, men kontrollen över nukleinsyror var helt bevarad. Cellerna blev mer komplexa och lärde sig att dela sig mer och mer korrekt. Efter delningen skiljde de sig ibland inte och bildade kolonier. Dessa kolonier stod inför allt mer komplexa problem i samband med deras storlek och form - alla celler i kolonin måste förses med allt de behövde för att leva. Lösningen på dessa problem uppnåddes på grund av en viss struktur hos kolonierna och arbetsfördelningen mellan deras ingående celler. Enkla kolonier har förvandlats till celltillstånd, det vill säga till flercelliga organismer. Problemen med deras självreproduktion som komplexa strukturer löstes också, och detta realiserades på ett sådant sätt att varje organism kunde utvecklas från en cell genom utplaceringen av ett komplext genetiskt program som reglerar celldelning och interaktioner mellan dem.
Denna standardordning för presentation av biologisk kunskap distraheras emellertid från hur den erhölls. Och de erhölls när vetenskapen utvecklades i motsatt riktning - från organismer till organ, celler, makromolekyler och atomer. När de dök in i var och en av dessa nivåer kunde forskare bara göra gissningar om hur den djupare nivån fungerar. När det maximala de kunde göra var att öppna kroppen, titta på organen och gissa hur de fungerar. När cellerna öppnades trodde man först att de var fyllda med tomhet. Sedan upptäckte de protoplasman, men först såg de den bara som en trögflytande vätska, som dock på något mystiskt sätt innehöll livets väsen. Upptäckte cellens kärna och organeller. Vi hittade färgämnen som färgar dem olika, och närmade sig därmed deras kemiska sammansättning. I slutet av artonhundratalet. upptäckte nukleinsyror och fick reda på deras ungefärliga kemiska sammansättning, men deras specifika struktur förblev ett mysterium under lång tid, vars lösning såg så lysande ut. Vid detta upphörde kanske nedsänkningen i biologins djup. Perioden av ackumulering av detaljer på denna djupa molekylära nivå har kommit. Det fanns ett ovanligt stort antal uppgifter. Nu går vi igenom en period då detta enorma antal detaljer börjar kombineras till en sorts sammanhängande bild - en modell av strukturen hos en levande organism. Dessutom är denna modell så komplex att den inte helt kan uppfattas av mänskligt medvetande, så att inte bara dess konstruktion, utan också en visuell beskrivning och användning är omöjlig utan moderna datorer. Ändå i slutet av nittonhundratalet. alla biologins grundläggande principer upptäcktes. Klassisk genetik genom ansträngningar från flera begåvade vetenskapsmän utvecklades nästan i full form under de första tre decennierna av nittonhundratalet som en harmonisk och logisk vetenskap.
Klassisk genetik är bara ett levande exempel på forskarens rörelse från makronivå till mikronivå. Hon rekonstruerar systemets schema enligt dess beteende och närmar sig det som en svart låda. Som om de främmande mekanismerna för en okänd enhet utan några diagram och instruktioner för dem föll i händerna på forskare. Två av dess huvuddrag kan noteras. Den första är det fantastiska rekonstruktionsdjupet, som det uppnådde med brist på direkt information om objektets struktur. Kraften i det klassiska genetiska tillvägagångssättet är imponerande: genom att bara ta itu med synliga egenskaper, gjorde det det möjligt att skapa en idé om begripliga gener, om deras placering i några mystiska linjära bärare, om förändringar i gener och dessa bärare. Baserat på bilden av nedärvningen av egenskaper, med dess hjälp, erhölls en idé om strukturen hos bärare av genetisk information, överföringen av denna information till ättlingar och dess omvandling till levande kött. Den andra egenskapen är den redan nämnda syntetiska snarare än analytiska karaktären hos genetisk kunskap, vars rättvisa, i själva processen att erhålla den, omedelbart förkroppsligades i skapandet av något nytt - organismer med nya egenskaper. Det räcker med att ha en väl studerad genetik för ett fåtal modellobjekt, sedan kan resten av objekten bedömas efter graden av likhet med dem. Thomas Morgans välkända aforism "vad som är sant för en fluga är sant för en elefant" är naturligtvis en ganska stark överdrift, och vi kommer att vara övertygade om detta. Detta tillvägagångssätt (som också fick sitt uttryck i den så kallade lagen om homologiska serier) fungerar dock fortfarande.
Den huvudsakliga metoden för klassisk genetik är korsning. Genetik kom till de flesta av sina slutsatser genom att observera beteendet hos föräldrars och avkommor, och forskarens handlingar med varje ny generation bestäms av resultaten som erhölls i den föregående. Därför är genetisk forskning lite som ett schackspel. Slutsatserna från sådana studier var extremt detaljerade och, vilket framgår av vetenskapens fortsatta utveckling, är de korrekta. Gregor Mendel i sina experiment på ärter i slutet av 1800-talet. postulerade faktiskt existensen och beskrev kromosomernas beteende vid meios, utan att ha den minsta aning om kromosomer. Relationen mellan gener och kromosomer etablerades först i början av 1900-talet, och nästan fram till mitten var det starkt misstänkt att proteiner är ärftlighetens materiella bärare. Med andra ord, om andra grenar av biologin inte bröt sig loss från det beskrivande tillvägagångssättet, var genetiken i dess modeller långt före den tid då de föremål som studerades av den kunde beskrivas som materiella enheter. Under den tragiska perioden i den ryska vetenskapens historia, som föll under det ideologiska diktatet på 30-50-talet av förra seklet, gav detta upphov till att förklara genetik en idealistisk pseudovetenskap och kasta vårt land, som låg i framkant, långt tillbaka, och fysiskt förstöra de bästa genetikerna.
En sådan kognitiv kraft av klassisk genetik som en vetenskap, som kan dra korrekta slutsatser om beteendet hos vissa mikrostrukturer i en cell, baserat på beteendet hos karaktärer i kors, även utan att ha en uppfattning om vad de består av, är i första hand på grund av att genetik innehåller mycket matematik från dess olika branscher. Och denna omständighet beror sin existens på det faktum att föremålet för genetik inte är någon biologisk struktur, utan information. Information kan studeras oavsett vilket materiellt medium den implementeras på. Så en programmerare i sitt arbete behöver inte veta hur exakt hans program kommer att förkroppsligas i tillståndet av kristaller i en datorprocessor, även om han är medveten om att det kommer att implementeras på denna fysiska grund. Genetik är i huvudsak biologisk informatik. Förr i tiden kallades datavetenskap för cybernetik. Och detta var ännu en "pseudovetenskap" som förföljdes under Stalin och Chrusjtjov, med all skillnad mellan dem. (Lyckligtvis var det då inte lika utvecklat i form av en gren inom matematiken som genetik i form av en gren av biologi, och som ett resultat gjorde detta företag mindre skada).
"Klassisk" genetik(kallas ibland Mendelian, även om vad som menas är mycket bredare än vad Mendel upptäckt, och här kan det ökända ideologiska stigmat "Mendelism-Morganism" vara mer passande) definieras som vetenskapen om ärftlighet, som arbetar med abstrakta delar av organismens utvecklingskontrollsystem, som distraheras från sin materialbärare och i princip inte behöver den. Respektive, molekylär genetik kan definieras som vetenskapen om molekylära mekanismer bakom ärftlighet... Jag hoppas att det skulle vara överflödigt att uppmana till att inte lägga stor vikt vid dessa och liknande formella definitioner. I verklig vetenskaplig praxis existerar inte "två genetiker", och ännu mer gränsen mellan dem, och ovanstående definitioner indikerar bara den allmänna tankeriktningen ...
Det är dock känt att varje definition av vad som helst är ofullkomlig, eftersom vårt tänkande inte är matematisk logik och begrepp - vad vårt tänkande arbetar med - inte kan reduceras till ord - att med vars hjälp vi fixar och kommunicerar med vissa förluster av att tänka. Koncept är endast möjliga förstå(med varierande grad av tydlighet), observera deras interaktioner med tidigare vittnen begrepp på en uppsättning texter, där begrepp betecknas med ord. Definitionen är bara den mest kortfattade och effektiva texten som för dig närmare förståelsen, men det finns alltid situationer där någon definition inte fungerar (även om begreppen gör det). Där det är möjligt försöker jag ge definitioner som förefaller mig mest lämpliga, bryr mig inte så mycket om hur de motsvarar tidigare föreslagna eller ursprungliga, men jag tar dem inte på alltför stort allvar och väldigt långt ifrån tanken att ta ner dem under diktat. och att memorera dem kan göra det lättare att förstå ämnet.
Till en början bestod genetiken i den ensamma bedriften av en enda vetenskapsman som inte förstods av någon samtida och som på grund av sitt personliga geni och mångsidiga utbildning själv föreslog en fruktbar metodik, och noggrant utförde långa och omfattande experiment och gjorde en omöjlig spekulation. antagande. Strax efter återupptäckten av genetik, det vill säga dess uppkomst redan som en vetenskap av många, upptäcktes det att ärftlighetsfaktorer är belägna i en strikt definierad ordning och på ett visst avstånd från varandra i flera linjära strukturer, antalet, relativa storleken och beteende som sammanföll med antalet, relativ storleken och beteendet hos kromosomerna i meios. Den kromosomala teorin om ärftlighet formulerades 1900-1903. av den amerikanske cytologen William Setton och den tyske embryologen Theodore Boveri och vidareutvecklad av den berömde amerikanske genetikern Thomas Morgan och hans skola - Möller, Stertevant, Brigdes. (Detta var första gången, sedan 1906, de började forska på fruktflugor, och först planerade de kaniner, men denna plan missade inte ekonomichefen på deras universitet. Charles Woodworth var den första som odlade fruktflugor, han föreslog också att det kunde bli ett lämpligt objekt för att studera ärftlighet.) Och denna viktiga slutsats om att hitta faktorerna för ärftlighet i kromosomer, som erhölls så tidigt, förkastades av den officiella vetenskapen i Sovjetunionen från slutet av 1940-talet till början av 1960-talet !
En jämförelse av spekulativa genetiska kartor (geners relativa position i dessa strukturer) och olika delar av kromosomerna gjorde det uppenbart att gener finns i dem. Men detta är inte så nödvändigt för klassisk genetik - dess modeller, testade av resultaten av korsningar, sätter gener i ett slags "virtuella kromosomer". Så, till denna dag, för de flesta föremål, finns det två typer av kromosomkartor: fysiska kort, visar exakt var gener finns på kromosomer som är synliga genom ett mikroskop eller på en DNA-molekyl, och genetisk, eller rekombinationskartor rekonstruera det ömsesidiga arrangemanget av gener baserat på resultaten av korsningar. Ordningen på gener i dessa två typer av kartor sammanfaller helt, de relativa avstånden mellan dem är långt ifrån alltid och det finns ganska omfattande förklaringar till detta, som kommer att diskuteras senare.
Som en vetenskap om information och kontroll har klassisk genetik till och med en struktur som liknar matematik. Det hela vilar på ett system av spekulativa a priori-begrepp med vilka de observerade fenomenen är korrelerade (i motsats till t.ex. från cytologin, vars begreppsapparat introduceras på basis av empiriska fakta som är synliga för ögat). Tyvärr, i den terminologi som motsvarar dessa begrepp (och begreppen och termerna är inte desamma), har en viss inkonsekvens ackumulerats under existensen av genetik, som jag kommer att fokusera speciellt på så att du inte vilseleds av olika ordanvändningar i genetisk litteratur. Naturligtvis introduceras genetiska begrepp på basis av observerbara fakta. Men de viktigaste introduceras snarare som spekulativa matematiska begrepp. Det finns många begrepp och termer som motsvarar dem inom genetiken. Men de behövs verkligen, och när de introduceras uttömmar de praktiskt taget ämnet. I många fall räcker det att jämföra det observerade fenomenet med ett lämpligt koncept, och allt blir klart. Kanske, som en lärobok i genetik, en bra Ordbok genetiska termer. Det vore mer pedagogiskt korrekt att införa begreppsapparaten och terminologin när och när behovet uppstår. Men det skadar inte om du introducerar och diskuterar grundläggande begrepp från början, och sedan markerar de platser där de behövs. Vi kommer att utgå från det faktum att du redan är bekant med vissa begrepp åtminstone från skolkursen och ibland använder dem redan innan de diskuteras i detalj.
1.2. Tecken på organismer. Fenotyp och genotyp.
Det kanske viktigaste genetiska konceptet är skylt... Genetik som vetenskap började precis i det ögonblick då Gregor Mendel började analysera individuella egenskaper, och inte all ärftlighet som helhet. Säg mig, vad är ett tecken? Och hur många av dem kan det bli? En egenskap är allt som förknippas med en individ, så länge det finns ett sätt att registrera det på något sätt. Höjd, vikt, färg, gråthöjd, halva svanslängden adderad till kvadratroten av en tredjedel av näsans längd, antalet hårstrån i skägget, formen på hålan eller myrstacken, antalet hanar att jaga en kvinna, hur lång tid under vilken du inte kan andas under vattnet, antalet älskare av mamman eller dottern till det studerade ämnet. Jag skämtar inte - bland tecknen på bärare av en viss variant av en av dopaminreceptorerna finns en hög frekvens av tecknet "växte upp utan pappa" (det är tydligt att det här mer handlade om ett tecken på en av föräldrarna, och inte ämnet som diskuteras, som dock kunde ärva en anlag ).
Valet är enormt, men ju mer framgångsrik, klokare eller kvickare du väljer ett tecken, desto mer information kommer du att lära dig av erfarenhet. Det är klart att du inte ska lägga till kvadratroten av nosens längd till längden på svansen, eftersom båda längderna har samma dimension, och som ett resultat kommer du att få ett matematiskt skratt. Men om vi lägger till kubroten av kroppsmassan till längden på svansen, är det mer meningsfullt, eftersom massan beror på kuben med linjära dimensioner och efter att ha extraherat kubroten får vi ett värde som står i proportion till längden av svansen, och lägger vi till de två nämnda kvantiteterna, får vi ett visst mått linjära dimensioner.
Det är lätt att förstå att inte alla tecken på deras oändliga variation är lika informativa. Vissa är lika informativa, men tillför ingenting till varandra. Till exempel, om vi tar två sådana tecken: längden på det högra benet och längden på det vänstra benet, så är det till och med intuitivt klart att även om de två benen kan skilja sig något i längd, kommer det andra att lägga lite till det första. Låt oss ta sådana tecken: längden på vänster ben och höjd. Vad kan vi säga om dem? Ju mer höjd, desto längre ben - detta är ganska uppenbart. Höjd och benlängd korrelerar - inte mer, men inte mindre. Faktum är att om vi tar ett urval av människor, mäter höjden och längden på benen och beräknar korrelationskoefficienten, kommer den att vara ganska nära en och mycket tillförlitlig. Men vi vet att människor faktiskt är kortbenta och långbenta. Och om vi tar höjden och förhållandet mellan benens längd och höjden, får vi två helt oberoende egenskaper - linjära dimensioner och beniga, som kan ärvas oberoende.
Vi har nu ett förhållande på två uppmätta storheter. Att arbeta med många funktioner samtidigt kräver som regel korrekt statistisk bearbetning. För denna typ av bearbetning är det inte särskilt bekvämt att hantera relationer. Men sedan finns det en uppsättning matematiska metoder som kallas multivariat statistik(särskilt, huvudkomponentanalys för kvantitativa egenskaper), vilket gör att vi kan erhålla N nya egenskaper från vilket N som helst som mäts av oss, vilka är linjära kombinationer av de ursprungliga (deras summor med olika koefficienter) som inte kommer att korrelera med varandra. Detta innebär att var och en av dem kommer att bära oberoende information. Och om vi tittar på hur N av dessa nya funktioner är sammansatta, kommer vi att se att en av dem reflekterar till exempel linjära dimensioner (detta kommer att inkludera alla möjliga längder på kroppen, armar, ben etc.), den andra - tjockleken, den tredje - ojämnheten i tjockleken (svårigheten av midjan, höfterna och bysten), den fjärde är den relativa storleken på huvudet, den femte är mörkningen av huden, etc. Sådana tecken är de mest informativa, och de har ett annat bidrag till objektens totala variation, vilket också kan uppskattas. Multivariata analysmetoder löser dock inte problemet med duplicering av funktioner, eftersom duplicering påverkar det nämnda relativa bidraget till den totala variabiliteten av den nya egenskapen som de faller i. Detta problem har inte lösts i matematisk statistik förrän nu.
Tecken kan vara väldigt olika, men de delas in i två stora klasser - kvalitet, eller alternativ, och kvantitativ, eller ständig... En egenskap är kvalitativ i det fall variabiliteten visar sig i att det finns flera alternativa varianter av egenskapen, det vill säga i att en individ tillhör en viss tydlig klass, och dess tilldelning till en av klasserna är utom tvivel. Till exempel finns det två sådana klasser av mänskliga individer som män och kvinnor. Kvinnor kan också delas in i flera alternativa klasser. Anta att en tjej är klädd i byxor eller att hennes ben är klädda i ett enda cylindriskt material - en klänning eller en kjol. Vi får två klasser. Det senare fallet kan delas in i två klasser - att bära en klänning eller en kjol. Vi får tre klasser av kvinnor. Kvinnor kan säkert identifiera många alternativa klädklasser utan att ha det minsta svårt att klassificera dem. Klassiska exempel: ärtblommor - vita eller lila, fruktfluga ögon - igen vita eller lila; roligt, men båda organen kan också vara rosa, och detta är ett annat villkor för en kvalitativ egenskap, en separat klass. I de fall där det är möjligt att särskilja kvalitativa (alternativa) karaktärer, och individer som tillhör olika klasser (varianter) regelbundet finns i naturen, är det vanligt att tala om polymorfism, och klasserna (varianterna) av dessa funktioner brukar kallas morfer, eller former Detta är från början samma ord, på grekiska och latin, men betydelsen av det andra är för tvetydig, och det är bättre att undvika det. Etymologiskt betecknar båda orden form, men eftersom termer tillämpas på alla egenskaper, till exempel förknippade med färg. Nedan visas två varianter - med gula respektive lila blommor - av Altai höghöjdsviol, som förekommer i naturen med ungefär lika frekvens.
https://pandia.ru/text/78/138/images/image002_73.jpg "width =" 283 "height =" 311 src = ">. jpg" width = "347" height = "453 src =">
Eftersom vi alla gick i skolan kan vi misstänka att vit och lila iris är homozygoter för vissa alleler, och lila är heterozygot för dessa alleler. Men vi (i synnerhet jag) har ännu inte sådan information, och i alla fall måste vi börja med ett uttalande om tre färgmorfer.
Vi nämnde tre distinkta färgklasser för ärtblommor - vit, lila och rosa. Men på gatan växer Zolotodolinskaya äppelträd med lila kronblad. Och det finns äppelträd med rosa, lite rosa och vita kronblad. När det gäller nejlikor som säljs i stånd verkar det för oss att tecknet på blomfärgen är kvalitativt - det finns röda, vita, rosa och vita med röda kanter på kronbladen. Och blomsterförädlare har förmodligen en sådan variation av nejlikor att egenskapen blir kvantitativ. Du kan ta en spektrofotometer, extrahera antocyanpigmentet från ett standardprov av kronblad och mäta intensiteten av den lila antocyaninfärgningen, uttryckt som ett tal. Och så får vi kvantitativ egenskap- detta är ett tecken som kan uttryckas med ett reellt tal. En och samma egenskap i olika situationer kan fungera både kvantitativt och kvalitativt. För nästan alla kvalitativa attribut kan du hitta ett sätt att mäta det och därmed betrakta det som kvantitativt. Tvärtom kan de flesta kvantitativa egenskaper inte betraktas som kvalitativa, eftersom värdena för den uppmätta parametern sällan grupperas i klart urskiljbara klasser.
Människolängd (om vi utesluter uppenbar dvärgväxt) är ett typiskt kvantitativt tecken. Hur många tillväxtmöjligheter finns det för en normal person? Det är rätt, du kan inte säga - det här är ett positivt reellt tal, och antalet "alternativ" beror på noggrannheten med vilken vi mäter och vilka fysiska gränser för denna kvantitet som finns. Tillväxten för många människor kan karakteriseras av dess genomsnittliga värde. Men vi behöver också vissa egenskaper hos dess variation. För att göra detta måste vi studera frekvensfördelningen av den kvantitativa egenskapen. Ett annat läroboksexempel: om du tar många människor, mäter deras höjd till närmaste centimeter och bygger dem på höjden så att personer med samma höjd står i en kolumn, så får vi följande bild: längden på kolumnerna bildar en typ av klockformad kurva. Med tillräcklig granularitet när det gäller att mäta höjd och antalet personer, kommer den att återge väl vad som är välkänt i sannolikhetsteorin - vanligt eller Gaussisk fördelning.
Varians "href =" / text / kategori / dispersiya / "rel =" bokmärke "> varians - den genomsnittliga kvadraten av avvikelserna för enskilda värden från medelvärdet. Kvadratroten av detta värde ger standardavvikelse, dess dimension sammanfaller med dimensionen för det uppmätta värdet och det kan fungera som ett mått på spridningen av attributet. I intervallet av värden från medelvärdet minus standardavvikelsen till medelvärdet plus standardavvikelsen finns det cirka 70 % av alla normalfördelade objekt, oavsett hur många vi mäter dem. Om detta intervall runt medelvärdet utökas två gånger, kommer det att finnas cirka 90%, om tre gånger, då cirka 99% av objekten.
Den centrala gränssatsen för matematisk statistik säger att fördelningen av summan av ett stort antal oberoende slumpvariabler närmar sig det normala. Och praktiskt taget alla kvantitativa egenskaper bildas under påverkan av ett stort antal flerriktade och olika styrkefaktorer (detta gäller särskilt för kroppsstorlek). Det är därför de flesta av de kvantitativa egenskaperna är föremål för en normalfördelning.
Detta påstående är emellertid också sant endast i den första approximationen. Som ni vet är det absolut nödvändigt att uppmärksamma randvillkoren för att bedöma acceptansen av en modell. Normalfördelningen är symmetrisk och ges på hela uppsättningen av reella tal, från - till +, även om sannolikhetstätheten minskar med avståndet från medelvärdet ganska snabbt. Låt oss som exempel återgå till attributet "mänsklig höjd". Vi har faktiskt ingen hård övre gräns för en persons längd, och oavsett vilken rekordhållare vi hittar finns det aldrig en garanti för att det förr eller senare inte kommer att finnas något högre ämne. Men det finns en nedre gräns även teoretiskt - trots allt kan en persons höjd per definition inte vara mindre än noll. Detta innebär att randvillkoren inte klarar den Gaussiska modellen för mänsklig höjd. Dessutom, om vi tar många människor, upptäcker vi att deras fördelning i termer av höjd är något asymmetrisk och sned åt höger - den fysiska nedre gränsen vid noll gör sig påmind! Vilken modell kan vi föreslå istället för den Gaussiska som mer adekvat för de kvantitativa egenskaperna hos biologiska objekt?
Låt oss tänka på det här. Tecken bildas under den individuella utvecklingen av organismen, vilket i själva verket är en mycket komplex kemisk reaktion som sker under kontroll av gener, som vid vissa tidpunkter ger vissa koncentrationer av vissa ämnen. Dessa koncentrationer fungerar som faktorer i ekvationerna för de hastigheter som utgör den individuella utvecklingen av reaktioner (till exempel Michaelis-ekvationerna), och värdena på tecknen beror direkt på några av dessa (eller till och med alla) hastigheter. Därför går de individuella bidragen från individuella gener till en kvantitativ egenskap vanligtvis inte ihop, utan multipliceras, det vill säga att varje gen ökar eller minskar värdet på en egenskap med flera gånger. Produkten av många oberoende slumpvariabler tenderar att lognormalfördelning... Som ett resultat är de verkliga fördelningarna av kvantitativa egenskaper hos organismer inte normala, utan lognormala. De är verkligen väldigt lika, men ändå något asymmetriska - plattare till höger.
https://pandia.ru/text/78/138/images/image007_23.jpg "width =" 304 "height =" 416 src = ">
Normala (A och B) och dvärgärter (C).
Det är denna egenskap - internodens relativa längd - som är en alternativ egenskap här, medan växttillväxt mycket sällan beter sig som en riktig alternativ egenskap.
Det finns ytterligare en villkorligt framstående klass av funktioner som du måste ha en klar uppfattning om. Låt oss ta ett sådant tecken som antalet grenar på en marals horn. De minsta hornen är ogrenade. I maxfallet har vi 10 grenar på båda hornen. Vi kommer inte att uppleva några svårigheter att klassificera det ena eller det andra hornet till en klass med ett visst antal processer, och utifrån detta kan vi tycka att detta är ett kvalitativt tecken. Men kvaliteten här korrelerar med ett heltal, och antalet klasser, som en serie heltal, är obegränsat (ingen kan garantera att vi förr eller senare inte kommer att stöta på en maral med 11 eller fler bihang). Sådana tecken kallas räkning; de kallas också meristisk, vilket kan vara förvirrande, eftersom vi inte behöver mäta här, utan just att räkna. Det finns faktiskt ett enkelt mönster här - ju större hornet är, desto fler grenar har det; bara för att processen ska läggas till måste hornknoppen få en viss ökning av kritisk massa. Så det räknarbara antalet bihang är bara ett mått på hornets storlek. När det gäller antalet celler på vingen av en trollslända blir detta ännu mer uppenbart. Vi får samma mått när vi mäter, när vi stannar vid en del av dess noggrannhet. Tänk om vi inte räknar ett rådjurs horn, utan hårstrån på dess unga horn. Det har vi faktiskt olika åtgärder storleken på hornet, men med olika steg (avrundning).
De arbetar med att räkna funktioner med samma tillvägagångssätt som med kvantitativa, med vissa funktioner i matematisk bearbetning. Och det skulle vara ett misstag att tillämpa på dem samma tillvägagångssätt som används för alternativa skyltar. Till exempel studerade en grupp forskare från Moskva antalet celler i vissa zoner av trollsländornas vingar. De beräknade det genomsnittliga antalet celler, bestämde medelvärdet och standardavvikelsen och fann till exempel att dessa medelvärden var statistiskt signifikant olika i två olika vattenförekomster. De drog slutsatsen att populationerna på de två sjöarna är genetiskt specifika – utifrån att alternativa egenskaper nödvändigtvis måste bestämmas av ärftliga faktorer, en eller några få. Men sedan opererade de med sin egenskap som en kvantitativ sådan! Troligtvis utvecklades trollsländor i en av reservoarerna under mindre gynnsamma förhållanden och hade ett mindre vingområde, på vilket färre celler fick plats, vars storlek var ganska standardiserad i ontogeni.
Slutligen urskiljs ofta en tredje stor klass av funktioner - rangfunktioner. Vi talar om de fall då vi kan rangordna objekt på basis av "mer" / "mindre" ("bättre" / "sämre"), men vi har inte en direkt möjlighet att uttrycka denna egenskap av överlägsenhet hos vissa över andra numeriskt. Situationerna där rangtecken uppstår är ganska olika. På paradplatsen kan vi enkelt bygga soldater efter höjd, utan att mäta deras höjd, på samma plats, med axelband, vi kan lätt känna igen militära led, i förväg veta i vilken ordning de är rangordnade i förhållande till varandra. I vissa fall är vi tvungna att subjektivt utvärdera vissa komplexa integrerade parametrar, till exempel "styrkan" hos enskilda växter, klassificera dem i "starka", "medelstora" och "svaga".
Det är märkligt att så fort vi har rangordnar har vi redan ett grovt numeriskt mått på en egenskap, om än en mycket ungefärlig eller subjektiv sådan. Följaktligen är rangordningar, som är ordningstal, heltal i sig själva. Och det är redan möjligt att arbeta med dem som med mätbara egenskaper. Med alla konventionella en sådan "mätning", utvecklad matematiska metoder, vilket gör det möjligt att få mycket tillförlitliga slutsatser på grundval av dem. Dessutom kan även otvivelaktiga kvalitativa egenskaper ganska grovt bearbetas som kvantitativa. Till exempel, om vi har fyra färgmorfer, kan vi betrakta dem inte som en kvalitativ egenskap, utan som fyra kvantitativa egenskaper, som var och en kan ta två värden - 0 (en individ tillhör inte denna morf) och 1 (en individ tillhör en given morph). Erfarenheten visar att sådana liknande artificiella "kvantitativa egenskaper" kan bearbetas framgångsrikt.
Som exempel visar med tillväxten av ärter kan samma egenskap vara både kvantitativ och kvalitativ. Varje kvalitet vi särskiljer kan alltid på något sätt mätas (även att vara manlig och kvinnlig kan mätas som förhållandet mellan vissa hormoner). Valet av hur man arbetar med en funktion - som med värdet på en numerisk parameter eller som en indikator på att tillhöra en klass - dikteras av specifikationerna för ett visst problem. När det gäller en bimodal fördelning är det användbart att dela upp alla individer i två klasser, åtminstone i den första approximationen, även om fördelningens två puckel går samman och vi inte entydigt kan klassificera de individer som faller mellan dem, förutom genom att införa ett formellt tröskelvärde.
Både kvalitativa och kvantitativa egenskaper kan ärvas i en eller annan grad och faller därför inom genetikens synfält. Genetik använder olika modeller för att analysera kvantitativa och kvalitativa egenskaper. Nedärvningen av kvalitativa egenskaper (det var med dem Mendel arbetade) beskrivs i termer av kombinatorik och sannolikhetsteori på ett enklare och mer exakt sätt, och vi kommer främst att behandla det. Nedärvningen av kvantitativa egenskaper beskrivs i termer av matematisk statistik och bygger främst på analys av korrelationer och nedbrytning till varianskomponenter. Som nämnts ovan kan nedärvning av kvalitativa egenskaper också behandlas som nedärvning av kvantitativa egenskaper, vilket i vissa fall visar sig vara ett mycket fruktbart tillvägagångssätt. Jag hoppas att vi kommer att ha tid att kortfattat se över början av kvantitativ egenskapsgenetik. Under tiden lite mer terminologi.
Två inte mindre vida begrepp än ett tecken, som dock inte kan undvikas - genotyp och fenotyp... Dessa termer själva, såväl som termen " gen", introducerad 1909 av den danske genetikern Wilhelm Ludwig Johansen. Fenotypen är allt som rör egenskaperna hos organismerna i fråga, genotypen är allt som rör deras gener. Det är klart att det kan finnas ett oändligt antal egenskaper, och det finns tiotusentals gener. Dessutom registrerar ingen den överväldigande majoriteten av tecknen, och ingen känner till den överväldigande majoriteten av gener. Men fenotyp och genotyp är arbetsbegrepp, vars innehåll i varje enskilt fall dikteras av ett genetiskt experiment. Ett genetiskt experiment består vanligtvis av att någon korsas med någon, ofta i många generationer, och man övervakar avkommans tecken, som kan väljas ut, korsas etc. i enlighet med dessa egenskaper, eller ett urval av individer tas bort från naturen , registrera deras tecken, ta reda på vilka varianter vissa gener representeras av, observera dynamiken i deras frekvenser. I varje fall följer vi strikt definierade egenskaper och gener, ofta några få. Och när vi pratar om fenotypen, menar vi värdena eller tillstånden för dessa speciella egenskaper, och när vi talar om genotypen, då uppsättningen av dessa speciella gener. Den första är beroende av den andra, men som vi kommer att se är den inte den mest direkta. Vid bestämning av detta beroende består genetik i många avseenden. Och bara om själva DNA-sekvensen framträder som en egenskap, sammanfaller fenotypen med genotypen.
Först nyligen har det blivit möjligt att genomföra högteknologiska experiment för att spåra alla kända gener för de objekt som de är kända för (till exempel en människa) - till exempel närvaron eller frånvaron av allt budbärar-RNA eller alla proteiner i en speciell vävnad. Motsvarande riktningar benämndes "proteomics" respektive "transcriptomics", och helheten av alla proteiner eller budbärar-RNA som finns i ett eller annat objekt, respektive - proteom och transkript.
1.3. Begreppen "gen", "lokus", "allel", "ortolog", "paralog", "mutation".
Baserat på vårt preliminära uttalande om att det finns mycket matematik inom genetik, borde vi ha förväntat oss terminologisk rigor i det. Tyvärr är detta också en empirisk vetenskap, som existerar på ett enormt och heterogent experimentellt material, tillverkat av många vetenskapsmän med olika specialiseringar (och olika utbildning!), och detta ledde till existensen i genetiken av olika terminologiska "dialekter", inklusive i saker och ting. mycket viktigt. Låt oss gå vidare till ett begrepp som kan tyckas vara centralt för genetiken, men som i verkligheten visade sig vara för vagt för detta. Berätta vad som är gen? I själva verket är detta ett begrepp som var väldigt otur, så nu har det flera betydelser. I klassisk genetik en gen är en ärftlig faktor som påverkar en organisms egenskaper... Det ansågs en gång som en ytterligare odelbar enhet av ärftlighet. Efter upptäckten av DNA:s struktur stod det snabbt klart att många klassiska gener är delar av DNA som kodar för ett visst protein, till exempel ett enzym som bestämmer den ärvda egenskapen. Detta var ett enormt genombrott inom vetenskapen, och på den här vågen verkade det till en början så Allt den klassiska genetikens gener är precis så. Följande formel utvecklades: " En gen - en polypeptidkedja". Det föreslogs, i den ursprungliga formuleringen "en gen - ett enzym", 1941 (det vill säga 12 år innan DNA-strukturen dechiffrerades av Watson och Crick) av George Beadle och Edward Tatham (du kan hitta porträtt av dessa och många andra forskare i läroboken) som arbetade med stammar av neurospormögel som skilde sig i deras förmåga att utföra vissa biokemiska reaktioner och fann att varje gen är ansvarig för en specifik biokemisk reaktion, det vill säga för ett visst stadium av mögelmetabolism. För detta arbete fick de Nobelpriset 1948. Observera att genen i det skedet fortfarande förstods ganska klassiskt, men aktiv forskning utfördes för att ta reda på vad det är rent fysiskt. Och efter upptäckten av DNA:s struktur verkade allt falla på plats och genomet började kallas DNA-delen som kodar för polypeptidkedjan.
Men med tiden fann man att det bredvid den kodande sekvensen alltid finns regulatoriska DNA-sekvenser som inte kodar för någonting själva, utan påverkar på-av- och transkriptionsintensiteten för denna gen. Du känner dem väl: denna promotor är landningsstället för RNA-polymeras, operatörer är landningsställena för regulatoriska proteiner, och förstärkare- även ställen för inträde av regulatoriska proteiner som främjar transkription, men som är belägna på något, ibland signifikant, avstånd från den kodande sekvensen, och ljuddämpare- sekvenser som interfererar med transkription etc. Ibland finns de över hundratals och tusentals nukleotider (på kromosomens skala är det inte så mycket), men de fungerar fortfarande som cis-faktorer (dvs i närheten), fysiskt belägna i närheten på grund av en viss DNA-packning. All denna ekonomi kom att betraktas som tillhörande en gen som kodar för något. Således, i molekylär genetik av eukaryoter en gen är en kodande region av DNA tillsammans med intilliggande regioner av DNA som påverkar dess transkription.
För en sådan plats 1957 föreslog S. Benzer en kvalificeringsperiod cistron, som också hade otur, eftersom denna term började beteckna endast den kodande regionen av DNA (den så kallade öppna läsramen), och ibland även regionen av DNA mellan promotorn och terminatorn, från vilken en enda RNA-molekyl läses . Du kommer ihåg att i prokaryoter, där molekylärgenetiska mekanismer började klargöras tidigare, är operonorganisationen av gener utbredd, när sekvenserna som kodar för flera polypeptidkedjor har gemensam reglering och läses som en del av ett enda mRNA. Detta tillåter inte att ovanstående definition av termen "gen" används. Å andra sidan är termen "cistron" också till liten användning här: definieras som en bit av DNA från vilket ett enstaka RNA läses, kommer det att inkludera regioner som kodar för flera olika proteiner, vilket å andra sidan var en gång kallad "den polycistroniska principen att organisera genetiskt material". Som ett resultat är användningen av termerna "gen" och "cistron" utan förklaring (åtminstone vilket rike vi talar om) för närvarande kantad av missförstånd.
Observera att i den molekylärbiologiska förståelsen visade sig genen vara uppdelad i delar - exoner, introner, operatorer, förstärkare, i slutändan - individuella nukleotider. Och den regulatoriska DNA-sekvensen, som sådan, förlorade rätten att kallas ett genom, eftersom den själv inte kodar för någonting. Men på grund av påverkan på gentranskription kan denna sekvens också påverka någon egenskap (d.v.s. fenotypen), som kommer att ärvas tillsammans med denna sekvens. Och det i sig kan separeras genom rekombination från den kodande sekvensen, speciellt om det är en fjärrförstärkare. Den reglerande sekvensen är med andra ord också en speciell ärftlig faktor, som dessutom har sin egen plats på kromosomen. Vissa regulatoriska sekvenser, såsom förstärkare, kan påverka transkriptionen av flera gener samtidigt, d.v.s. ta sin bestämda plats i det regulatoriska nätverket för att kontrollera organismens utveckling och funktion. Det finns alla tecken på en gen i förståelsen av klassisk genetik.
Denna motsättning mellan de klassiska och molekylärbiologiska koncepten för en gen, som uppstod vid en tidpunkt då det verkade som att alla klassiska gener är transkriberade DNA-regioner som kodar för ett protein eller RNA, har ännu inte övervunnits, vilket dock inte är särskilt viktigt, eftersom ordet "gen" inte har använts som en strikt term på länge. I samband med den snabba utvecklingen av molekylärbiologin vinner molekylärbiologin: en gen är en transkriberad bit av DNA tillsammans med dess reglerande DNA-sekvenser. Det klassiska konceptet: en gen är en ärftlig faktor (oavsett hur den fungerar, vad den är och vad den består av), var historiskt sett den första, varade i mer än ett halvt sekel och visade sig vara extremt fruktbar. Du måste vara medveten om denna motsägelse och lära dig att förstå vad som står på spel i sammanhanget.
I praktiken löses denna motsägelse på två sätt: antingen före användningen av ordet "gen" är dess betydelse preliminärt specificerad, eller så används den inte som en term. Ett exempel på det första fallet: i avsnittet "material och metoder" i en artikel som ägnas åt att räkna gener i genomet kommer det säkert att skrivas efter vilket kriterium genen bestämdes - till exempel räknades antalet öppna läsramar . I nästa artikel kommer de att skriva: vi analyserade uttrycket och visade att några av de hittade potentiella läsramarna aldrig transkriberas och, uppenbarligen, inte är gener, utan pseudogener. Ett exempel på den andra situationen: ett lokus studeras från vilket flera tusen proteiner tillverkas på grund av det faktum att det finns tre alternativa promotorer, tre alternativa terminatorer och ett dussin introner som är föremål för alternativ splitsning. Var finns genen och hur många gener finns det på det här stället? I det här fallet kommer ordet "gen" bara att nämnas i inledningen, som en synonym för ordet "lokus". Om vi tar en fras som innehåller ordet "gen" från en populationsgenetisk kontext och infogar den i ett molekylärbiologiskt sammanhang, då får vi en förlust av betydelse.
Olika varianter av samma gen, i vilken mening som helst, betecknas med termen alleler... I denna form föreslogs termen av V. Johansen 1926, på grundval av termen "allelomorft par" som introducerades av W. Batson 1902). Begreppet "allel" dök upp när ingenting var känt om DNA:s struktur, och det introducerades just som en alternativ variant av genen. Detta koncept är särskilt viktigt för diploida organismer, som tar emot samma uppsättning gener från fadern och modern och som ett resultat av dem finns var och en av dem i genomet i två kopior, som kan vara identiska eller olika, men inte till sådana en omfattning att man inte kan säga att detta är "En och samma gen". Dessa två kopior fick namnet alleler.
Det är roligt, men när det gäller termen "allel" finns det ingen entydig lösning och en så enkel fråga som det grammatiska könet för detta ord på ryska. Moskva, liksom Kiev och Novosibirsk skolor, tror att allelen är maskulin, Leningrad (S:t Petersburg) - att den är feminin. Du kan se att även de två rekommenderade läroböckerna använder detta ord på olika sätt.
Ursprungligen introducerades termen "alleler" för att beteckna varianter av en gen som är ansvarig för en viss egenskap som är associerad med tillståndet för den egenskapen. Det visade sig dock att samma egenskap kan påverkas på samma sätt av gener oberoende av varandra. Detta väcker problemet med att skilja på alleler av samma eller olika gener. Lyckligtvis blev det klart ännu tidigare att gener finns i en strikt definierad sekvens i linjära strukturer - som det visade sig, i kromosomer - så att varje gen intar en strikt definierad plats på en av kromosomerna. Därför kunde varje gen identifieras inte bara genom dess effekt på egenskapen, utan också genom dess plats på en viss kromosom. Det visar sig att varje plats på kromosomen är ansvarig för någon egenskap ställe- upptagen av en av allelerna - individuella genvarianter. Den diploida kärnan innehåller två alleler av varje lokus, erhållna från modern och fadern, olika eller lika. Lokus kan definieras som position på en kromosom som hålls av en viss ärftlig faktor, a allel- hur en variant av en viss ärftlig faktor, och eftersom specificiteten hos den ärftliga faktorn ges precis av lokuset, men det är allelen en variant av en ärftlig faktor som ligger på ett visst ställe... Uppenbarligen ges denna definition från klassisk genetiks synvinkel. I det här fallet är det bättre att säga "lokus på kromosomen." och inte ett "kromosomlokus", för i det andra fallet kan intrycket skapas att kromosomen endast är sammansatt av sådana loci som har en genetisk betydelse. Även om en gen i klassisk mening verkligen motsvarar en viss bit av kromosom-DNA, och även om mycket ofta inget kodande DNA-regioner kan påverka något åtminstone indirekt (till exempel kan närvaron av ett upprepat block bidra till kromatinkomprimering och därmed påverka intensiteten av transkription av kodande segment DNA beläget även på ett avsevärt avstånd från det), men det finns säkert utökade sektioner av DNA som inte har något genetiskt innehåll, det vill säga de påverkar ingenting och är inte gener i någon mening .
Men termerna "lokus" och "allel" har också roliga, vidsträckta betydelser. Om vi studerar själva DNA-sekvensen, som i det här fallet är både vår egenskap och vårt genom, eftersom den bokstavligen kodar för sig själv, kan vi kalla vilken del av den som på något sätt kan kännas igen som ett lokus, och en variant av det som en allel. Till exempel innehåller genomet de så kallade "mikrosatelliterna" - en sekvens av mycket korta, två eller tre bokstäver, tandem (som ligger efter varandra) upprepas. Antalet dessa upprepningar ändras mycket enkelt på grund av mekanismer som är förknippade med replikationsglidning eller felaktig rekombination. Egentligen är de på grund av dessa mekanismer "påslagna" i arvsmassan, medan de inte har någon egen funktion och de är inte gener i molekylär mening. På grund av sin höga variabilitet gillar mikrosatelliter att studera evolutionär genetik - eftersom antalet kopior av upprepningar kan bedömas med en viss grad av säkerhet om förhållandet. Så i det här fallet är det också vanligt att prata om alleler, vilket med detta ord betecknar sekvenser av mikrosatelliter av olika längd (det vill säga med ett annat antal kopior av upprepningar).
Det visade sig att ordet "gen" i klassisk genetik helt kan överges. Det finns ett lokus - en plats på kromosomen, som alltid är upptagen av en av allelerna. Förhållandet mellan ett lokus och en allel är detsamma som förhållandet mellan en variabel och dess värde. Dessutom, i enlighet med den klassiska definitionen, är både ett lokus en gen (som ett generiskt begrepp) och en allel är en gen (som ett individuellt begrepp). Man kan ofta höra "de här generna är inte alleliska mot varandra", det vill säga de talar om alleliska och icke-alleliska gener, det vill säga om alleler av ett lokus och alleler av olika loci. Inom genetikens praktik har en inte särskilt strikt tradition etablerats att använda ordet "gen" som synonym för ordet "locus", och sådana exempel kommer också att finnas i vår text.
Men det finns situationer där ordet "gen" är svårt att undvika. Till exempel behandlade de ärtor med röda blommor med en kemisk mutagen och fick ärtor med vita blommor. Det visade sig att egenskapen "blomfärg" ärvs som bestäms av ett lokus - i sådana fall är det vanligt att tala om monogen attribut (även om den icke-existerande termen "monolokal" skulle vara mer korrekt). Men ärtor med vita blommor är redan kända och denna egenskap bestäms av en allel av ett välkänt lokus. Frågan är om vi fick samma allel av samma lokus eller en annan (på DNA-sekvensnivå) allel av samma lokus, vilket dock också leder till vita färger? Eller en allel av ett nytt, tidigare okänt lokus - som kan sägas för ett helt annat stadium av pigmentsyntes? Tills detta är fastställt får vi säga löst: "Vi fick genen för vitblommiga blommor." Förresten beskrivs en verklig situation från vårt laboratoriums liv - vi fick en gen som bestämmer vitblommigheten, som visade sig vara allelisk till ett inte allmänt känt lokus som är ansvarigt för blommans antocyanfärg a, och det föga kända stället a2 .
Termerna locus och allel kan också appliceras på en gen i molekylärgenetisk mening - nämligen på en specifik nukleotidsekvens. Här sammanfaller betydelsen av termerna "locus" och "gen", och allelen kommer att betyda den specifika nukleotidsekvensen för en given gen... Men inom ramen för molekylär genetik uppstår behovet av dessa termer inte så ofta, eftersom molekylärbiologiska hänsyn vanligtvis abstraheras från förekomsten i en diploid organism av en andra sådan gen, med en identisk eller något annorlunda sekvens, i en homolog kromosom.
Du känner säkert till från molekylärbiologin om existensen multigena familjer: när det finns flera gener i arvsmassan i molekylär mening, som kodar för en proteinprodukt av samma typ - samma enzym, till exempel. Dessutom kan de skilja sig något i den primära strukturen: både DNA och proteinprodukt, såväl som vissa fysikalisk-kemiska egenskaper hos proteinprodukten - intensiteten av molekylär funktion, såväl som egenskaperna för uttryck - det vill säga platsen, tiden och syntesens intensitet. Samma ärta har sju gener (i molekylär mening) av histon H1, var och en av dem kodar för en speciell variant av molekylen, varav en endast finns i aktivt delande celler och försvinner från kromatinet hos celler som har fullbordat delning. Vilken sekvens som helst av någon av dessa gener kommer att vara en variant av histon H1-genen. Men inom samma genom upptar dessa sju gener olika loci, så bara olika varianter av ett visst locus kommer att vara alleler. Du bör vara bekant med konceptet homologi- likhet baserad på gemensamt ursprung, och homologer- föremål med sådana likheter. Inom molekylär genetik särskiljs två typer av genhomologi. Homologa, men icke-alleliska gener i samma haploida genom, som upptar olika loci, kallas paraloger(av grekiskan "par" - om, nära). Individuella varianter av samma lokus i olika individer kallas ortologer(från grekiskan "orto" - direkt, tvärtom; kom ihåg orto-paret isomerer i organiskt material). Ortologer är i huvudsak alleler. Begreppet "ortolog" används dock vanligtvis av molekylärbiologer när de studerar gener från olika arter - i de fall där det entydigt kan fastställas att de har samma lokus, medan termen "allel" endast tillämpas på en genvariant i samma art, eller i närbesläktade arter som ändå är kapabla att föröka sig (till exempel vete och dess vilda släktingar). En allel är alltså just ett genetiskt begrepp, de talar om alleler när de i princip kan delta i korsning.
Låt oss ställa oss en fråga - var kom paralogerna ifrån? Det är logiskt och korrekt att anta att de uppstod som ett resultat av genduplicering - det vill säga sällsynta fall av gen-"multiplikation" i genomet. Naturligtvis inträffar varje sådan händelse, oavsett hur sällsynt, inom en enda art. Som ett resultat har vi en situation där vissa individer av samma art har två loci i sitt genom som är identiska i sin primära struktur (med tiden kan det ackumulera skillnader), medan andra bara har en. Antag att två kopior av en multiplicerad gen är placerade sida vid sida, så att båda nya loci ligger på samma plats som en gammal. Och så börjar de samla på sig skillnader. Var och vilka är allelerna här? Vi har övervägt situationen när begreppet "allel" misslyckas, och det är mycket bra, eftersom vi på detta sätt har spårat gränsen för dess tillämplighet.
Förresten, en oväntat icke-trivial fråga - vad är olika och identiska alleler. I de tidiga stadierna av utvecklingen av genetik kändes alleler endast igen av fenotyp, och endast de som leder till olika fenotyper ansågs vara olika alleler. Oftast fanns det två alleler - normala och defekta (mutant), så i de tidiga stadierna av utvecklingen av genetik var teorin om närvaro-frånvaro (av en viss funktion) populär. Men med utvecklingen av genetik blev fler och fler fall kända när samma egenskap har flera ärftliga varianter, vilket i slutändan ledde till uppkomsten berömd aforism Thomas Morgan: "En närvaro kan inte motsvara flera frånvaro." Och när det gäller kvantitativa egenskaper som bestäms av många gener samtidigt, finns det ingen speciell fenotypisk manifestation av en enskild allel alls. Som ett resultat avgjorde vi det faktum att allelerna började anses avsiktligt olika, om de i detta experiment inte ärvdes från samma individ, det vill säga de var inte identiska till sitt ursprung, eller en sådan identitet fastställdes inte. Till exempel fångar vi i naturen hundra till synes helt identiska individer för att studera de små nyanserna av den fenotypiska manifestationen av en gen, vi korsar dem med speciella testlinjer, vi översätter den studerade genen som erhålls från dem till en identisk genbakgrund, vi mäter den egenskap som är intressant för oss - och samtidigt tror vi att hundra olika (efter ursprung) normala (!) alleler deltar i experimentet (alla är hämtade från naturen från livsdugliga individer).
Du förstår att när det blev möjligt att dechiffrera den primära strukturen för generna som studeras, upphörde frågan om allelens identitet att vara teoretisk och reducerades till identiteten för deras primära struktur (nukleotidsekvens). Om det finns minst en substitution är allelerna olika, om inte är de lika, eftersom de är helt identiska molekyler. Med hänsyn till möjligheten av ackumulering av nukleotidsubstitutioner, av vilka många inte påverkar funktionen av lokuset, skiljer sig i praktiken detta tillvägagångssätt lite från a priori, eftersom allaler som oberoende erhållits från olika individer är olika. Men hastigheten för förekomsten av substitutioner varierar mycket från plats till locus - till exempel observerade vi i vissa loci en identisk nukleotidsekvens även i alleler erhållna från olika underarter av ärter (vilda och odlade).
Låt oss beröra sådana slappa, populära termer som "vildtypsalleler", "mutantalleler" och "nollalleler". Den tidigare nämnda "närvaro-frånvaro-teorin" är ganska tillämplig i många fall. Låt oss ta samma ärter som exempel. Ärtblommor har ett pigment - antocyanin, som färgar dem rosa-röda (lila). Om något av proteinerna som är involverade i den biokemiska kedjan av antocyaninsyntes är defekt eller inte, syntetiseras inte antocyanin och blommorna förblir vita. Låt oss säga att det finns ett lokus i en viss kromosom, låt oss beteckna det a, som innehåller DNA-sekvensen som kodar för ett av dessa proteiner. Vanligtvis talar de mindre strikt, men enklare - i en viss kromosom finns en gen a, som kodar för ett av dessa proteiner (ärter har verkligen en sådan gen med denna beteckning och kodar för ett regulatoriskt protein som binder till DNA, och inte ett enzym som är involverat i syntesen av antocyanin). Låt den här genen ha två alleler, låt oss beteckna dem A och a... Allel A kodar för ett normalt funktionellt protein. Allel a kodar inte för ett funktionellt protein. Hur är detta möjligt - vi kommer att prata senare, det är viktigt för oss nu när denna allel helt enkelt "inte fungerar" - den fyller inte sin molekylära funktion, även om den är okänd för oss. I sådana fall kallas den normala allelen vild typ/ I exemplet med ärter är denna term dubbelt korrekt. Ärter är både odlade och vilda (representanter för samma art fortsätter att existera i det vilda). Och alla vilda ärtor har lila blommor, och odlade ärtor har både lila och vita, men i grönsaks- och spannmålsvarianter av europeiskt urval dominerar vita. För en allel som inte kan bilda en funktionell proteinprodukt används ofta också termen noll allel.
Det finns tillfällen då begreppet "vildtyp" eller "nollallel" inte är tillämpligt. Till exempel i en tvåpunktsnyckelpiga Adalia bipunctata det finns två former - röd med svarta fläckar och svart med röd. (Förresten, detta är ett av de klassiska objekten för populationsgenetik, introducerat i denna vetenskap av Timofeev-Resovsky.) Båda är representerade i den europeiska delen av Ryssland, ingen är bättre än den andra (i Novosibirsk är det dock bara andra hittas). Ingen av dem kan kallas vild i motsats till den andra. Det är dock möjligt att en av dessa alleler är associerad med förlusten av den molekylära funktionen hos proteinprodukten från detta lokus, vilket, liksom andra gener för individuell utveckling, förmodligen är en faktor som påverkar uttrycket av andra gener.
Dessutom finns det en term populär inom genetik - mutation... Historiskt sett introducerades begreppet av Hugo De Vries i en betydelse som ligger nära den som nu används i skräckfilmer – en plötslig förändring i ärftliga böjelser, vilket leder till en radikal förändring av fenotypen. De Vries arbetade med en av typerna av primula ( Oenothera), där, som det visade sig senare, en extremt originell cytogenetik: på grund av flera kromosomala omarrangemang ärvs hela genomet som en allel. Ordet har dock blivit en mycket använd term, och inte bara i Hollywood. Sergei Sergeevich Chetverikov, en av grundarna av populationsgenetik, använde termen "genovariation", vilket är mer korrekt, men slog inte rot (även om Chetverikov var en av de inhemska genetiker som hade en betydande inverkan på världens genetik, som faktiskt grundade befolkningen genetik). För närvarande under mutationär förstådd någon förändring i DNA:s primära struktur- från ersättning av en nukleotid till förlust av stora delar av kromosomerna. Jag vill uppmärksamma er på att ordet "mutation" betyder själva förändringens händelse. Men i en lös men seg genetisk praxis används samma ord "mutation" ofta på dess resultat, det vill säga på den allel som har uppstått till följd av mutationen. De säger: "Experimentet involverar Drosophila - bärare av mutationen vit". Ingen registrerade själva mutationshändelsen, vilket ledde till uppkomsten av denna klassiska mutation - förresten, den är förknippad med införandet av ett mobilt genetiskt element i enzymgenen kopia, som rör sig extremt sällan - men alla fortsätter att säga "mutation" istället för "mutant allel". Det är underförstått att en mutation en gång inträffade som förstörde den normala allelen, vilket resulterade i en mutant. Det är lätt att förstå att "mutantallelen" också är motsatsen till uttrycket "vildtypsallel", men bredare än "nollallelen", eftersom den tillåter olika avvikelser från vildtypsallelen, vilket leder till en fullständig förlust av molekylär funktion (de samma " flera frånvaro "!), och aldrig ledande.
Det finns en annan mycket otäck terminologisk situation som vissa av er kommer att behöva möta i mänsklig genetik. Som vi kommer att se senare avvek mänsklig genetik i allmänhet terminologiskt ganska starkt från allmän genetik. Anledningen är att å ena sidan hör detta specialiserade vetenskapsområde till både biologi och medicin och är rent institutionellt isolerat från all annan genetik, och i denna mening bryggs det i sin egen saft. Å andra sidan är detta område på grund av sin praktiska betydelse mycket stort i volym - antalet forskare och deras forskning, tidskrifter, artiklar - vilket gör dess interna traditioner motståndskraftiga mot yttre påverkan, bland annat från "moderns" allmänna genetik. Modern mänsklig genetik har avancerat så långt att den i många fall har förverkligat genetikers urgamla dröm, nämligen att den kunde associera vissa egenskaper (inklusive patologiska) med upptäckten av vissa nukleotider i specifika positioner av specifika gener. Men det var här den irriterande terminologiska substitutionen ägde rum. När vi jämför många alleler i förhållande till DNA:s primära struktur, visar det sig att i vissa positioner finns alltid samma specifika nukleotid, och nukleotidsubstitutioner är möjliga i vissa positioner. (Det finns en misstanke om att vilken nukleotid som helst i vilken position som helst kan hittas i arvsmassan hos alla människor av mänskligheten, vilket väcker en rolig filosofisk fråga - vad är det mänskliga genomet). De var korrekt namngivna polymorfa positioner- och faktiskt, varje sådan position uppvisar alternativ variabilitet - det vill säga polymorfism - med avseende på vilken av de fyra nukleotiderna den kan vara upptagen med. Men här, på något sätt, var det ett utbyte av begrepp. "Polymorfism" började kalla en specifik nukleotid vid en specifik polymorf position (vad som borde kallas en "morf"). De började säga ungefär så här: ”Vi har sekvenserat en sådan och en gen i så många människor och hittat tolv polymorfier, två i positioner som och sådana, sex i sådana och sådana, och fyra i sådana och sådana. Två av polymorfismerna i sådan och sådan position visade ett signifikant samband med sådant och sådant syndrom." Troligtvis ägde en sådan substitution rum på nivån av laboratorieslang, som finns i alla vetenskapliga arbeten och består i att förenkla terminologin, som ofta är analfabet. Studenter som kommer till laboratoriet missar ibland slang för terminologi och börjar använda den på fullt allvar. Någon gång händer det att både artikelförfattaren och recensenterna i en vetenskaplig tidskrift är vana vid samma slang, då tränger det in i den vetenskapliga pressen och med viss sannolikhet fixeras det. (Bilden är förresten mer än bekant från populationsgenetik och kopierar helt artbildningsprocessen - när de av misstag uppstår i en isolerad population, sammanfaller i olika kön och anomalier i igenkänningssystemet för lämpliga sexuella partners registreras, vilket blir normen i en ny art och leder till att den inte korsar sig med den gamla .) Förutom den etymologiska motsägelsen (en enda morf kallas ett ord som indikerar att det finns många morfer) och dålig smak, har en sådan substitution också konsekvens att forskare som använder denna jargong har berövat sig själva termen "polymorfism" i dess korrekta betydelse. Och när det blir nödvändigt att uttrycka motsvarande begrepp (som inte har gått någonstans), istället för en entydig term, måste de tillgripa utförliga beskrivningar. Till exempel, i situationer där termen "balanserad polymorfism" existerar - när en av morferna har en fördel under vissa förhållanden, den andra i andra, så att de samexisterar och inte ersätter varandra - måste de tillgripa långa beskrivningar som denna varje gång.
När det gäller att introducera dig till traditionell och inte alltid konsekvent genetisk terminologi, bör en ganska underhållande term nämnas markör... Denna term introducerades för loci som inte är viktiga för oss själva, utan i den mån de markerar en viss region av kromosomen. Uppkomsten av en sådan term var förknippad med en lång tidsperiod då inte särskilt många genetiska loci var kända. Det behövdes i situationer där det var nödvändigt att sätta en nyupptäckt gen på spel, eller, paradoxalt nog, att arbeta med ännu inte upptäckta gener. Till exempel var naturen hos gener som kontrollerar ekonomiskt värdefulla kvantitativa egenskaper hos växter och djur helt okänd under lång tid, och till och med nu är lite känt om dem. Samtidigt rådde det ingen tvekan om att dessa gener finns och finns på kromosomerna. Genom att manipulera kända loki - markörer - var det möjligt att identifiera regioner av kromosomer med vilka vissa effekter på kvantitativa egenskaper är associerade, och använda dem i avelsarbete. Till en början var dessa främst "synliga markörer" - loci där det fanns alleler med en synlig effekt. Men i framtiden utvecklades detta tillvägagångssätt på allvar på grund av involveringen i genetisk analys av biokemiska egenskaper (vanligtvis inte heller funktionellt relaterade till ekonomiskt värdefulla egenskaper), och senare på grund av uppkomsten av möjligheten att arbeta med DNA:ts polymorfism av själva kromosomerna. Detta ledde till uppkomsten av begreppet "molekylär markör". Således är termen "markör" bara en synonym för termen "lokus", men det understryker att detta lokus är av intresse för oss inte som sådant, utan bara som ett landmärke på kromosomen. Däremot vande man sig vid termen så mycket att den började användas i de fall då lokuset är ett direkt studerat objekt. Paradoxalt nog, i studier av molekylär fylogeni, kallas de analyserade sekvenserna i sig också ofta som markörer. Här skulle det kunna antydas att de bara är landmärken i tiden och nukleotidsubstitutioner i dem markerar evolutionära händelser, som naturligtvis inte är begränsade till förändringar endast i de analyserade sekvenserna.
Gener (mer exakt, loci) betecknas vanligtvis med förkortningar som består av latinska bokstäver, såväl som siffror. Men bakom dessa beteckningar finns de fullständiga namnen på generna, latin eller, oftare, engelska. Både fullständiga namn och genförkortningar skrivs alltid i kursiv stil. För gener med synligt uttryck är detta vanligtvis ordet som beskriver den muterade fenotypen: w – vit(vita ögon av en fluga), y – gul(gul kropp i en fluga), a – antocyanin hämning(nära ärtor), op – ägglossning pistilloida(nära ärtor), bth – bitorax- inte ett särskilt bra namn för Drosophila-mutationen, där ett andra par vingar dyker upp på metathorax (metathorax) (som på mesothorax) - men det skrivs som om bröstkorgen hade fördubblats. Det finns till och med en mutation av Drosophila med det officiella namnet fushi tarazu(shorthand symbol - ftz) - Japanska. Roliga amerikaner namngav en av generna mödrar mot dekapentaplegi, i analogi med organisationer som "mödrar mot kriget i Irak" - kvinnliga Drosophila-bärare av denna mutation kommer inte att överleva ättlingarna till genen dekapentaplegi... Förkortningen för denna gen låter inte sämre: galen... Ibland, och inte i de mest populära objekten, är det officiella namnet på genen och dess förkortade beteckning inte relaterade till varandra: en mutation som förvandlar antennerna på ärter till blad har beteckningen tl(från tendorless), och namnet är nyckelbenet... Om en gen är känd genom sin molekylära produkt (protein eller RNA), kommer denna gen själv att döpas efter sin produkt: mtTrnK – mitokondrie transport RNA för lysin, RbcL – ribulos bifosfat karboxylas stor underenhet... Det är viktigt att varje art har en helt oberoende officiell nomenklatur av genetiska symboler, vilket leder till vissa svårigheter för närvarande, när antalet objekt med utvecklad privat genetik har ökat, och antalet objekt där gener undersöks inte av genetiska experiment, men genom direkt avläsning av DNA-sekvenser – växer det som en lavin (exempelvis är projektet "10 000 ryggradsdjursgenom" redan igång).
Genetik började med fall där endast två alleler var kända vid varje lokus och man kunde särskilja dem genom att skriva med stor eller liten bokstav, vars början lades av Mendel. Den stora bokstaven användes för den dominanta allelen (du vet vad detta betyder från skolan, senare kommer vi att beröra fenomenet dominans mer i detalj) - som regel är detta en vildtypsallel; som vi skulle säga nu - en allel med normal, inte nedsatt molekylär funktion. Samtidigt betecknades lokuset med en liten bokstav, det vill säga dess beteckning sammanföll med den för den recessiva, det vill säga mutant, icke-funktionell allel, eftersom det var genom existensen av en sådan allel som forskarna först lärde sig om förekomsten av ett lokus. I sällsynta fall, när en mutant allel visade sig vara dominant, betecknades både den och själva lokuset med stor bokstav.
När, och mycket snart, det stod klart att det finns många alleler i ett lokus (nu vet vi att det finns många av dem) introducerades beteckningarna på alleler, som skrivs i en upphöjd efter beteckningen av lokus. "+"-symbolen används ofta som ett sådant index för vildtypsallelen, ibland saknas indexet. Låt oss säga vid det allra första kända Drosophila-lokuset vit (w) vildtypsallelen betecknas w+ , allelen ansvarig för vita ögon - w, och ansvarig för aprikos - wa (fullständigt namn - vitapricot).
Jag uppmärksammar er på det faktum att för traditionella genetiska objekt med utvecklad privat genetik, finns fortfarande olika traditioner samexistera när det gäller att skriva beteckningarna för loci och deras alleler. Hittills har jag hittat tre av dem:
Lokus med synlig manifestation skrivs med liten eller stor bokstav, beroende på om lokuset beskrivs enligt den recessiva eller dominanta allelen med avseende på vildtypen; och med stor bokstav om platsen är känd genom molekylär funktion. Samtidigt, för loci med synlig manifestation och dominans, bevaras traditionen att skriva recessiva alleler med liten bokstav, och dominanta alleler med stor bokstav. Detta är den genetiska nomenklaturen, till exempel i ärter och möss. Till exempel platsen för ärten a, ansvarig för färgen på blommor har alleler A och a.
Som i det föregående fallet, men de stora och små bokstäverna i beteckningen av lokuset och dess alleler är stelt fast. Detta system används i Drosophila. Här notationen w och W tillhör helt andra platser - vit och Rynkig... Vildtypsallelen indikeras alltid här med suffixet "+". (Konstigt nog misstänker genetiker som sysslar med fruktflugor och möss, vana vid det system som antagits av deras föremål, vanligtvis inte ens att det finns ett annat system för att namnge loci.)
Alla bokstäver i beteckningen av loci är alltid stora. Ett sådant system används nu i mänsklig genetik, och det har antagits ganska nyligen.
Samma allelbeteckningar används för att beteckna fenotyper, men alltid utan kursiv stil. Så, om du beskriver resultaten av ett experiment där du observerade så många ärtplantor med lila blommor och så många - med vita blommor, och du vet att vitblommighet i experimentet är associerad med lokuset a, då kommer du att beteckna lilablommiga och vitblommiga växter med bokstäverna A och a i frekvenstabellen, även om du inte känner till deras genotyp. Detsamma görs om man bestämmer förekomsten av elektroforetiska varianter av något isoenzym: där är fenotypens överensstämmelse med genotypen större, men den är inte alltid entydig.
1.4. Begreppen "homozygot", "heterozygot", "hemizygot".
I varje diploid organism är varje kromosom (förutom kön) representerad i två exemplar - homologer från fadern respektive modern. Var och en av homologerna har samma uppsättning loci, och i var och en av homologerna är varje locus upptagen av någon allel. Därför bär varje diploid organism två alleler av varje lokus. När genotypen registreras skrivs beteckningarna på två alleler som finns i de platser som är av intresse för oss i följd, till exempel om det finns a har ärtalleler A och a tre genotyper är möjliga: A A, A a och a a.
Om i båda homologerna platsen representeras av samma allel, så sägs det att individen homozygot vid denna allel, eller vid denna locus. Dessutom, när de säger att det är homozygot för ett lokus, ligger tonvikten på det faktum att det i båda homologerna inte finns några skillnader i det, när de säger att det är homozygot för en allel, ligger betoningen på vilken allel. Om i båda homologerna platsen representeras av olika alleler, då individen heterozygot på denna plats. För enkelhetens skull kallas en homozygot respektive heterozygot individ. homozygot och heterozygot... Med tanke på vad som sades ovan om identiteten / skillnaderna mellan alleler, är sanna homozygoter i naturen inte särskilt vanliga. Men i ett visst experiment bryr sig ingen om att distrahera från skillnaderna som inte detekteras i detta experiment eller inte kan identifieras, och att betrakta som homozygoter individer där båda kopiorna av lokuset har en identisk fenotypisk manifestation. I studier där besläktade individer är inblandade finns det ökända homozygoter - individer där båda allelerna i ett lokus är identiska till sitt ursprung. I sådana studier används ofta begreppet genomsnittlig heterozygositet- andelen heterozygota loci bland alla loci.
Låt oss lägga till ytterligare en term hemizygot– Det här är en individ där inte två, utan bara en allel finns. Tja, till exempel, du vet säkert att män bara har en kön X-kromosom, och den andra könskromosomen, Y-kromosomen, är inte homolog med den (förutom för små områden), eftersom den inte saknar de flesta regioner som är mättade med genetisk information. Därför har alleler från de regioner av X-kromosomen som inte är representerade i Y-kromosomen inte homologer i kärnan, det vill säga de finns i hemizygoten. Ibland förlorar en kromosom en del av sitt fragment tillsammans med generna i den (eller en gen). I detta fall uppträder allelerna för dessa gener i den homologa kromosomen också i hemizygoten. Men i ett genetiskt experiment vet vi ofta inte vad som hände i kromosomerna, och vi bedömer gener endast efter deras fenotyp. I det här fallet kan frånvaron av en gen inte skilja sig från dess "nedbrytning" - förlusten av dess funktion. Och även om vi inte vet, ska vi säga, den molekylära bakgrunden, men på något sätt drar vi slutsatsen att den molekylära funktionen är förlorad, kommer vi bara att prata om en allel, eller "nollallel".
Att skilja mellan homozygot, heterozygot och hemizygot är viktigt i diploida organismer, eftersom dos motsvarande allel i arvsmassan i det här fallet skiljer sig med hälften (till exempel vid ett lokus i X-kromosomen, två kopior per genom hos kvinnor och en hos män), vilket kan vara viktigt. Molekylär genetik distraheras vanligtvis från homozygositeten/heterozygositeten hos dess föremål. Begreppet används dock ofta här gendoser, det vill säga antalet alleler med intakt molekylär funktion i genomet - vanligtvis varierar det från 0 till 2, men kan ökas genom genmodifiering, det vill säga artificiellt införa ytterligare kopior i genomet.
När det gäller haploida organismer är det vanligt att säga att de i allmänhet har alla alleler för alla gener i hemizygoten. Vilka haploida organismer har vi? Prokaryoter, lägre svampar och ascomyceter, gametofyter av växter. Låt oss notera en detalj - haploider är inte de som har strikt ett haploid genom i en cell. De flesta bakterieceller har flera nukleoider som ännu inte har lyckats dela sig - men de är alla identiska (upp till de novo-mutationer). Hos lägre svampar är hyfer ofta inte uppdelade i enskilda celler alls. Det är viktigt att en haploid organism har en enda variant av det haploida genomet i sina celler. Slutligen, vissa djur - som Hymenoptera - har ett haploid kön - du vet förmodligen att bidrönare är haploida. Samtidigt, i somatiska celler, fördubblas uppsättningen kromosomer, varifrån de inte upphör att vara haploider. Mitokondrier och plastider ärvs ofta endast från modern, därför är celler hemizygota för gener i dessa organellers genom. Men i många växter har plastider ibland biparental nedärvning, i andra händer detta ibland, och det är extremt sällsynt att paternala mitokondrier tränger in i zygoten. I sådana fall får avkomman från båda föräldrarna en viss varierande andel av dessa organeller, inte nödvändigtvis lika med 1/2. I sådana fall är det vanligt att prata om heteroplasmi.
05.05.2015 13.10.2015
I modern genetisk vetenskap används termerna flitigt - alleler, loci, markörer. Under tiden beror barnets öde ofta på förståelsen av så snäva termer, eftersom diagnosen faderskap är direkt relaterad till dessa begrepp.
Människans genetiska egenskap
Alla har sin egen unika uppsättning gener som de får från sina föräldrar. Som ett resultat av kombinationen av helheten av föräldragener erhålls en helt ny, unik organism av barnet med sin egen uppsättning gener.
Inom genetisk vetenskap har moderna forskare för diagnostik identifierat vissa områden av mänskliga gener som har den största variationen - loci (deras andra namn är DNA-markörer).
Alla dessa loci har många genetiska variationer - alleler (alleliska varianter), vars sammansättning är helt unik och rent individuell för varje person. Till exempel har ett hårfärgslokus två möjliga alleler - mörk eller ljus. Varje markör har sitt eget individuella antal alleler. Vissa markörer innehåller 7-8, andra fler än 20. Kombinationen av alleler på alla studerade loci kallas DNA-profilen för en viss person.
Det är variationen hos dessa genersektioner som gör det möjligt att utföra en genetisk undersökning av relationen mellan människor, eftersom ett barn från sina föräldrar får en av loci från varje förälder.
Principen för genetisk undersökning
Det genetiska förfarandet för att fastställa biologiskt faderskap hjälper till att fastställa om mannen som anser sig vara förälder till ett visst barn är en riktig pappa eller om detta faktum är uteslutet. För undersökning av biologiskt faderskap jämför analysen läget mellan föräldrarna och deras barn.
Moderna metoder för DNA-analys kan samtidigt studera det mänskliga genomet på flera loci samtidigt. Till exempel ingår en undersökning av 16 markörer samtidigt i en standardiserad genstudie. Men idag, i moderna laboratorier, görs expertforskning på nästan 40 loci.
Analyserna utförs med hjälp av moderna genanalysatorer - sekvenserare. Vid utgången får forskaren ett elektroforetogram, som indikerar loci och alleler för det analyserade provet. Således, som ett resultat av DNA-analys, analyseras närvaron av vissa alleler i det analyserade DNA-provet.
Bestämma sannolikheten för relation
För att bestämma graden av släktskap genomgår DNA-profilerna som erhölls för en specifik deltagare i undersökningen statistisk bearbetning, baserat på resultaten av vilka experten drar slutsatsen om procentandelen av sannolikheten för släktskap.
För att beräkna sambandsnivån jämför ett visst statistiskt program förekomsten av samma allelvarianter av alla studerade loci från de analyserade. Beräkningen görs mellan alla som deltar i analysen. Resultatet av beräkningen är fastställandet av det kombinerade faderskapsindexet. Den andra indikatorn är sannolikheten för faderskap. Det höga värdet av vart och ett av de fastställda värdena är bevis på den undersökta mannens biologiska faderskap. Som regel, för att beräkna förhållandets indikatorer, används en databas med allelfrekvenser som erhållits för befolkningen i Ryssland.
En positiv jämförelse av 16 olika, slumpmässigt utvalda DNA-markörer gör det enligt statistiken möjligt att fastställa sannolikheten för faderskap. Men om resultaten för alleler av 3 eller fler markörer av 16 inte stämmer överens, anses resultatet av undersökningen av biologiskt faderskap vara negativt.
Exakthet av undersökningsresultat
Flera faktorer påverkar noggrannheten av resultaten av en genundersökning:
antalet analyserade genetiska loci;
platsens natur.
Genetisk analys av så många loci som möjligt unika för en viss person gör det möjligt att mer exakt fastställa (eller, omvänt, att motbevisa) graden av sannolikhet för faderskap.
Således är den uppnådda graden av sannolikhet vid samtidig analys av upp till 40 olika loci upp till 99,9 % för att bekräfta sannolikheten för biologiskt faderskap, samt upp till 100 % om ett negativt resultat erhålls.
Bestämning av biologiskt faderskap med en sannolikhetsgrad på 100% är omöjligt på grund av den teoretiska möjligheten att det finns en man med samma uppsättning DNA-markörer som barnets far. Men vid en sannolikhetsnivå på 99,9 % anses undersökningen vara positiv och faderskapet bevisas.
Vilka DNA-källor är lämpliga för analys?
DNA-undersökning är en mycket känslig procedur som inte kräver stora mängder prov för DNA-extraktion. Tack vare moderna vetenskapliga framsteg kan genetisk undersökning för att fastställa sannolikheten för faderskap utföras med hjälp av både biologiskt material som erhållits från en specifik person (panna från munnen, hår, blod) och icke-biologiskt material, det vill säga bara i kontakt med en person (till exempel hans tandborste, klädesplagg, napp, köksredskap). Detta är möjligt på grund av det faktum att i alla mänskliga celler, oavsett ursprung, är DNA-molekylerna exakt lika, vilket gör det möjligt att jämföra DNA-prov som erhållits från patientens mun med ett prov från blod, eller från ett DNA-prov. fås från en tandborste eller kläder.
Nya framsteg när det gäller att fastställa faderskap
Utvecklingen av mikrochipsdiagnostik har blivit ett nytt ord i definitionen av faderskap. På grund av indikationen på ett mikrochip (en liten platta) av nästan alla mänskliga gener, kommer det inte att vara svårt att fastställa faderskap. Denna teknik liknar ett genetiskt pass. Genom att ta ett prov av blod eller fostervatten från fostret kommer det att vara möjligt att enkelt isolera DNA från det och hybridisera det till föräldrarnas mikrochips. Forskarna planerar att använda denna teknik för att identifiera ärftliga sjukdomar också.
Gen- strukturell och funktionell enhet för ärftlighet hos levande organismer. En gen är en bit av DNA som specificerar sekvensen för en viss polypeptid eller funktionellt RNA.
Peptider- en familj av ämnen, vars molekyler är uppbyggda av två eller flera aminosyrarester sammankopplade i en kedja med peptid (amid) bindningar -C (O) NH-. Vanligtvis avses peptider som består av aminosyror. Peptider kortare än cirka 10-20 aminosyrarester kan också hänvisas till som oligopeptider, för en längre sekvenslängd kallas de polypeptider.
Proteiner vanligtvis hänvisade till som polypeptider innehållande från cirka 50 aminosyrarester.
Genom- den totala mängden ärftligt material som finns i kroppens cell. Genomet innehåller den biologiska information som behövs för att bygga och underhålla en organism. De flesta genom, inklusive det mänskliga genomet och genomen från alla andra cellulära livsformer, är byggda från DNA, men vissa virus har genom från RNA. Hos människor (Homo sapiens) består genomet av 23 par kromosomer belägna i kärnan, samt mitokondrie-DNA. Tjugotvå autosomer, två könskromosomer X och Y och mänskligt mitokondrie-DNA innehåller tillsammans cirka 3,1 miljarder baspar.
Tillsammans med miljöfaktorer bestämmer arvsmassan fenotyp organism.
Genotyp- en uppsättning gener från en given organism, som kännetecknar en individ. Begreppet ”genotyp”, tillsammans med begreppen ”gen” och ”fenotyp”, introducerades av genetikern VL Johansen 1909 i hans arbete ”Elements of the exact doctrine of hereedity”. Vanligtvis talas om en genotyp i samband med en viss gen; hos polyploida individer betecknar det en kombination av alleler av en given gen. De flesta gener förekommer i en organisms fenotyp, men fenotypen och genotypen är olika på följande sätt:
- Enligt informationskällan (genotypen bestäms genom att studera en individs DNA, fenotypen registreras genom att observera organismens utseende)
- Genotypen motsvarar inte alltid samma fenotyp. Vissa gener förekommer i fenotypen endast under vissa förhållanden. Å andra sidan är vissa fenotyper, till exempel färgen på djurens päls, resultatet av interaktionen mellan flera gener beroende på typen av komplementaritet
Alleler- olika former av samma gen som ligger i samma regioner (loci) av homologa kromosomer och bestämmer alternativa varianter av utvecklingen av samma egenskap. I en diploid organism kan det finnas två identiska alleler av samma gen, i vilket fall organismen kallas homozygot, eller två olika, vilket leder till en heterozygot organism. Termen "allel" föreslogs också av V. Johansen (1909).
Ställe- i genetik betyder det platsen för en viss gen på den genetiska eller cytologiska kartan av en kromosom. En variant av DNA-sekvensen vid ett givet lokus kallas en allel. En ordnad lista över loci för alla genom kallas genetisk karta.
Genkartläggningär definitionen av ett lokus för en specifik biologisk egenskap.
Kromosomer- nukleoproteinstrukturer i kärnan i en eukaryot cell, i vilka det mesta av den ärftliga informationen är koncentrerad och som är avsedda för dess lagring, implementering och överföring. Kromosomer är tydligt urskiljbara i ett ljusmikroskop endast under perioden med mitotisk eller meiotisk celldelning. Uppsättningen av alla kromosomer i en cell, som kallas en karyotyp, är en artspecifik egenskap, som kännetecknas av en relativt låg nivå av individuell variabilitet.
Ursprungligen föreslogs termen att hänvisa till strukturer som finns i eukaryota celler, men under de senaste decennierna talar de alltmer om bakteriella eller virala kromosomer. Därför är en bredare definition definitionen av en kromosom som en struktur som innehåller nukleinsyra och vars funktion är att lagra, implementera och överföra ärftlig information. Eukaryota kromosomer är DNA-innehållande strukturer i kärnan, mitokondrierna och plastider. Kromosomer i prokaryoter är DNA-innehållande strukturer i en cell utan kärna.
Viruskromosomerär en DNA- eller RNA-molekyl i en kapsid.
Ställe (från latinsk locus - plats)
kromosomer, en linjär region av en kromosom som upptas av en gen. Med hjälp av genetiska och cytologiska metoder är det möjligt att bestämma lokaliseringen av en gen, det vill säga att fastställa i vilken kromosom en given gen finns, samt positionen för dess L. i förhållande till L. andra gener ligger i samma kromosom (se Genetiska kartor kromosomer). Som visas i vissa mikroorganismer finns gener som kontrollerar en specifik sekvens av biokemiska reaktioner i angränsande L., och L. är belägna i samma ordning som biosyntesreaktionerna fortskrider; denna regel har inte fastställts för högre organismer. Termen "L." i den genetiska litteraturen används det ibland som en synonym för termerna gen och cystron.
Stor sovjetisk uppslagsbok. - M .: Sovjetiskt uppslagsverk. 1969-1978 .
Se vad "Locus" är i andra ordböcker:
Lokus (s)- * locus (s) * locus (es) 1. Placering av en viss gen (dess specifika alleler) på kromosomen eller inom ett segment av genomiskt DNA. 2. Placeringen av en given mutation eller gen på den genetiska kartan. Används ofta istället för termerna "mutation" ... ... Genetik. encyklopedisk ordbok
- (lat. locus) platsen för lokalisering av en viss gen på den genetiska kartan av kromosomen ... Stor encyklopedisk ordbok
- (från lat. locus place), platsen för en viss gen (dess alleler) på genetisk. eller cytologiskt. kromosomkarta. Ibland termen "L." används omotiverat synonymt med termen "gen". (Källa: "Biological Encyclopedic Dictionary." Kap. ... ... Biologisk encyklopedisk ordbok
A, m. (... Ordbok med främmande ord i ryska språket
STÄLLE- (från lat. locus place), platsen för denna gen i kromosomen. Ekologisk encyklopedisk ordbok. Chisinau: Moldaviens huvudredaktion Sovjetiskt uppslagsverk... I.I. Morfar. 1989... Ekologisk ordbok
Ställe- placeringen av en specifik gen (dess alleler) på kromosomen ... Källa: METODISKA REKOMMENDATIONER PROGNOS, TIDIGT PREKLINISK DIAGNOSTIK OCH FÖREBYGGANDE AV INSULINBEROENDE DIABETES MELLITUS (N 15) (godkänd av kommitténs ordförande ... ordförande. .. Officiell terminologi
Substantiv, Antal synonymer: 1:a plats (170) ASIS Synonymordbok. V.N. Trishin. 2013 ... Synonym ordbok
ställe- Placering av den alleliska genen i kromosomen Ämnen inom bioteknik EN locus ... Teknisk översättarguide
Denna term har andra betydelser, se Locus (betydelser). En schematisk representation av en kromosom: (1) Kromatid, en av två identiska delar av en kromosom efter S-fasen. (2) Centromere, en plats där kromatider med ... Wikipedia
- (lat. locus), platsen för lokalisering av en viss gen på den genetiska kartan av kromosomen. * * * LOCUS LOCUS (lat. Locus), platsen för lokalisering av en viss gen på den genetiska kartan av kromosomen ... encyklopedisk ordbok
Lokus locus. Placeringen av en gen (eller dess specifika alleler) på kromosomkartan för en organism; ofta termen "L." olämpligt använd i stället för termen "gen"
Böcker
- Lokal för kontroll av ungdomsbrottslingar, Elena Smoleva. Uppsatsen diskuterar i detalj frågorna om diagnostik och korrigering av kontrollplatsen (nivån av subjektiv kontroll) för minderåriga. Särskild uppmärksamhet ägnas åt empiriska studier av nivån ...